







 本文深入探讨Redis的过期策略,包括定期删除与惰性删除机制,以及在内存压力下采取的多种内存淘汰策略,如LRU、random等,确保缓存高效运行。
本文深入探讨Redis的过期策略,包括定期删除与惰性删除机制,以及在内存压力下采取的多种内存淘汰策略,如LRU、random等,确保缓存高效运行。
Redis过期策略以及内存淘汰机制
面试题
redis的过期策略都有哪些?内存淘汰机制都有哪些?手写一下LRU代码实现?
面试官心里分析
1)老师啊,我往redis里写的数据怎么没了?
之前有同学问过我,说我们生产环境的redis怎么经常会丢掉一些数据?写进去了,过一会儿可能就没了。我的天,同学,你问这个问题就说明redis你就没用对啊。redis是缓存,你给当存储了是吧?
啥叫缓存?用内存当缓存。内存是无限的吗,内存是很宝贵而且是有限的,磁盘是廉价而且是大量的。可能一台机器就几十个G的内存,但是可以有几个T的硬盘空间。redis主要是基于内存来进行高性能、高并发的读写操作的。
那既然内存是有限的,比如redis就只能用10个G,你要是往里面写了20个G的数据,会咋办?当然会干掉10个G的数据,然后就保留10个G的数据了。那干掉哪些数据?保留哪些数据?当然是干掉不常用的数据,保留常用的数据了。
所以说,这是缓存的一个最基本的概念,数据是会过期的,要么是你自己设置个过期时间,要么是redis自己给干掉。
set key value 过期时间(1小时)
set进去的key,1小时之后就没了,就失效了
2)老师,我的数据明明都过期了,怎么还占用着内存啊?
还有一种就是如果你设置好了一个过期时间,你知道redis是怎么给你弄成过期的吗?什么时候删除掉?如果你不知道,之前有个学员就问了,为啥好多数据明明应该过期了,结果发现redis内存占用还是很高?那是因为你不知道redis是怎么删除那些过期key的。
redis 内存一共是10g,你现在往里面写了5g的数据,结果这些数据明明你都设置了过期时间,要求这些数据1小时之后都会过期,结果1小时之后,你回来一看,redis机器,怎么内存占用还是50%呢?5g数据过期了,我从redis里查,是查不到了,结果过期的数据还占用着redis的内存。
如果你连这个问题都不知道,上来就懵了,回答不出来,那线上你写代码的时候,想当然的认为写进redis的数据就一定会存在,后面导致系统各种漏洞和bug,谁来负责?
面试题剖析
设置过期时间
我们set key的时候,都可以给一个expire time,就是过期时间,指定这个key比如说只能存活1个小时?10分钟?这个很有用,我们自己可以指定缓存到期就失效。
如果假设你设置一个一批key只能存活1个小时,那么接下来1小时后,redis是怎么对这批key进行删除的?
答案是:定期删除+惰性删除
所谓定期删除,指的是redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。假设redis里放了10万个key,都设置了过期时间,你每隔几百毫秒,就检查10万个key,那redis基本上就死了,cpu负载会很高的,消耗在你的检查过期key上了。注意,这里可不是每隔100ms就遍历所有的设置过期时间的key,那样就是一场性能上的灾难。实际上redis是每隔100ms随机抽取一些key来检查和删除的。
但是问题是,定期删除可能会导致很多过期key到了时间并没有被删除掉,那咋整呢?所以就是惰性删除了。这就是说,在你获取某个key的时候,redis会检查一下 ,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
并不是key到时间就被删除掉,而是你查询这个key的时候,redis再懒惰的检查一下
通过上述两种手段结合起来,保证过期的key一定会被干掉。
很简单,就是说,你的过期key,靠定期删除没有被删除掉,还停留在内存里,占用着你的内存呢,除非你的系统去查一下那个key,才会被redis给删除掉。
但是实际上这还是有问题的,如果定期删除漏掉了很多过期key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期key堆积在内存里,导致redis内存块耗尽了,咋整?
