



 本文介绍了分布式和集群的概念,重点剖析了Hadoop框架,包括其国内外的应用案例(如Yahoo和阿里巴巴),Hadoop的不同版本架构(Hadoop1.x至3.x),HDFS的特点和架构,以及HDFS的Shell命令。
本文介绍了分布式和集群的概念,重点剖析了Hadoop框架,包括其国内外的应用案例(如Yahoo和阿里巴巴),Hadoop的不同版本架构(Hadoop1.x至3.x),HDFS的特点和架构,以及HDFS的Shell命令。
1.分布式和集群介绍
-
分布式: 多台机器做不同的事情, 然后组成1个整体.
-
集群: 多台机器做相同的事情.
-
多台机器既可以组成 中心化模式(主从模式), 也可以组成 去中心化模式(主备模式)

2.Hadoop框架国内外应用
-
国外
-
Yahoo雅虎, 节点4.2W+, 超10W核, 总存储350PB+, 每月提交作业 1000W+
-
-
国内
-
阿里巴巴, 节点3000+, 超4W核心, 内存超100TB, 每月提交作业 450W+
-
-
Hadoop的组成
-
HDFS: 分布式存储框架
-
MapReduce: 分布式计算框架
-
Yarn: 任务接收和调度器
-
3. Hadoop的架构图
①Hadoop1.X = HDFS + MapReduce
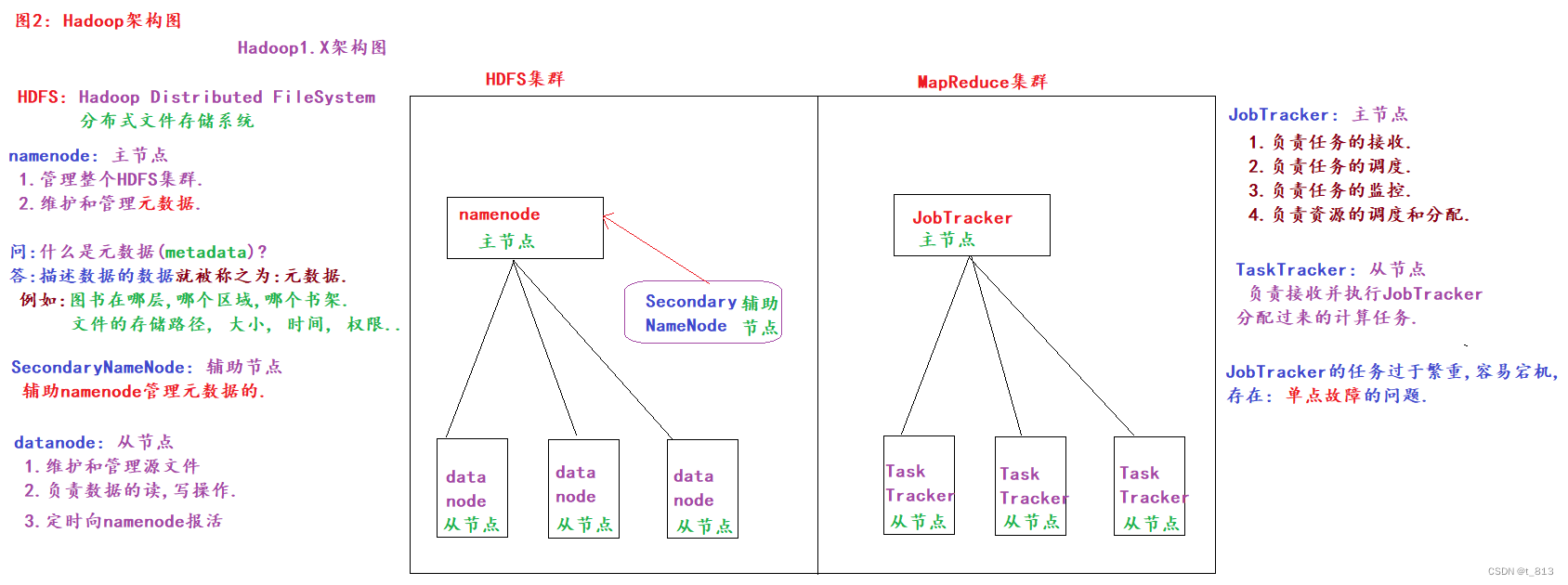
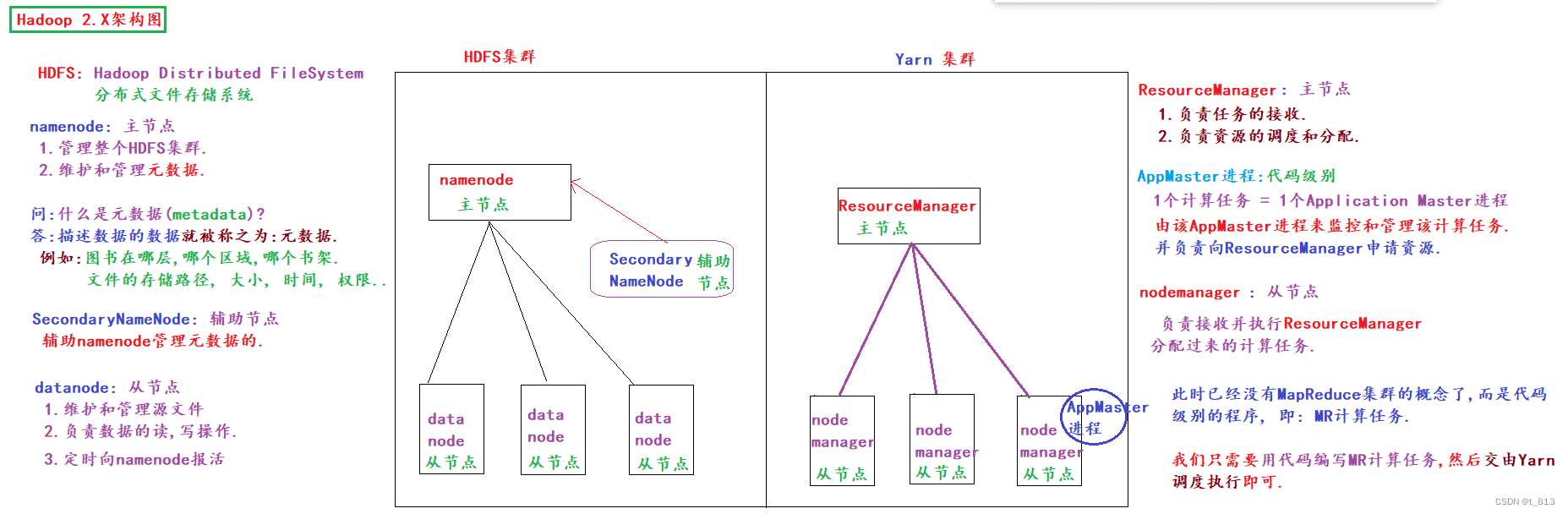
