






 本文详细介绍如何为Spark程序添加单元测试,包括使用ScalaTest测试框架、针对SparkApplication的测试策略及利用SparkFastTests组件进行Dataset/DataFrame对比的具体方法。
本文详细介绍如何为Spark程序添加单元测试,包括使用ScalaTest测试框架、针对SparkApplication的测试策略及利用SparkFastTests组件进行Dataset/DataFrame对比的具体方法。
相比于传统代码,Spark是比较难调试的。程序运行在集群中,每次修改代码后,都要上传到集群进行测试,代价非常大,所以优先在本地进行单元测试,可以减少小模块的逻辑错误。
一、ScalaTest 测试框架
ScalaTest是比JUnit和TestNG更加高阶的测试编写工具,这个Scala应用在JVM上运行,可以测试Scala以及Java代码。ScalaTest一共提供了七种测试风格,分别为:FunSuite,FlatSpec,FunSpec,WordSpec,FreeSpec,PropSpec和FeatureSpec。
FunSuite的方式较为灵活,而且更符合传统测试方法的风格,区别仅在于test()方法可以接受一个闭包。而FlatSpec和FunSpec则通过提供诸如it、should、describe等方法,来规定书写测试的一种模式。
使用方式如下:
1、引入依赖
testCompile group: 'org.scalatest', name: 'scalatest_2.11', version: '3.0.6-SNAP5'
2、编写对应的case
scala test 测试代码
import org.scalatest._
class HelloWorldTest
extends FunSuite {
test("Test difference") {
val a = Set("a", "b", "a", "c")
val b = Set("b", "d")
assert(a -- b === Set("a", "c"))
}
//交集
test("Test intersection") {
val a = Set("a", "b", "a", "c")
val b = Set("b", "d")
assert(a.intersect(b) === Set("b"))
}
//并集
test("Test union") {
val a = Set("a", "b", "a", "c")
val b = Set("b", "d")
assert(a ++ b === Set("a", "b", "c", "d"))
}
test("Test difference failed") {
val a = Set("a", "b", "a", "c")
val b = Set("c", "d")
//应该等于Set("a","b")
assert(a -- b === Set("a", "c"))
}
}
3、运行该test cast,查看执行效果
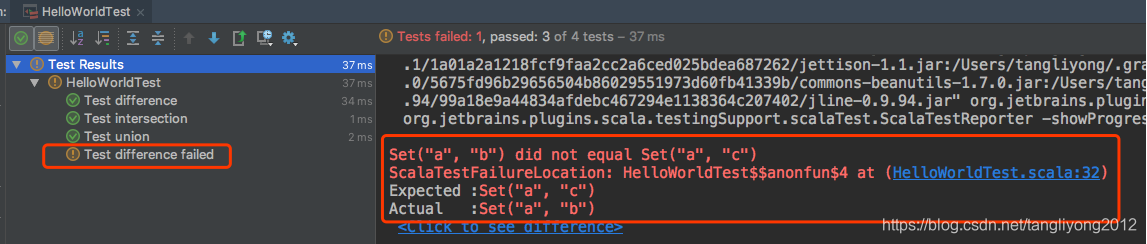
可以看到 前三条case 执行通过,最后一条未通过的case 也明确指出了期望值和实际值,这时候我们 根据提示去修改对应的处理逻辑代码即可。
二、Spark Application 该如何进行单元测试?
通常一个完整的spark application,可以简化的理解为是对一些数据的处理/运算 然后将运算的结果输出到其它介质中。
因此在spark 程序中,会涉及到:
1、对数据的读入(通过streming 或者 批量读文件的形式);
2、对数据进行运算(格式转换、逻辑运算,筛选filter etc);
3、对运算结果的输出
在spark 2.x 的架构中,spark 程序入库已经统一到SparkSession 、Dataset/DataFrame 为主要的用户 API。我们所进行的数据计算操作都可以抽象的理解为是在对 Dataset 进行转换操作,通过我们编写的函数,从一个原 Dataset/DataFrame 得到一个我们所期望的目的 Dataset/DataFrame。
我们在编写spark 程序的时候,应该尽量按照这个原则来构建spark 程序内部的功能模块,即:输入输出独立于业务计算,每个业务计算 通过Dataset/DataFrame 的转换来封装成不同的函数模块。那么我们在进行单元测试的时候,就可以只重点关注到 我们实现的一个个具体业务计算的Dataset/DataFrame的转换中,减少 输入输出 等环境依赖(输入输出的格式,依靠接口文档)。
前面 提到的 ScalaTest 测试框架 更侧重于对scala 语法本身的一些 集合,功能进行单元测试。上面我们分析了,对spark 进行单元测试的重心其实就是对 Dataset/DataFrame 转换的测试。
三、Spark Fast Tests 组件
spark-fast-tests 是一个开源工具包,能够很方便帮助我们 对比Dataset/DataFrame。其提供了以下一些方法:
两个Dataset/DataFrame 相等对比
assertSmallDataFrameEquality 适用于本地较小两个DF对比
assertSmallDataFrameEquality 适用于本地较小两个DS对比
assertLargeDatasetEquality 适用于集群较大两个DF对比
assertLargeDatasetEquality 适用于集群较大两个DS对比
⚠️相等比较时候 忽略 null 使用 ignoreNullable 参数
eg:
assertSmallDatasetEquality(actualDF, expectedDF,ignoreNullable=true)
一个 Dataset/DataFrame 两列相等对比
assertColumnEquality(df, "Column1", "Column2")
使用实例:
import org.apache.spark.sql.SparkSession
trait SparkSessionTestWrapper {
lazy val spark: SparkSession = {
SparkSession
.builder()
.master("local")
.appName("spark test example")
.getOrCreate()
}
}
import com.github.mrpowers.spark.fast.tests._
import org.scalatest.FunSpec
class DatasetSpec extends FunSpec with SparkSessionTestWrapper with DatasetComparer with ColumnComparer {
import spark.implicits._
it("aliases a DataFrame") {
val sourceDF = Seq(
("jose"), ("li"),("luisa")
).toDF("name")
val actualDF = sourceDF.selectExpr("name as student")
val expectedDF = Seq(
("jose"),("li"),("luisa")
).toDF("student")
assertSmallDatasetEquality(actualDF, expectedDF)
}
it("df expected_name") {
val df = Seq(
("jose", "jose"),
("li", "none"),
("luisa", "luisa")
).toDF("name", "expected_name")
assertColumnEquality(df, "Column1", "Column2")
}
}

运行结果上,可以看到 第一条case 执行通过,最后一条未通过的case 也明确指出了期望值和实际值,这时候我们 根据提示去修改对应的处理逻辑代码即可。
参考资料:
https://blog.youkuaiyun.com/hany3000/article/details/51033610
https://medium.com/@mrpowers/testing-spark-applications-8c590d3215fa
https://github.com/MrPowers/spark-fast-tests

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









