







 本文介绍了一个基于Prometheus的完整监控解决方案部署过程,包括容器编排、数据采集、报警规则配置及通知推送等内容。
本文介绍了一个基于Prometheus的完整监控解决方案部署过程,包括容器编排、数据采集、报警规则配置及通知推送等内容。
目录结构
[root@node1 ~]# tree prom
prom
├── docker-compose.yml #docker-compose文件
├── grafana #grafana数据挂载
├── prometheus_data #Prometheus数据挂载
├── rules #报警规则文件
│ ├── cpu_over.yml
│ ├── disk_over.yml
│ ├── memory_over.yml
│ └── node_alived.yml
└── yml
├── alertmanager.yml alertmanager配置
├── config.yml 钉钉机器人配置
└── prometheus.yml Prometheus配置
[root@node1 prom]# cat docker-compose.yml
version: "3.7"
services:
node-exporter:
image: prom/node-exporter:latest
container_name: "node-exporter"
ports:
- "9100:9100"
restart: always
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
restart: always
ports:
- '8080:8080'
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
restart: always
volumes:
- "./yml/prometheus.yml:/etc/prometheus/prometheus.yml"
- "./prometheus_data:/prometheus"
- "./rules:/etc/prometheus/rules"
grafana:
image: grafana/grafana
container_name: "grafana"
ports:
- "3000:3000"
restart: always
volumes:
- "./grafana:/var/lib/grafana"
alertmanager:
image: prom/alertmanager:latest
restart: "always"
ports:
- 9093:9093
container_name: "alertmanager"
volumes:
- "./yml/alertmanager.yml:/etc/alertmanager/alertmanager.yml"
webhook:
image: timonwong/prometheus-webhook-dingtalk
restart: "always"
ports:
- 8060:8060
container_name: "webhook"
volumes:
- "./yml/config.yml:/etc/prometheus-webhook-dingtalk/config.yml"
[root@node1 prom]# cat yml/prometheus.yml
# my global config
global: # 此片段指定的是prometheus的全局配置, 比如采集间隔,抓取超时时间等.
scrape_interval: 1m # 抓取间隔 默认1m
evaluation_interval: 1m # 评估规则间隔 默认1m
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
# 此片段指定报警配置, 这里主要是指定prometheus将报警规则推送到指定的alertmanager实例地址
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.10.10:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/etc/prometheus/rules/*.yml" #报警规则文件
# - "cpu_over.yml"
# - "disk_over.yml"
# - "memory_over.yml"
# - "node_alived.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
# 抓取配置列表
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "linux"
static_configs:
- targets: ["192.168.10.10:9100","192.168.10.10:8080","192.168.10.20:9100","192.168.10.20:8080"]
[root@node1 prom]#cat alertmanager.yml
global:
resolve_timeout: 5m #在指定时间内没有新的事件就发送恢复通知
route:
receiver: webhook #设置接收人
group_wait: 1m #组告警等待时间。在等待时间结束后,如果有同组告警一起发出
group_interval: 1m #两组告警间隔时间。
repeat_interval: 1m #重复告警间隔时间,减少相同邮件的发送频率。
group_by: [alertname] #采用那个标签来作为分组。
receivers: #通知接收者列表
- name: webhook
webhook_configs:
- url: http://192.168.10.10:8060/dingtalk/webhook1/send
send_resolved: true
#########################################################
[root@node1 prom]# cat yml/config.yml
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=XXXXXX #webhook
secret: SEC000000 #加签
[root@node1 prom]# cat rules/rules.yml
groups:
- name: CPU报警规则
rules:
- alert: CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 50
for: 1m
labels:
severity: warning
annotations:
summary: "CPU使用率正在飙升。"
description: "CPU使用率超过50%(当前值:{{ $value }}%)"
- name: 磁盘使用率报警规则
rules:
- alert: 磁盘使用率告警
expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"} / node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 80
for: 20m
labels:
severity: warning
annotations:
summary: "硬盘分区使用率过高"
description: "分区使用大于80%(当前值:{{ $value }}%)"
- name: 内存报警规则
rules:
- alert: 内存使用率告警
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 50
for: 1m
labels:
severity: warning
annotations:
summary: "服务器可用内存不足。"
description: "内存使用率已超过50%(当前值:{{ $value }}%)"
- name: 实例存活告警规则
rules:
- alert: 实例存活告警
expr: up == 0
for: 10s
labels:
user: prometheus
severity: warning
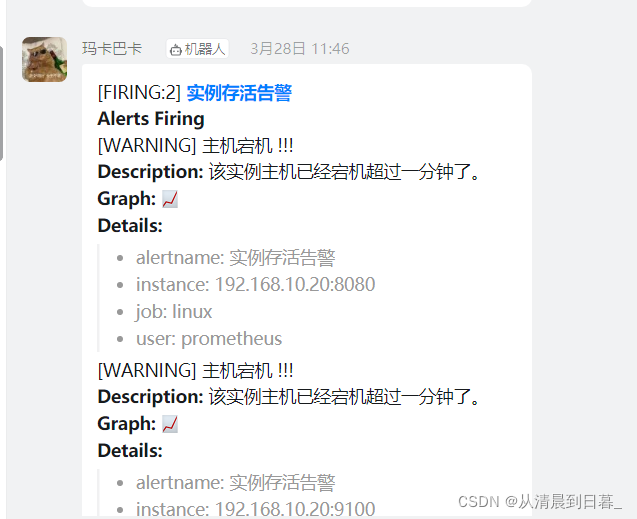
annotations:
summary: "主机宕机 !!!"
