




 本文探讨了MapReduce如何处理海量数据的计算,尤其是Map阶段并行处理,以及HDFS作为分布式存储系统的作用。Yarn资源管理器的角色,包括ResourceManager和Container,被详细阐述。重点在于这三个组件在大数据处理中的协作与整合。
本文探讨了MapReduce如何处理海量数据的计算,尤其是Map阶段并行处理,以及HDFS作为分布式存储系统的作用。Yarn资源管理器的角色,包括ResourceManager和Container,被详细阐述。重点在于这三个组件在大数据处理中的协作与整合。
1.MapReduce的诞生是为解决海量数据的计算Map阶段并行处理输入数据。
①每一个MapTask独立工作
②自己监视自己
Reduce阶段是对Map结果进行汇总,结果显示在磁盘上。
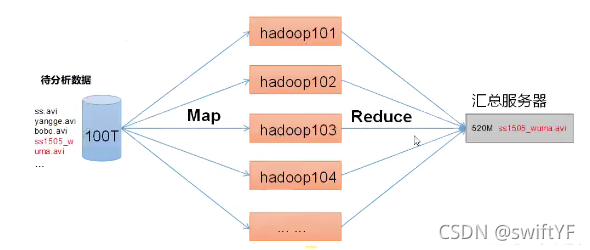
2.HDFS是解决海量数据的存储问题。(分布式文件系统)

1)NameNode:对外暴露存储在该结点,存储的是相关信息
2)DataNode:负责数据实实在在的的存储。
3)2NN:备份一部分。
3.Yarn是资源协调者,是hadoop的资源管理器。

1)ResourceManage:负责整个集群的资源的管理。
2)contianer:是NoderManage的一部分,主要是找ResourceManager申请资源调配。
3)client:用户发布任务。
4.MapReduce、HDFS和Yarn的结合说明:


















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









