







资料来源 : 小林coding
小林官方网站 : 小林coding (xiaolincoding.com)

面试中,MySQL 索引相关的问题基本都是一系列问题,都是先从索引的基本原理,再到索引的使用场景,比如:
- 索引底层使用了什么数据结构和算法?
- 为什么 MySQL InnoDB 选择 B+tree 作为索引的数据结构?
- 什么时候适用索引?
- 什么时候不需要创建索引?
- 什么情况下索引会失效?
- 有什么优化索引的方法?
- .....
今天就带大家,夯实 MySQL 索引的知识点。
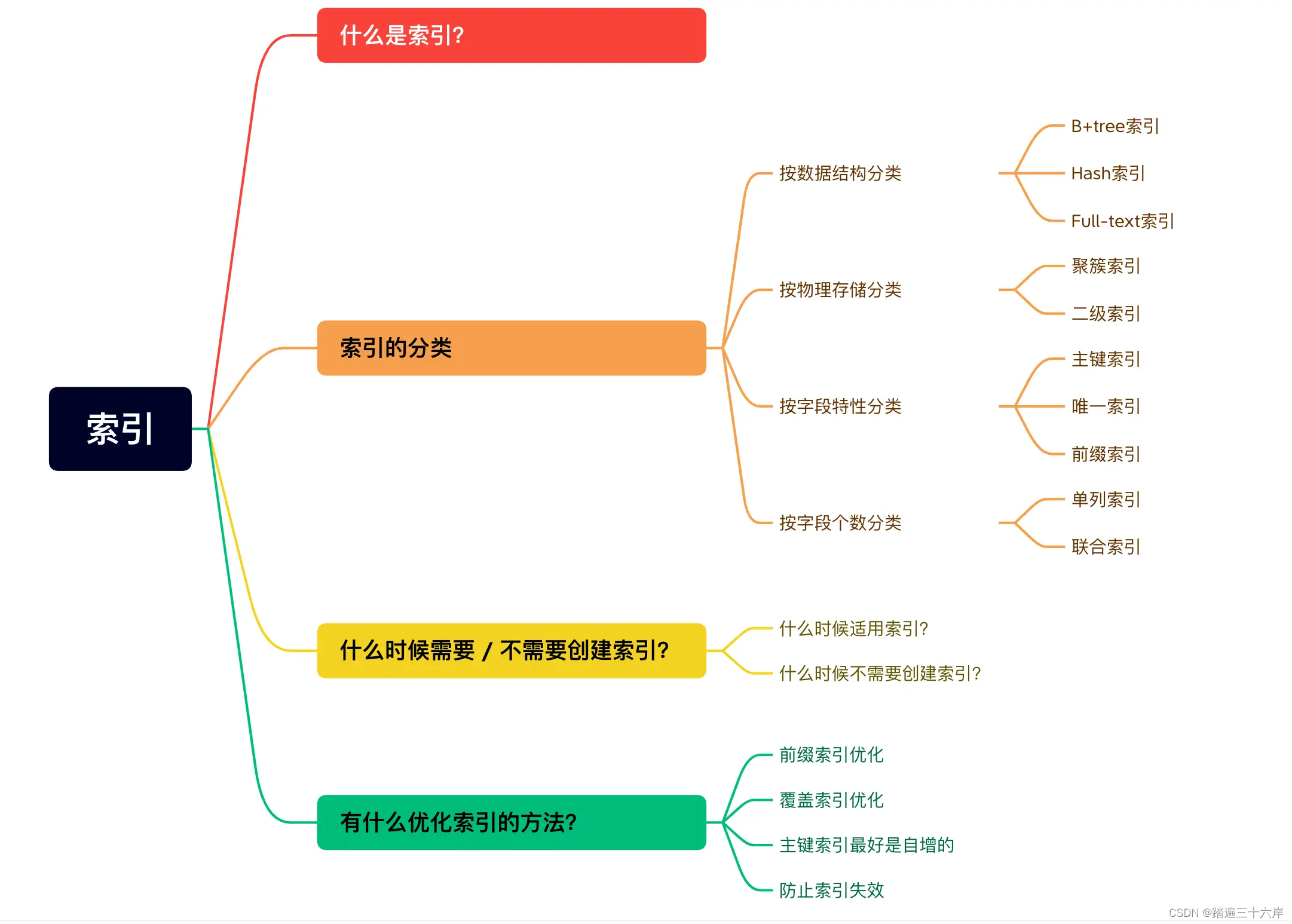
什么索引?