description: "该实例主机已经宕机超过一分钟了。"
配置完成后docker-compose up -d 启动容器
http://localhost:8080 #cadvisor
http://localhost:8080/metrics #cadvisor数据
http://localhost:9100/metrics #node-exporter数据
http://localhost:9090 #prometheus
http://localhost:3000 #grafana
http://localhost:9090/alerts 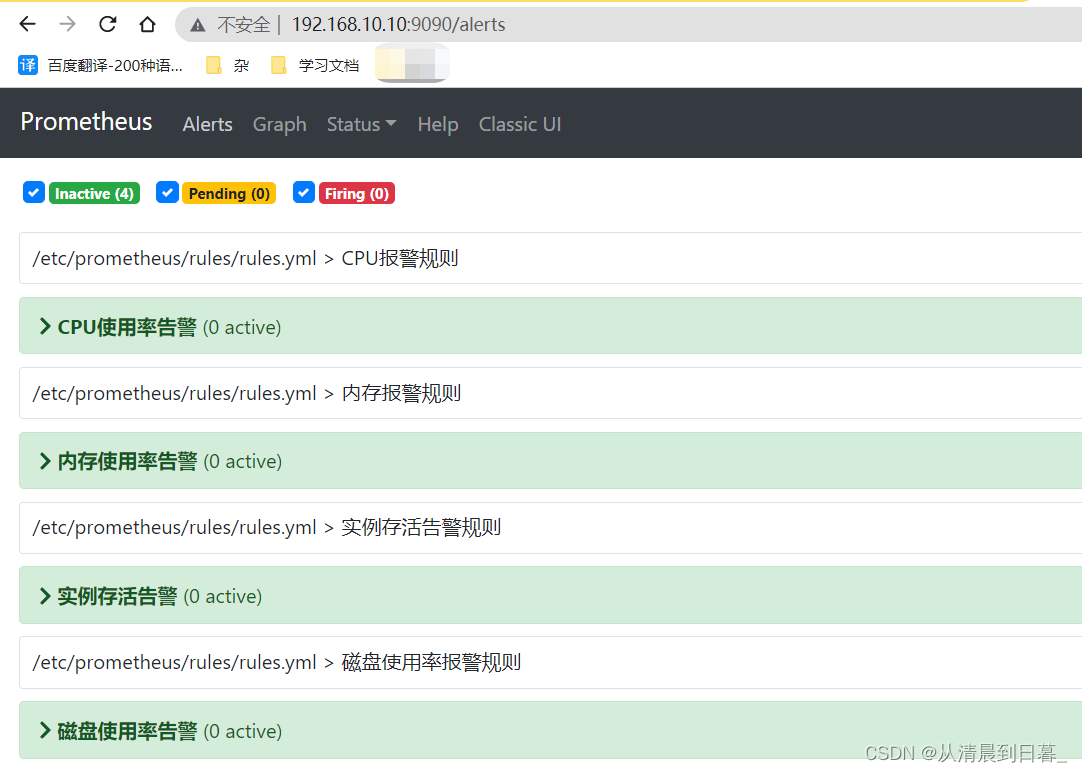
实现效果

















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









