






先写个测试用的html文件,命名test.html
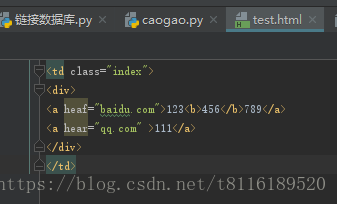
我们想要匹配第一个a标签里面的全部内容:
import lxml.etree
html=lxml.etree.parse("test.html")
res=html.xpath("//a[@heaf='baidu.com']")
info=res[0].xpath('string(.)')
print(info)运行结果:
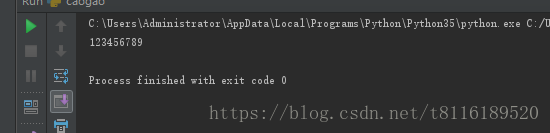
先写个测试用的html文件,命名test.html
我们想要匹配第一个a标签里面的全部内容:
import lxml.etree
html=lxml.etree.parse("test.html")
res=html.xpath("//a[@heaf='baidu.com']")
info=res[0].xpath('string(.)')
print(info)运行结果:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 3285
3285