当你想查阅书中某个知识的内容,你会选择一页一页的找呢?还是在书的目录去找呢?
傻瓜都知道时间是宝贵的,当然是选择在书的目录去找,找到后再翻到对应的页。书中的目录,就是充当索引的角色,方便我们快速查找书中的内容,所以索引是以空间换时间的设计思想。
那换到数据库中,索引的定义就是帮助存储引擎快速获取数据的一种数据结构,形象的说就是索引是数据的目录。
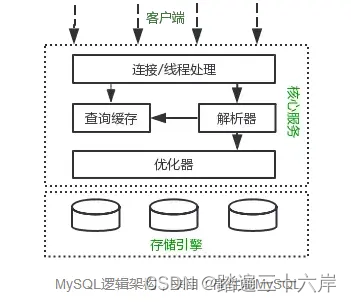
所谓的存储引擎,说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。MySQL 存储引擎有 MyISAM 、InnoDB、Memory,其中 InnoDB 是在 MySQL 5.5 之后成为默认的存储引擎。
下图是 MySQL 的结构图,索引和数据就是位于存储引擎中:
索引的分类
你知道索引有哪些吗?大家肯定都能霹雳啪啦地说出聚簇索引、主键索引、二级索引、普通索引、唯一索引、hash索引、B+树索引等等。
然后再问你,你能将这些索引分一下类吗?可能大家就有点模糊了。其实,要对这些索引进行分类,要清楚这些索引的使用和实现方式,然后再针对有相同特点的索引归为一类。
我们可以按照四个角度来分类索引。
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
接下来,按照这些角度来说说各类索引的特点。
按数据结构分类
从数据结构的角度来看,MySQL 常见索引有 B+Tree 索引、HASH 索引、Full-Text 索引。
每一种存储引擎支持的索引类型不一定相同,我在表中总结了 MySQL 常见的存储引擎 InnoDB、MyISAM 和 Memory 分别支持的索引类型。
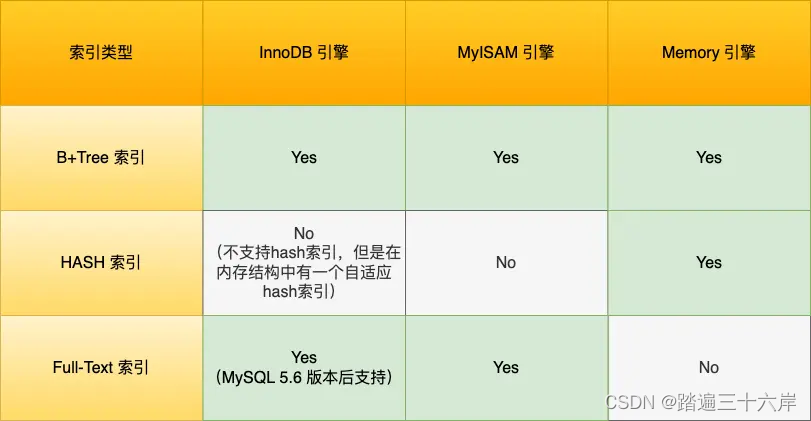
InnoDB 是在 MySQL 5.5 之后成为默认的 MySQL 存储引擎,B+Tree 索引类型也是 MySQL 存储引擎采用最多的索引类型。
在创建表时,InnoDB 存储引擎会根据不同的场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键(key);
- 如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键(key);
