







目录
1、什么是散列?
顺序文件组织的一个缺点是我们必须访问索引结构来定位数据,或者必须使用二分法搜索,这将导致过多的 I/O 操作。基于散列(hashing)技术的文件组织使我们能够避免访问索引结构。//使用散列可以减少查找的次数。所谓散列,其实就是键值对的映射,而映射效果由散列函数决定
在散列中,散列桶(bucket)用来表示能存储一条或多条记录的一个存储单位。通常一个桶就是一个磁盘块,但也可能小于或大于一个磁盘块。
正规地说,令 K 表示所有搜索码值的集合,令 B 表示所有桶地址的集合,散列函数就是一个从 K 到 B 的函数。我们用 h 表示散列函数。
为了插人一条搜索码为 的记录,我们计算
,它给出了存放该记录的桶的地址。我们目前假定桶中有容纳这条记录的空间,于是这条记录就存储到该桶中。//插入
为了进行一次基于搜索码值 的查找,我们只需计算
,然后搜索具有该地址的桶。假定两个搜索码
和
有相同的散列值,即
=
。如果我们执行对
的查找,则桶
包含搜索码值是
以及
的记录。因此,我们必须检查桶中每条记录的搜索码值,以确定该记录是否是我们要查找的记录。//查询,注意可能出现hash冲突
删除也一样简单。如果待删除记录的搜索码值是,则计算
,然后在相应的桶中查找此记录并从中删除它。
//使用好的散列函数一般来说可以避免繁琐的查询过程,使查询一步到位
2、如何评价一个散列函数的好坏?
最坏的可能是散列函数把所有的搜索码值映射到同一桶中。这种函数并不是我们所期望的,因为所有的记录不得不存放到同一个桶里。查找一个需要的记录时将不得不检查所有记录。//此时的散列就像退化成了一个链表,散列函数没有任何的散列效果
理想的散列函数需要达到的效果:
理想的散列函数把存储的码均匀地分布到所有桶中,使每个桶含有相同数目的记录。
由于设计时我们无法精确知道文件中将存储哪些搜索码值,因此我们希望选择一个把搜索码值分配到桶中并且具有下列分布特性的散列函数。
- 分布是均匀的。即散列函数从所有可能的搜索码值集合中为每个桶分配同样数量的搜索码值
- 分布是随机的。即在一般情况下,不管搜索码值实际怎样分布,每个桶应分配到的搜索码值数目几乎相同。更确切地说,散列值不应与搜索码的任何外部可见的排序相关,例如按字母的顺序或按搜索码长度的顺序。散列函数应该表现为随机的。
//散列函数的设计有一定的困难,可能需要针对特定的场景进行特定的设定,但是搜索码具有随机性,又很难做到有放之四海而皆准的散列函数
3、散列中的桶溢出处理
当插人一条记录时,记录映射到的桶有存储记录的空间。如果桶没有足够的空间,就会发生桶溢出(bucket overflow)。
处理桶溢出一般有两种方案,即闭地址(close addressing)方案和开地址(open addressing)方案。
所谓的闭地址法也被称为链地址法(Chaining)。在这种方法中,每个哈希表的槽(bucket)是一个链表。当多个键被哈希到同一个槽时,这些键会被存储在该槽的链表中。
比如,我们可以用溢出桶来处理桶溢出问题。如果一条记录必须插入桶 b 中,而桶 b 已满,系统会为桶 b 提供一个溢出桶,并将此记录插人到这个溢出桶中。如果溢出桶也满了,系统会提供另一个溢出桶,如此继续下去。一个给定桶的所有溢出桶用一个链接列表链接在一起,如下图所示:
