




 本文分享了一台服务器接口访问卡顿甚至不通问题的排查过程。通过jps、top等命令定位到CPU消耗大的线程,发现JVM垃圾清理线程耗资源,Full gc次数多且耗时久。怀疑内存泄漏,dump内存分析后,发现内存设置过小,放大内存设置后问题解决。
本文分享了一台服务器接口访问卡顿甚至不通问题的排查过程。通过jps、top等命令定位到CPU消耗大的线程,发现JVM垃圾清理线程耗资源,Full gc次数多且耗时久。怀疑内存泄漏,dump内存分析后,发现内存设置过小,放大内存设置后问题解决。
出现了一台服务器接口访问太卡,甚至访问不通的问题。
排查了半天终于找出原因,现将过程分享如下:
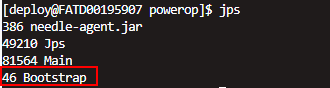
1、Jps 查询java进程号,Bootstrap为tomcat线程
jps
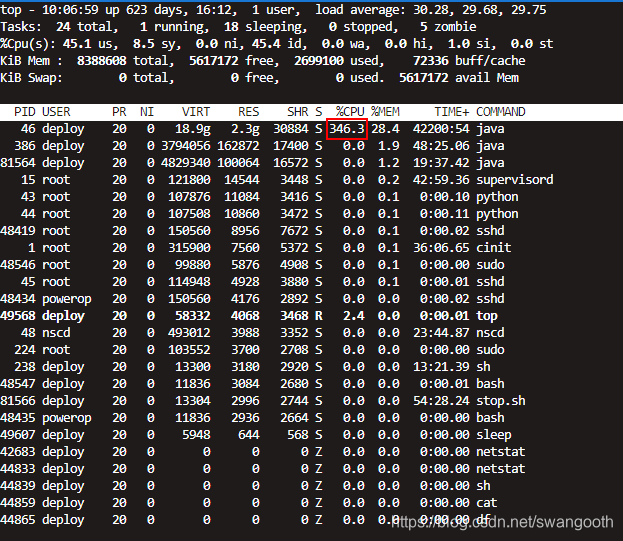
2、top 查询各个进程cpu使用情况
top
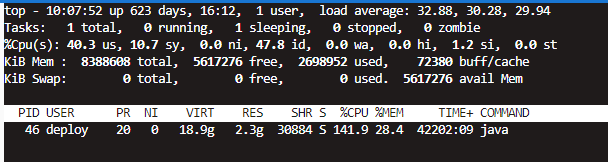
3、top –p 46 查询46号进程单独的cpu使用情况
Shift + H 切换到该进程号内部各个线程的cpu使用情况,且按照CPU使用率逆序排列
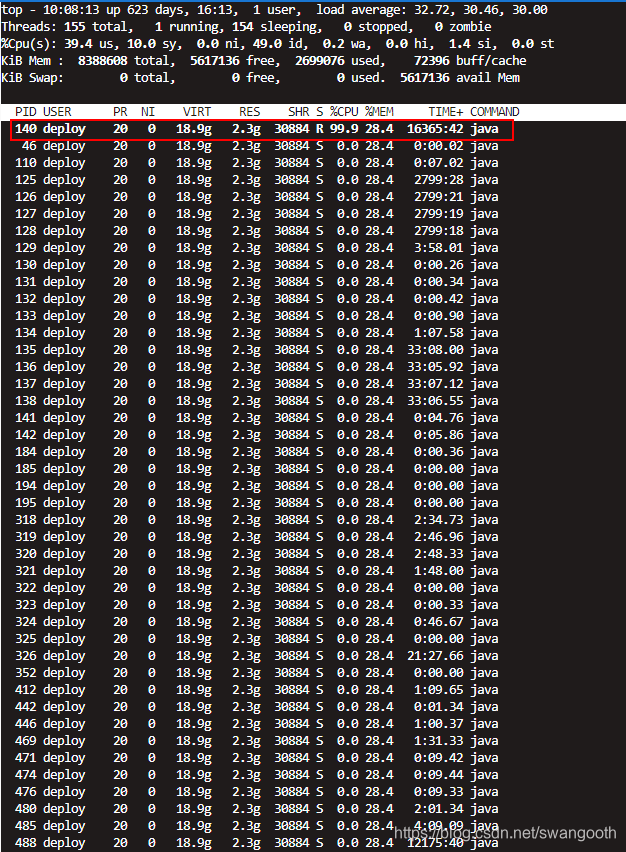
4、pid 140 cup消耗大 查看该线程干什么
Printf %x 140 结果是:8c, 加上16进制标记0x,所以结果是:0x8c
![]()
使用jstack命令打印线程堆栈信息,找到其中nid=0x8c的线程堆栈。
jstack 46 |grep 0x8c –C30

Jvm的垃圾清理线程,非常耗资源。
查看垃圾清理情况:
jstat -gcutil 46
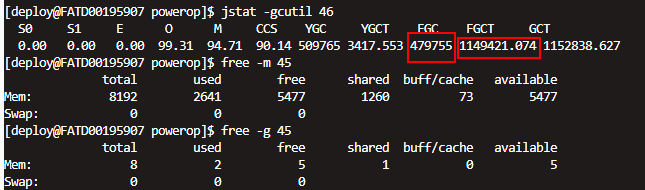
Full gc次数太多,耗时太长。
首先想到内存泄漏,所以要dump内存。
jmap -histo:live 46 | more
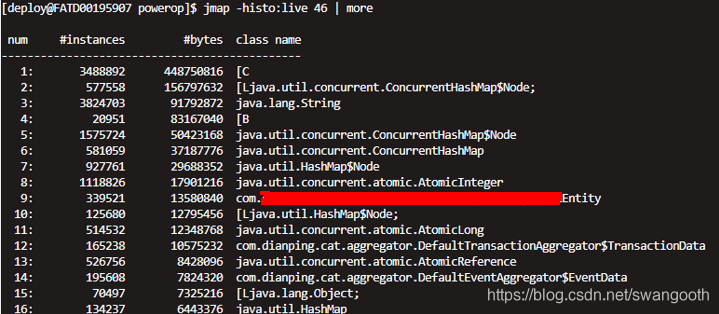
找到一个Entity对象,仔细分析该对象,不过是一个框架对象,会消耗内存,但是不会有内存泄漏这么严重的问题。
再仔细计算一下所占内存大小。
448750816 427M
156797632 149M
91792872 87M
MockEntity所占内存大小,13580840仔细计算 12.95M
排在前面的几个内存加在一起也才1G左右,一个8G内存的dock怎么会被1G内存撑到内存溢出了,首先怀疑的是内存设置过小,
此时通过jinfo pid 查询当前jvm内存设置,
命令为:jinfo 46
总大小设置为:
-Xmx1024M -Xms1024M -Xss512K

将其放大,问题解决。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









