






 在高并发场景下,System.currentTimeMillis()的性能表现远低于预期,由于系统时钟源的争用,其耗时甚至超过对象创建。本文通过实验对比单线程与并发调用的耗时差异,深入探讨了其背后的原因,包括用户态到内核态的切换、时钟源的选择(HPET vs TSC)及全局时钟源的争用问题。
在高并发场景下,System.currentTimeMillis()的性能表现远低于预期,由于系统时钟源的争用,其耗时甚至超过对象创建。本文通过实验对比单线程与并发调用的耗时差异,深入探讨了其背后的原因,包括用户态到内核态的切换、时钟源的选择(HPET vs TSC)及全局时钟源的争用问题。
好记忆不如烂笔头,能记下点东西,就记下点,有时间拿出来看看,也会发觉不一样的感受.
System.currentTimeMillis()是极其常用的基础Java API,广泛地用来获取时间戳或测量代码执行时长等,在我们的印象中应该快如闪电。但实际上在并发调用或者特别频繁调用它的情况下(比如一个业务繁忙的接口,或者吞吐量大的需要取得时间戳的流式程序),其性能表现会令人大跌眼镜。直接看下面的Demo。
public class CurrentTimeMillisPerfDemo {
private static final int COUNT = 100;
public static void main(String[] args) throws Exception {
long beginTime = System.nanoTime();
for (int i = 0; i < COUNT; i++) {
System.currentTimeMillis();
}
long elapsedTime = System.nanoTime() - beginTime;
System.out.println("100 System.currentTimeMillis() serial calls: " + elapsedTime + " ns");
CountDownLatch startLatch = new CountDownLatch(1);
CountDownLatch endLatch = new CountDownLatch(COUNT);
for (int i = 0; i < COUNT; i++) {
new Thread(() -> {
try {
startLatch.await();
System.currentTimeMillis();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
endLatch.countDown();
}
}).start();
}
beginTime = System.nanoTime();
startLatch.countDown();
endLatch.await();
elapsedTime = System.nanoTime() - beginTime;
System.out.println("100 System.currentTimeMillis() parallel calls: " + elapsedTime + " ns");
}
}
执行结果如下图。
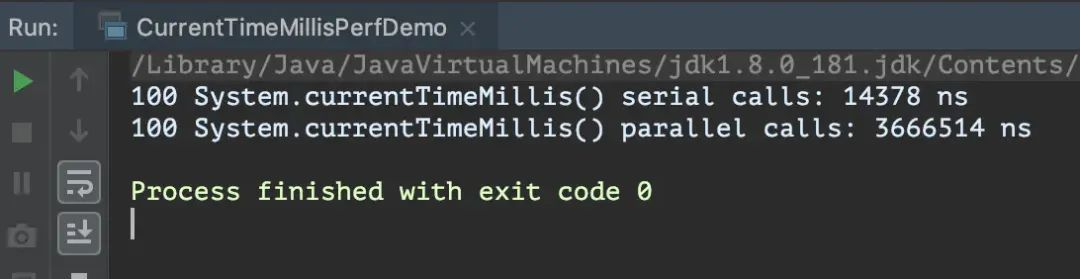
image.png
可见,并发调用System.currentTimeMillis()一百次,耗费的时间是单线程调用一百次的250倍。如果单线程的调用频次增加(比如达到每毫秒数次的地步),也会观察到类似的情况。实际上在极端情况下,System.currentTimeMillis()的耗时甚至会比创建一个简单的对象实例还要多,看官可以自行将上面线程中的语句换成new HashMap<>之类的试试看。
为什么会这样呢?来到HotSpot源码的hotspot/src/os/linux/vm/os_linux.cpp文件中,有一个javaTimeMillis()方法,这就是System.currentTimeMillis()的native实现。
jlong os::javaTimeMillis() {
timeval time;
int status = gettimeofday(&time, NULL);
assert(status != -1, "linux error");
return jlong(time.tv_sec) * 1000 + jlong(time.tv_usec / 1000);
}
挖源码就到此为止,因为已经有国外大佬深入到了汇编的级别来探究,详情可以参见《The Slow currentTimeMillis()》这篇文章,我就不班门弄斧了。简单来讲就是:
-
调用gettimeofday()需要从用户态切换到内核态;
-
gettimeofday()的表现受Linux系统的计时器(时钟源)影响,在HPET计时器下性能尤其差;
-
系统只有一个全局时钟源,高并发或频繁访问会造成严重的争用。
HPET计时器性能较差的原因是会将所有对时间戳的请求串行执行。TSC计时器性能较好,因为有专用的寄存器来保存时间戳。缺点是可能不稳定,因为它是纯硬件的计时器,频率可变(与处理器的CLK信号有关)。关于HPET和TSC的细节可以参见https://en.wikipedia.org/wiki/High_Precision_Event_Timer与https://en.wikipedia.org/wiki/Time_Stamp_Counter。
另外,可以用以下的命令查看和修改时钟源。
~ cat /sys/devices/system/clocksource/clocksource0/available_clocksource
tsc hpet acpi_pm
~ cat /sys/devices/system/clocksource/clocksource0/current_clocksource
tsc
~ echo 'hpet' > /sys/devices/system/clocksource/clocksource0/current_clocksource
如何解决这个问题?最常见的办法是用单个调度线程来按毫秒更新时间戳,相当于维护一个全局缓存。其他线程取时间戳时相当于从内存取,不会再造成时钟资源的争用,代价就是牺牲了一些精确度。具体代码如下。
public class CurrentTimeMillisClock {
private volatile long now;
private CurrentTimeMillisClock() {
this.now = System.currentTimeMillis();
scheduleTick();
}
private void scheduleTick() {
new ScheduledThreadPoolExecutor(1, runnable -> {
Thread thread = new Thread(runnable, "current-time-millis");
thread.setDaemon(true);
return thread;
}).scheduleAtFixedRate(() -> {
now = System.currentTimeMillis();
}, 1, 1, TimeUnit.MILLISECONDS);
}
public long now() {
return now;
}
public static CurrentTimeMillisClock getInstance() {
return SingletonHolder.INSTANCE;
}
private static class SingletonHolder {
private static final CurrentTimeMillisClock INSTANCE = new CurrentTimeMillisClock();
}
}
使用的时候,直接CurrentTimeMillisClock.getInstance().now()就可以了。不过,在System.currentTimeMillis()的效率没有影响程序整体的效率时,就不必忙着做优化,这只是为极端情况准备的。

















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