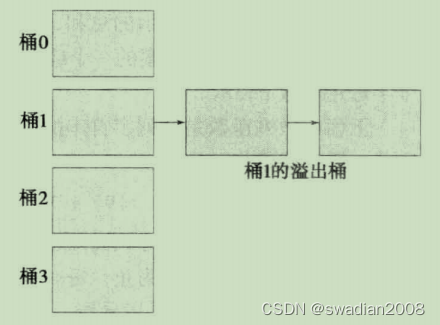
闭地址方案容易实现,但是有额外的链表存储开销。如果链表长度增加时,查找时间可能变长。
另一种方案就是开地址。开地址通过寻找其他空闲槽来处理冲突。在这种方法中,当一个槽已经被占用时,系统会根据一定的探测(probing)策略来寻找下一个可用的槽。
开地址方案的好处是不需要链表,从而节省存储空间。但是在高负载因子下,探测序列变长,性能会出现明显的下降,所以需要有良好的探测策略以避免群聚(clustering)现象。
群聚(Clustering)现象在哈希表中指的是由于哈希冲突处理方法导致一系列相邻槽变得拥挤,从而影响哈希表的性能。这种现象主要出现在线性探测和二次探测中。
4、散列在索引中的应用
散列不仅可以用于文件的组织,还可以用于索引结构的创建。散列索引(hash index)将搜索码及其相应的指针组织成散列文件结构。
我们可以按如下方法构建数据库的散列索引。将散列函数作用于搜索码以确定对应的桶,然后将此搜索码以及相应指针存入此桶(或溢出桶)中。
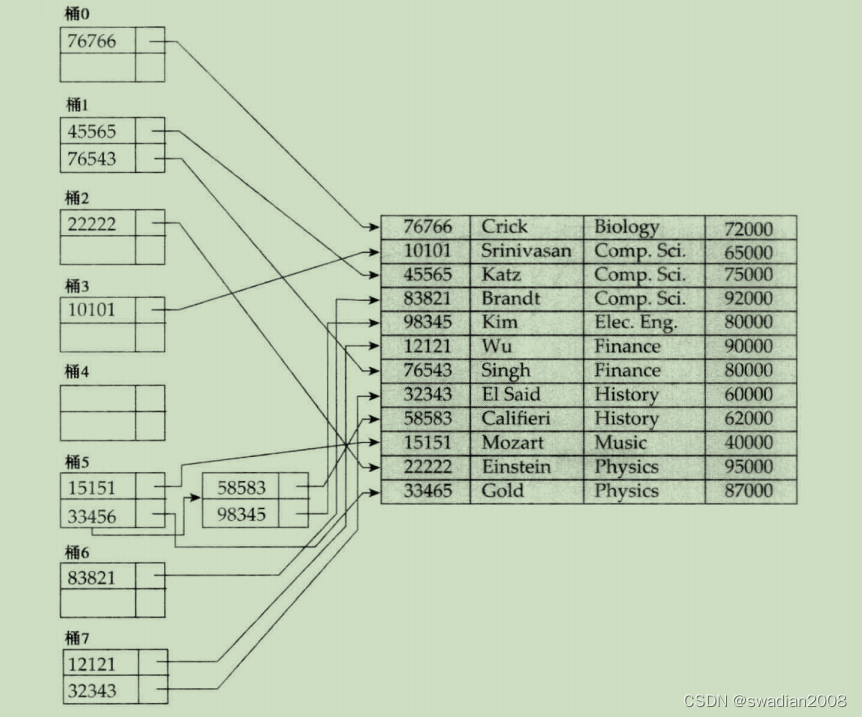
下图给出了 instructor 文件上的一个辅助散列索引,其搜索码是 ID。图中的散列函数计算 ID 的各位数字之和对 8 取模的结果。该散列索引有 8 个桶,每个桶的大小为 2。其中一个桶有三个码映射到它,因此它有一个溢出桶。在这个例子中,ID 是 instructor 的主码,所以每个搜索码只对应一个指针。一般情况下,每个码可能对应多个指针。//其实就是Hash表
4、顺序索引和散列索引的比较
顺序索引,是一种基于树的索引,最常见的是 B- 树和 B+ 树索引。它与散列索引最大的区别就在于顺序索引支持范围查询和排序,精确匹配的效率也尚可接受,更具通用性。//比如Mysql、PostgreSQL数据库等
散列索引不支持范围查找和排序,虽然精确查找效率高,但是相比来说通用性更差。因此,散列索引更适用于需要快速查找的场景,比如缓存系统(Memcached 和 Redis等)。
以下是顺序索引和散列索引的简单对比表:
| 特性 | 顺序索引 | 散列索引 |
|---|---|---|
| 数据存储顺序 | 有序存储 | 无序存储 |
| 支持的查询类型 | 范围查询、排序、精确匹配 | 精确匹配 |
| 查询效率 | O(log n) | O(1) |
| 插入/删除效率 | O(log n) | O(1) |
| 结构类型 | B-树或 B+树结构 | 哈希表结构 |
| 适用场景 | 范围查询、排序查询、唯一性约束 | 精确匹配查询、高频查找操作 |
| 不支持的操作 | N/A | 范围查询、排序查询 |
| 维护成本 | 较高 | 较低 |
| 空间利用率 | 较高 | 取决于哈希函数和哈希表大小 |
至此,全文结束。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











