



Arcon:连续且深度的数据流分析
摘要
现代端到端数据管道需要结合多种不同的工作负载,例如机器学习、关系操作、流式数据流、张量变换和图结构。对于这些每种类型的工作负载,存在基于不同编程语言的多个前端(例如,SQL、Beam、Keras)以及针对特定前端并可能针对特定硬件架构(例如,GPU)进行优化的不同运行时(例如,Spark、Flink、TensorFlow)。由此产生的数据管道在复杂性和性能方面表现不佳,原因包括过多的类型转换、中间结果的物化,以及缺乏跨框架的优化。Arcon旨在提供一种统一的方法,用于跨前端边界声明和执行任务,同时支持其与事件驱动服务的大规模无缝集成。在本次演示中,我们展示了Arcon,并通过一系列用例场景证明了其执行模型足够强大,能够满足现有以及未来面向分析和特定应用需求的实时计算。
CCS概念
- 信息系统 → 数据流
- 软件及其工程 → 数据流语言
ACM引用格式
马克斯·梅尔德伦、克拉什·塞格尔亚克特、拉尔斯·克罗尔、巴黎·卡尔博尼、克里斯蒂安·舒尔特和赛夫·哈里迪。2019年。Arcon:连续与深度数据流分析。载于实时商业智能与分析(BIRTE 2019),8月,美国加利福尼亚州洛杉矶。ACM协会,美国纽约州纽约,页码。https://doi.org/10.1145/3350489.3350492
1 引言
如今有大量可扩展的数据处理框架可供使用,每个框架都针对特定类型的计算,并体现在其支持的前端中。例如专注于DataFrame/关系操作、Flink[2]采用Beam窗口模型[1],使用TensorFlow进行张量编程等。在实践中,完整的数据管道通常涉及不止一个框架。以典型的机器学习流水线为例,需要在基于实时事件的应用中立即进行特征生成、模型训练并部署这些模型。在应用中组合多个框架可能导致复杂性和性能损失,例如处理保证不匹配、硬件利用率低下以及跨框架重新实例化带来的高延迟。此外,目前没有一种面向用户的编程模型能够涵盖其他模型,也没有现有的运行时具备执行根本不同工作负载(例如数据流任务和动态调度计算)的能力。
Arcon是一个开源系统,旨在通过提供以下两方面功能来解决这一问题:(1) Arc:一种用于声明数据驱动计算的通用中间表示(IR);(2) Arcon Runtime:一种通用分布式运行时,用于执行通过Arc编译和优化的程序。凭借这一独特的共性功能集,Arcon允许用户在单个应用程序中捕获并执行多种计算任务,例如实时图挖掘、训练和部署机器学习模型,以及声明流窗口聚合。
Arcon运行时将两种不同的执行模型合二为一:一种是流处理中常见的长周期数据流模型,专注于连续、不间断处理;另一种是批处理系统中的动态任务调度模型,更擅长深度分析。本次演示展示了这两种执行模型在新兴应用领域(如在线商业分析和动态基于角色的应用)中的无缝集成。
演示大纲
我们将涵盖(1)Arcon的内部机制,从其整体设计和编译到执行模型,介绍Arcon主要组件——包括Arc编译器及其导致代码生成的编译阶段,以及负责大规模部署和执行生成的代码片段的Arcon运行时;(2)随后对应用场景进行逐步分析,突出Arcon的主要特性,并展示和执行一组利用不同现有前端的不同程序。
2 系统概述
Arcon系统的主要组件是Arc程序编译器和Arcon运行时,如图1所示。Arcon允许现有的和未来的前端可以通过直接将其操作转换为Arc来无缝支持。在本节中,我们提供了Arc和Arcon运行时的设计概述,同时重点关注所展示系统的各个特性。
2.1 Arc中间语言
Arc IR[3]是对Weld IR[4]的扩展,增加了在流和窗口上表达连续且可扩展的计算的能力。Weld是一种用于描述有界大小数据集上变换的语言,旨在提升依赖多个库的数据分析应用的性能。由于库通常只在内部进行优化,而彼此之间缺乏协同优化,因此在将不同库的函数进行流水线处理时,可能会产生高昂的数据移动成本,因为中间结果可能需要被立即物化。Weld通过作为不同计算之间的通用转换层来解决这一问题。Weld的编程模型基于单子推导,支持数据并行,同时对硬件进行抽象。Weld中的数据类型分为值类型或构建器类型:前者是只读数据类型,可以是标量或集合;后者是只写数据类型,等价于加法单子。