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键(key);
其它索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚簇索引。创建的主键索引和二级索引默认使用的是 B+Tree 索引。
为了让大家理解 B+Tree 索引的存储和查询的过程,接下来我通过一个简单例子,说明一下 B+Tree 索引在存储数据中的具体实现。
先创建一张商品表,id 为主键,如下:
CREATE TABLE `product` (
`id` int(11) NOT NULL,
`product_no` varchar(20) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`price` decimal(10, 2) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
商品表里,有这些行数据:
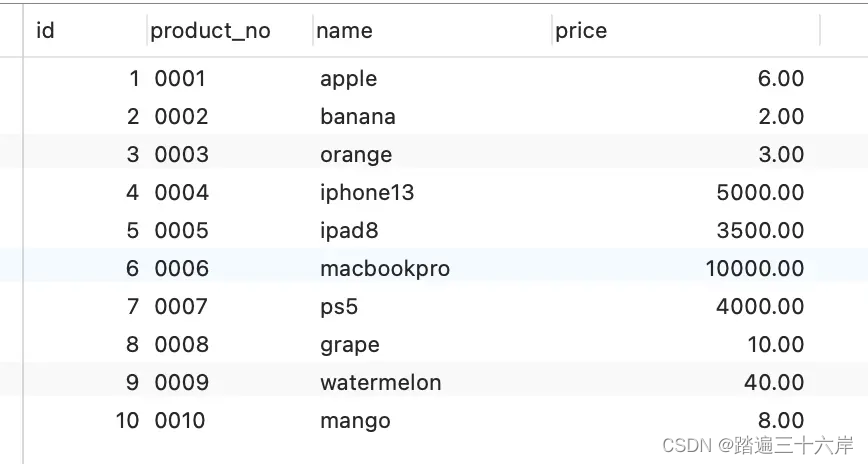
这些行数据,存储在 B+Tree 索引时是长什么样子的?
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都有两个指针,分别指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
主键索引的 B+Tree 如图所示(图中叶子节点之间我画了单向链表,但是实际上是双向链表,原图我找不到了,修改不了,偷个懒我不重画了,大家脑补成双向链表就行):
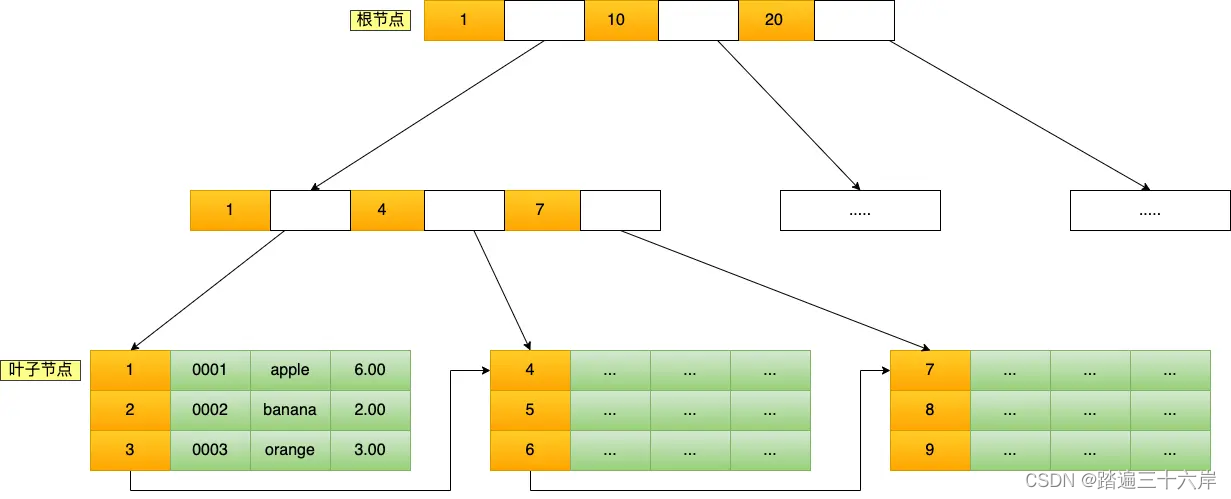
通过主键查询商品数据的过程
比如,我们执行了下面这条查询语句:
select * from product where id= 5;
这条语句使用了主键索引查询 id 号为 5 的商品。查询过程是这样的,B+Tree 会自顶向下逐层进行查找:
- 将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,所以根据 B+Tree的搜索逻辑,找到第二层的索引数据 (1,4,7);