答案是:走内存淘汰机制。
内存淘汰
如果redis的内存占用过多的时候,此时会进行内存淘汰,有如下一些策略:
redis 10个key,现在已经满了,redis需要删除掉5个key
1个key,最近1分钟被查询了100次
1个key,最近10分钟被查询了50次
1个key,最近1个小时倍查询了1次
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的key给干掉啊
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key(这个一般不太合适)
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除
百度,问题啊,网上鱼龙混杂
如果百度一些api操作,入门的知识,ok的,随便找一个博客都可以
一些高级别的,redis单线程模型
很简单,你写的数据太多,内存满了,或者触发了什么条件,redis lru,自动给你清理掉了一些最近很少使用的数据
要不你手写一个LRU算法?
我确实有时会问这个,因为有些候选人如果确实过五关斩六将,前面的问题都答的很好,那么其实让他写一下LRU算法,可以考察一下编码功底
你可以现场手写最原始的LRU算法,那个代码量太大了,我觉得不太现实
LRU
LRU(Least Recently Used)是一种常见的页面置换算法,在计算中,所有的文件操作都要放在内存中进行,然而计算机内存大小是固定的,所以我们不可能把所有的文件都加载到内存,因此我们需要制定一种策略对加入到内存中的文件进项选择。
常见的页面置换算法有如下几种:
- LRU 最近最久未使用
- FIFO 先进先出置换算法 类似队列
- OPT 最佳置换算法 (理想中存在的)
- NRU Clock置换算法
- LFU 最少使用置换算法
- PBA 页面缓冲算法
LRU原理
LRU的设计原理就是,当数据在最近一段时间经常被访问,那么它在以后也会经常被访问。这就意味着,如果经常访问的数据,我们需要然其能够快速命中,而不常访问的数据,我们在容量超出限制内,要将其淘汰。
当我们的数据按照如下顺序进行访问时,LRU的工作原理如下:
正如上面图所表示的意思:每次访问的数据都会放在栈顶,当访问的数据不在内存中,且栈内数据存储满了,我们就要选择移除栈底的元素,因为在栈底部的数据访问的频率是比较低的。所以要将其淘汰。
LRU的实现
如何来设计一款LRU算法呢?对于这种类似序列的结构我们一般可以选择链表或者是数组来构建。
差异对比:
- 数组 查询比较快,但是对于增删来说是一个不是一个好的选择
- 链表 查询比较慢,但是对于增删来说十分方便O(1)时间复杂度内搞定
有没有办法既能够让其搜索快,又能够快速进行增删操作。
我们可以选择链表+hash表,hash表的搜索可以达到0(1)时间复杂度,这样就完美的解决我们搜索时间慢的问题了
1. 基于链表+Hash表
Hash表,在Java中HashMap是我们的不二选择
链表,Node一个双向链表的实现,Node中存放的是数结构如下:
class Node<K,V>{
private K key;
private V value;
private Node<K,V> prev;
private Node<K,V> next;
}
我们通过HashMap中key存储Node的key,value存储Node来建立Map对Node的映射关系。我们将HashMap看作是一张检索表,我们可以可以快速的检索到我们需要定位的Node
下图展示这个结构:
代码实现
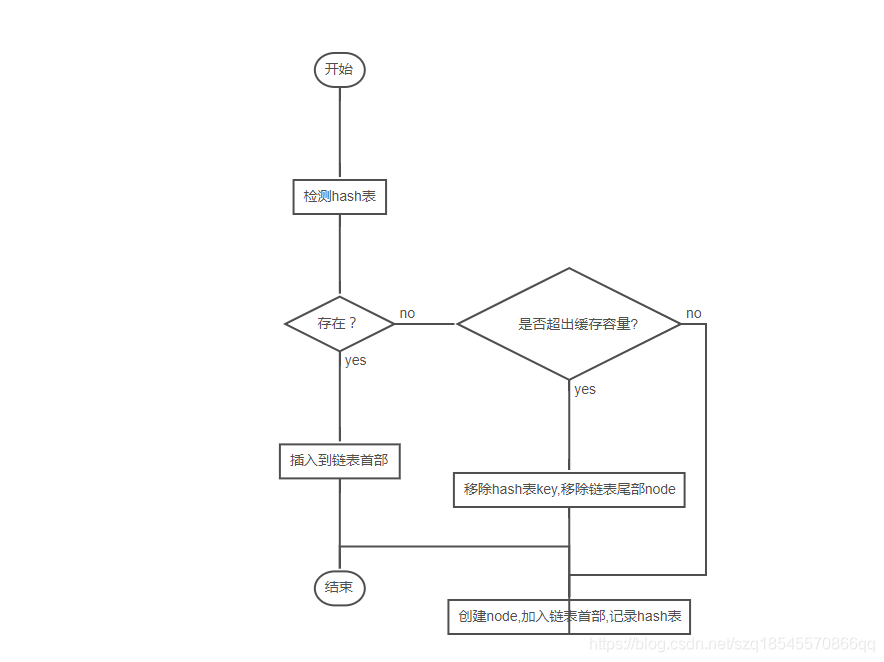
大致思路:
-
构建双向链表节点ListNode,应包含key,value,prev,next这几个基本属性
-
对于Cache对象来说,我们需要规定缓存的容量,所以在初始化时,设置容量大小,然后实例化双向链表的head,tail,并让head.next->tail tail.prev->head,这样我们的双向链表构建完成
-
对于get操作,我们首先查阅hashmap,如果存在的话,直接将Node从当前位置移除,然后插入到链表的首部,在链表中实现删除直接让node的前驱节点指向后继节点,很方便.如果不存在,那么直接返回Null
-
对于put操作,比较麻烦。
package code.fragment;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class LRUCache<V> {
/**
* 容量
*/
private int capacity = 1024;
/**
* Node记录表
*/
private Map<String, ListNode<String, V>> table = new ConcurrentHashMap<>();
/**
* 双向链表头部
*/
private ListNode<String, V> head;
/**
* 双向链表尾部
*/
private ListNode<String, V> tail;
public LRUCache(int capacity) {
this();
this.capacity = capacity;
}
public LRUCache() {
head = new ListNode<>();
tail = new ListNode<>();
head.next = tail;
