



在Ubuntu下实现魔搭社区中的【Paraformer语音识别-中文-通用-16k-离线-large-onnx】
本文档只是为了记录本人第一次使用docker跑模型
默认已经在Ubuntu下安装好docker ,可以通过一下指令来查看是否已经安装成功docker
$ docker version
$ sudo docker version
1 环境搭建
如果是第一次使用这个模型,打开【Paraformer语音识别-中文-通用-16k-离线-large-onnx】 ,执行镜像启动和服务端启动两个部分。
执行镜像启动,在主目录下会出现文件夹 funasr-runtime-resources

而终端则会进入镜像所创建的容器当中

容器启动后,继续在终端继续执行服务端启动,启动成功后会出现如下输出
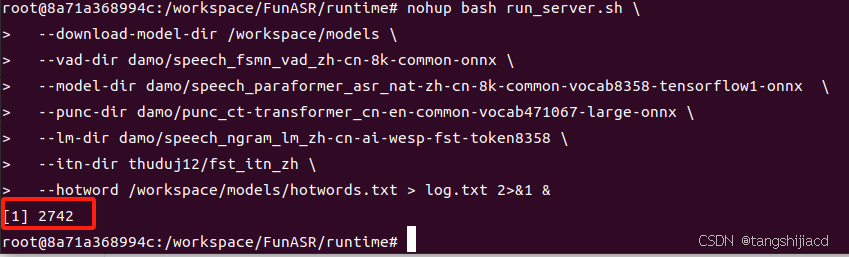
2 案例测试
继续在终端执行指令,获取案例测试包
$ wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz
此时,应该注意这里下载的是一个压缩文件,需要解压后才能对相关案例进行测试,否则会报错找不到文件,以下是解压指令
$ tar -zxvf funasr_samples.tar.gz
通过终端操作已经可以查看到需要测试的语音文件
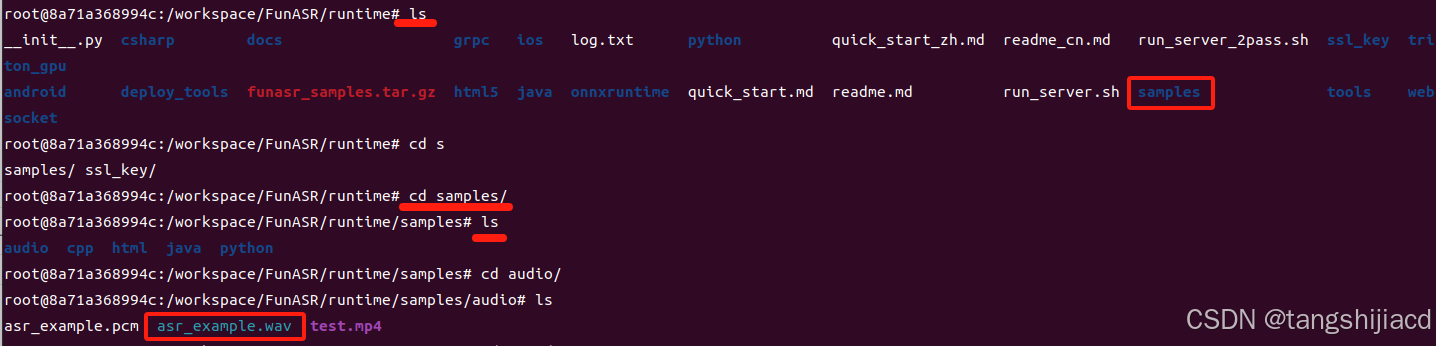
随后只需要找到对应的python执行文件,在该文件路径下执行python文件即可,该文件所处路径为:
/FunASR/runtime/python/websocket

随后执行代码如下指令,这里需要注意的是,执行之前需要找到对应的python文件所处的文件夹,并在该文件夹下执行对应的python文件。只需要注意在运行测试案例的时候需要注意一下语音文件asr_example.wav所处的文件路径。
$ python3 funasr_wss_client.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "../../samples/audio/asr_example.wav"
具体执行及测试结果如下所示:

最后可以通过 exit 退出容器
3 退出已创建的容器后再次进入容器
使用 docker ps 可以查看正在运行的容器,docker ps -a 可以查看所有已经创建好的容器

对于已经退出关闭的容器,若想要再次进入该容器,首先需要重启容器,然后再通过容器ID进入容器,具体执行命令如下:
$ docker restart 8a71a368994c #重启容器,语法为: docker restart <CONTAINER ID>
$ dockers attach 8a71a368994c #重连容器,语法为: docker attach <CONTAINER ID>

其他的 docker 使用方法可以查看 Docker容器使用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