- 在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,所以找到第三层的索引数据(4,5,6);
- 在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的行数据。
数据库的索引和数据都是存储在硬盘的,我们可以把读取一个节点当作一次磁盘 I/O 操作。那么上面的整个查询过程一共经历了 3 个节点,也就是进行了 3 次 I/O 操作。
B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,这意味着从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O,所以B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。
通过二级索引查询商品数据的过程
主键索引的 B+Tree 和二级索引的 B+Tree 区别如下:
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
我这里将前面的商品表中的 product_no (商品编码)字段设置为二级索引,那么二级索引的 B+Tree 如下图(图中叶子节点之间我画了单向链表,但是实际上是双向链表,原图我找不到了,修改不了,偷个懒我不重画了,大家脑补成双向链表就行)。
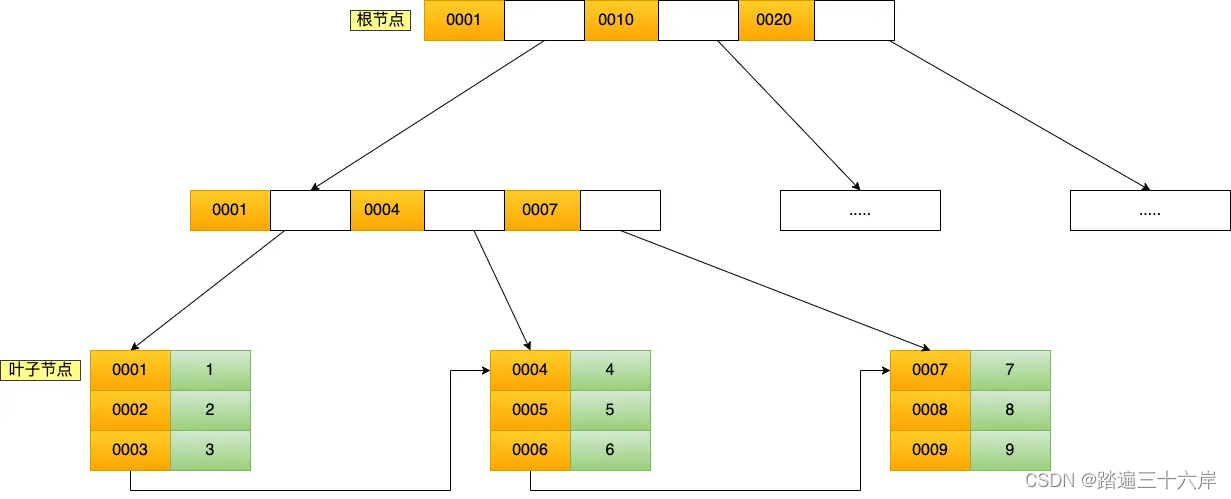
其中非叶子的 key 值是 product_no(图中橙色部分),叶子节点存储的数据是主键值(图中绿色部分)。
如果我用 product_no 二级索引查询商品,如下查询语句:
select * from product where product_no = '0002';
会先检二级索引中的 B+Tree 的索引值(商品编码,product_no),找到对应的叶子节点,然后获取主键值,然后再通过主键索引中的 B+Tree 树查询到对应的叶子节点,然后获取整行数据。这个过程叫「回表」,也就是说要查两个 B+Tree 才能查到数据。如下图(图中叶子节点之间我画了单向链表,但是实际上是双向链表,原图我找不到了,修改不了,偷个懒我不重画了,大家
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