head.prev = null;
tail.prev = head;
tail.next = null;
}
public V get(String key) {
ListNode<String, V> node = table.get(key);
//如果Node不在表中,代表缓存中并没有
if (node == null) {
return null;
}
//如果存在,则需要移动Node节点到表头
//截断链表,node.prev -> node -> node.next ====> node.prev -> node.next
// node.prev <- node <- node.next ====> node.prev <- node.next
node.prev.next = node.next;
node.next.prev = node.prev;
//移动节点到表头
node.next = head.next;
head.next.prev = node;
node.prev = head;
head.next = node;
//存在缓存表
table.put(key, node);
return node.value;
}
public void put(String key, V value) {
ListNode<String, V> node = table.get(key);
//如果Node不在表中,代表缓存中并没有
if (node == null) {
if (table.size() == capacity) {
//超过容量了 ,首先移除尾部的节点
table.remove(tail.prev.key);
tail.prev = tail.next;
tail.next = null;
tail = tail.prev;
}
node = new ListNode<>();
node.key = key;
node.value = value;
table.put(key, node);
}
//如果存在,则需要移动Node节点到表头
node.next = head.next;
head.next.prev = node;
node.prev = head;
head.next = node;
}
/**
* 双向链表内部类
*/
public static class ListNode<K, V> {
private K key;
private V value;
ListNode<K, V> prev;
ListNode<K, V> next;
public ListNode(K key, V value) {
this.key = key;
this.value = value;
}
public ListNode() {
}
}
public static void main(String[] args) {
LRUCache<ListNode> cache = new LRUCache<>(4);
ListNode<String, Integer> node1 = new ListNode<>("key1", 1);
ListNode<String, Integer> node2 = new ListNode<>("key2", 2);
ListNode<String, Integer> node3 = new ListNode<>("key3", 3);
ListNode<String, Integer> node4 = new ListNode<>("key4", 4);
ListNode<String, Integer> node5 = new ListNode<>("key5", 5);
cache.put("key1", node1);
cache.put("key2", node2);
cache.put("key3", node3);
cache.put("key4", node4);
cache.get("key2");
cache.put("key5", node5);
cache.get("key2");
}
}
2. 简略版本方式
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int CACHE_SIZE;
// 这里就是传递进来最多能缓存多少数据
public LRUCache(int cacheSize) {
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true); // 这块就是设置一个hashmap的初始大小,同时最后一个true指的是让linkedhashmap按照访问顺序来进行排序,最近访问的放在头,最老访问的就在尾
CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > CACHE_SIZE; // 这个意思就是说当map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据
}
}
我给你看上面的代码,是告诉你最起码你也得写出来上面那种代码,不求自己纯手工从底层开始打造出自己的LRU,但是起码知道如何利用已有的jdk数据结构实现一个java版的LRU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