Weld的构建器用于创建值,而Arcc添加的构建器则用于构建由通道连接、包含源和汇的操作符流处理管道。Arcc引入了流和流构建器作为新的数据类型,并通过称为窗口器的高阶构建器支持窗口化流。由于Arcc保留了Weld的完全表达能力,开发人员将能够在同一应用程序中利用流处理和批处理的优势,实现连续与深度分析。
2.2 Arcon运行时
Arcon的分布式运行时旨在明确区分高性能与可操作性之间的关注点。一方面,它旨在利用特殊硬件以及底层系统和网络优化,以高效且可靠地执行应用程序的关键路径;同时,它还必须能够与现有的云计算生态系统(例如资源管理器、调度器、数据存储等)良好集成,以满足其非性能关键型的运维需求。出于这些原因,Arcon被划分为执行和运维两个平面,以在这两类需求之间实现适当的协同与独立性。在图2中,我们展示了该运行时的物理部署模型,其内部结构将在本节其余部分进行概述。
2.2.1 操作平面
操作平面负责协调应用程序的分布式执行,包括任务部署、监控和状态管理。该系统部分使用Scala Akka构建,以实现与现有工具和数据处理库(例如YARN、HDFS)的互操作性,并利用成熟的参与者编程模型来实现关键的操作服务,如状态管理和作业监控。
2.2.2 执行平面
Arcon的执行平面为每个算子提供了本地可用的高性能计算环境。这包括对所有关键辅助机制的支持(例如,多路复用网络IO、本地状态和动态任务调度)。本质上,它是一组系统库,确保所有时间敏感的操作都能在无不必要延迟下执行。为此,我们使用专用中间件实现了这些库,以执行完全用Rust编写的程序片段,从而实现高性能、内存安全以及无垃圾回收。如图2所示,每个工作节点都支持长时运行的流式任务和短时运行的动态任务的执行。通过动态调度支持短时任务,实质上提供了支持涉及间歇性批处理计算(例如,强化学习)的应用程序的能力,或在otherwise静态的数据流图中实现“抢占式”计算。这还可以进一步用于将连续应用程序的关键路径从耗时的工作中卸载,例如执行外部IO或计算密集型任务(即迭代计算、仿真)。
3 系统演示
我们的演示主要关注如何对来自不同应用领域的问题进行抽象,并通过单一运行时系统进行处理。观众应能够了解从特定领域问题描述到在通用分布式处理基础设施上执行的整个过程。
3.1 演示流程
在系统演示期间,我们将展示多个用例场景,以突出Arcon的功能。通过图3、4和5,我们展示了将在每个场景中遵循的通用演示流程。每个场景都将首先使用Python和Scala等常见的数据科学语言,描述问题的高层领域特定描述。基于此,我们将描述实现该代码的Arc IR,它以与领域无关的方式表达,并被Arcon所理解。
import arc_beam as beam
import arc_beam.transforms.window as window
import weld_pandas as pd
def normalize(data):
s = pd.Series(data)
return s / s.sum()
p = beam.Pipeline(...)
(p | 'filter' >> beam.Filter(lambda x: x > 0)
| 'window' >> beam.WindowInto(window.FixedWindows(60))
| 'map' >> beam.Map(normalize)
| 'sink' >> beam.io.WriteToSink(Kafka(...)))
p.run()
更进一步,我们将演示这种逻辑表示如何转换为可部署的数据流图,并在我们的运行时中执行。在应用程序运行期间,我们将使用数据流图描述系统的内部机制,并详细说明系统各部分之间的交互方式。最后,我们将以一种便于观察者理解的方式展示执行结果。图3突出展示了一个结合了Beam和Pandas的应用程序。Beam构建了一个操作符流水线,从Kafka源读取整数流作为输入,并将输出写入Kafka接收端。中间处理步骤包括过滤负整数,以及创建一个长度为一分钟的滚动窗口。每个窗口以其元素的normalize形式输出一个向量。生成的Arc IR和运行时部署图分别如图4和图5所示。
