



 本文详细介绍了如何在Linux系统中启动Hadoop,包括执行start-dfs.sh启动Hadoop,使用jps检查进程,创建HDFS目录,上传文件,运行WordCount示例程序以及查看结果。主要涉及的命令有hdfsdfs相关的如mkdir、ls、put、cat等。
本文详细介绍了如何在Linux系统中启动Hadoop,包括执行start-dfs.sh启动Hadoop,使用jps检查进程,创建HDFS目录,上传文件,运行WordCount示例程序以及查看结果。主要涉及的命令有hdfsdfs相关的如mkdir、ls、put、cat等。
前置条件
- 在Linux上安装Hadoop
- 启动Hadoop
./sbin/start-dfs.sh

操作步骤
(1)使用"jps"查看java虚拟进程
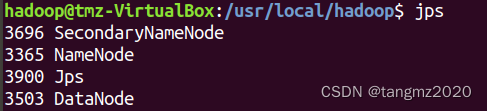
(2)创建test1
hdfs dfs -mkdir /test1

mkdir命令用来在指定的path中新建子目录。其中,创建位置path可采用URI格式进行指定。该命令功能与Linux系统的mkdir相同,允许一次创建多个子目录。一般格式如下:
hadoop fs -mkdir [-p]
其中,-p选项表示创建子目录时先检查路径是否存在,若不存在则同时创建相应的各级目录。
(3) 查看test1是否创建成功
hdfs dfs -ls /

(4)在主目录下创建一个data.txt文件,填充文本(可自定)
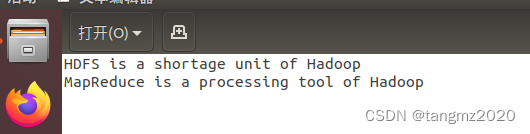
(5)将data.txt的数据上传到HDFS的test1中
hdfs dfs -put ~data.txt /test1

再次使用 hdfs dfs -ls /检查数据是否传输成功

(6)运行WordCount程序
hadoop jar [hadoop-mapreduce-examples的地址].jar wordcount /test1/data.txt /test/out
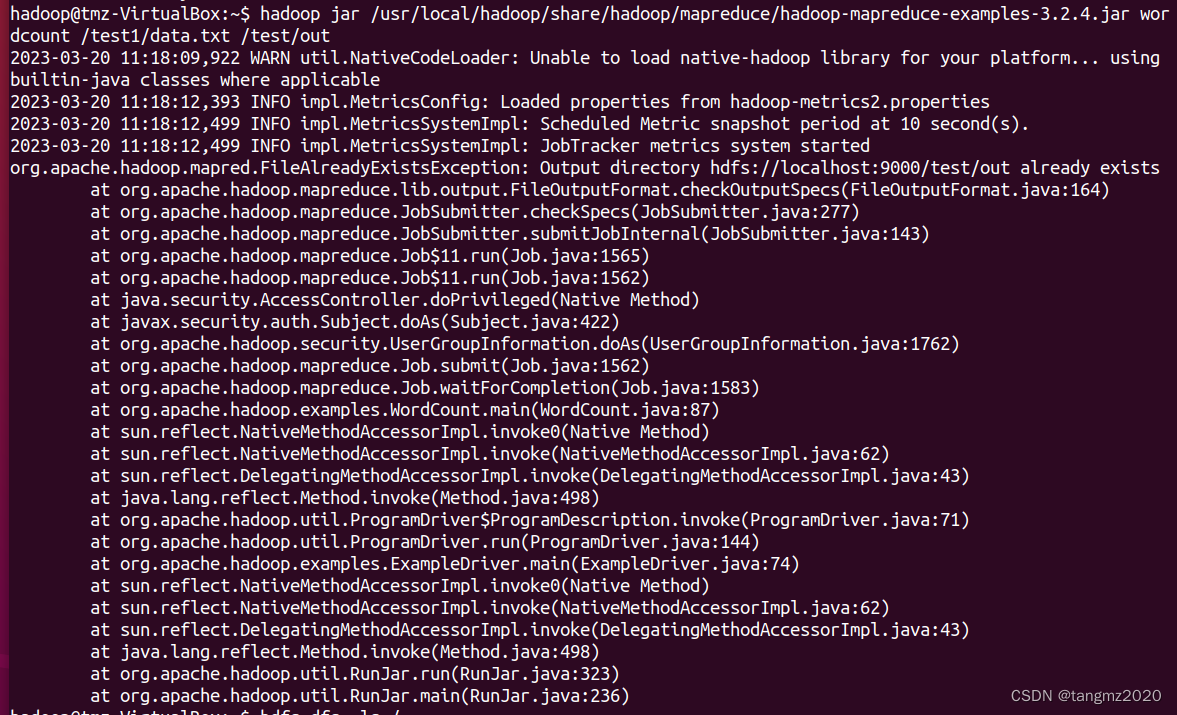
可以试着按照截图中的路径找hadoop-mapreduce-examples的地址
(7) 查看结果所在文件

从上图中知道生成了三个文件,我们的结果在"part-r-00000"中
(8)查看结果输出文件内容
hdfs dfs -cat /test/out/part-r-00000
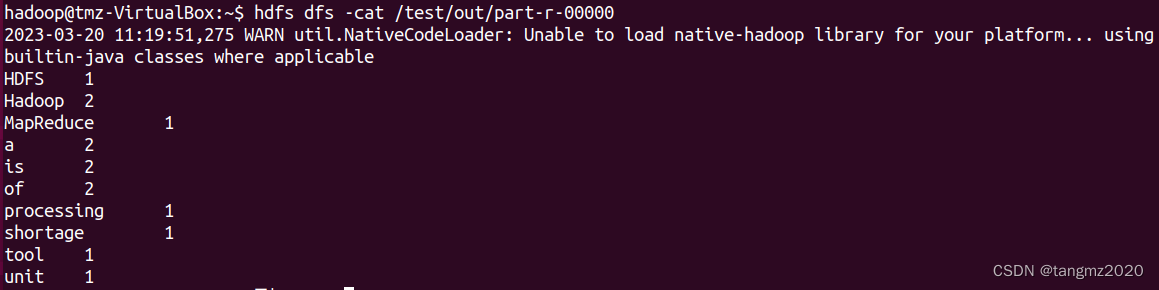
HDFS dfs 操作命令
问题集锦
1)查看解决方法

2)输入文件缺少斜杆

















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