②Hadoop2.X, 3.X = HDFS + MapReduce + Yarn
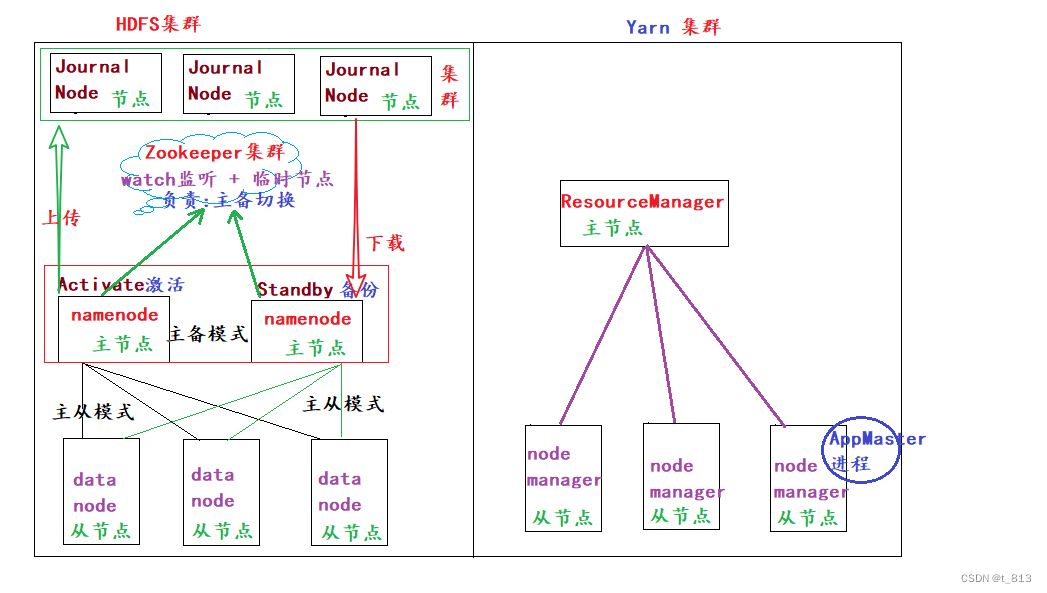
③Hadoop集群高可用模式图解
4.HDFS的特点
-
HDFS文件系统可存储超大文件,时效性稍差。
-
HDFS具有硬件故障检测和自动快速恢复功能。
-
HDFS为数据存储提供很强的扩展能力。
-
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
-
HDFS可在普通廉价的机器上运行。
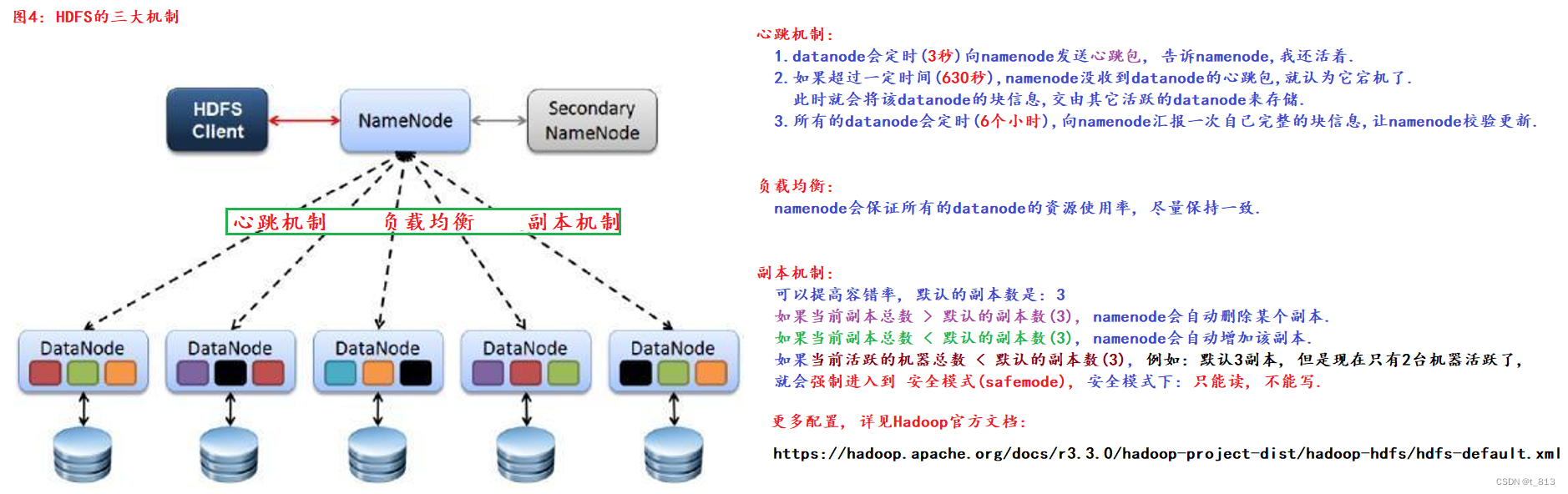
5.HDFS的架构图
6.HDFS的Shell命令
# HDFS的Shell命令, 类似于Linux的Shell命令, 格式稍有不同, 具体如下:
hadoop fs -选项 参数 # 既能操作HDFS文件系统, 还能操作本地文件系统.
hdfs dfs -选项 参数 # 只能操作HDFS文件系统.
# 细节: 操作HDFS路径的时候, 建议加上前缀 hdfs://node1:8020/
# -ls命令, 查看指定的HDFS路径下所有的内容.
hadoop fs -ls / # 查看根目录下所有内容(不包括子级)
hadoop fs -lsr / # 查看根目录下所有内容(包括子级), 该命令已过时, 不推荐用.
hadoop fs -ls -R / # 查看根目录下所有内容(包括子级), 该命令已过时, 不推荐用.
# mkdir命令, 创建目录
hdfs dfs -mkdir /aa # 创建单级.
hdfs dfs -mkdir -p /aa/bb/cc/dd # 创建多级目录.
# cat命令, 查看文件内容.
hadoop fs -cat /input/word.txt
# mv命令, 剪切. 只能是 HDFS路径 => HDFS路径
hadoop fs -mv /input/word.txt /aa
# cp命令, 拷贝. 只能是 HDFS路径 => HDFS路径
hadoop fs -cp /input/word.txt /aa
# rm命令, 删除.
hadoop fs -rm /aa/bb/word.txt
hadoop fs -rmr /aa # 递归删除aa文件夹
hadoop fs -rm -r /aa # 递归删除aa文件夹, 效果同上.
# put命令, 把Linux系统的文件 上传到 HDFS文件系统中.
hadoop fs -put 1.txt /input # 1.txt是Linux的文件路径, /input是HDFS的目录路径
# get命令, 把HDFS文件系统的某个文件 下载到 Linux系统的文件中.
hadoop fs -get /input/1.txt ./ # 1.txt是HDFS的文件路径, ./Linux的路径.

















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