3.2 应用领域
我们将使用相同的演示流程来展示一些当前因缺乏跨框架SDK集成或通用运行时而受到影响的流水线。为此,我们选择了“在线分析”和“基于角色的服务”这两个应用领域。
在线商业分析
商业分析正变得日益重要,已从年度或月度的回顾性报告转向日常决策支持。尽管“在线”特性对决策过程本身至关重要,但当前商业分析流水线中的多个阶段仍十分复杂,由于涉及多种技术的组合,往往需要耗费数天时间进行数据对账。例如,如果商业分析模型使用了图表示,则底层任务可能需要对图快照执行深度分析(例如,使用类似Giraph的系统识别图骨干),或对动态图执行增量/近似分析(例如顶点计数、三角形计数等)。然而,由于涉及不同的运行时(例如分别为批处理和流处理框架),整个流程中无法实现数据或计算共享。因此,骨干识别算法无法利用在动态更新图中“持续计算”的三角形集合。机器学习任务在流水线不同阶段也常使用多样化的框架(如Pytorch、Keras、Pandas、MLlib、Ray、xarray等),因而数据和计算共享的可能性同样受到限制。
4 结论与未来工作
我们提供了一个详细的交互式演示,介绍了Arcon这一通用分布式计算框架,该框架旨在统一数据驱动应用的声明与执行。通过一系列用例,我们展示了如何以统一的方式编译、优化并执行使用多个数据处理前端的程序。Arcon未来的主要发展方向之一是通过将现有框架的原语直接转换为Arc,从而支持大多数现有的数据计算框架。
生成的Arc IR
1 type ts = u64, val = i64, elem = { ts, val };
2 源: stream[元素], 接收器: streamappender[元素]
3 let filtered = filter(source,
4 |le: elem| le.$1 > 0);
5 let 窗口化的 = for(filtered,
6 |le: elem, _, _| {[le.$0 / 60L]},
7 |wm: ts, open: vec[ts], _| {filter(open, |t| t < wm), ()},
8 |t: ts, agg: appender[val]| {t, normalize(result(agg))})
9 |w: windower, e: elem| merge(w, e));
10 drain(窗口化的, 接收器)
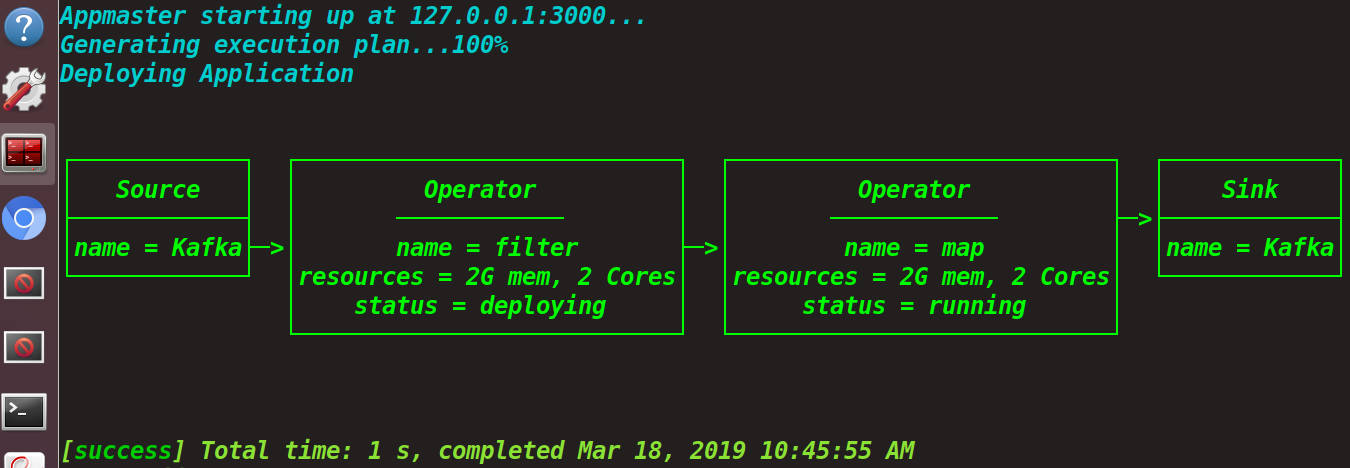
数据流部署
Appmaster starting up at 127.0.0.1:3
Generating execution plan... 100%
Deploying Application
Sources: Kafka
Operators: filter, window, map, sink
Resources = 2G memory, 2 Cores
Deploying on cluster...
Total time to deployment: 2.3s
Application completed
Mar 18, 2019 10:45:55 AM
相对较低。在整个演示过程中,我们将展示Arcon如何通过其中间表示实现常见表达、优化和执行本质上不同的任务,并由同一运行时执行,从而解决这些问题。
基于有状态Actor的服务
使用基于Actor的框架是编写通用基于事件的服务和应用程序的当前标准。通常,应用程序逻辑被划分为若干逻辑单元,并在如Akka或Orleans等Actor框架中实现和执行。以这种方式构建服务(通常称为“微服务”)的一个缺点是,缺乏跨微服务或Actor的集成状态管理和容错能力。Arcon旨在支持此类应用,同时提供统一的状态管理,并无缝集成长时间运行的基于事件的任务逻辑和动态调用,例如调用外部资源进行数据增强。

















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









