






作用:
数据结构和算法大大的提高的代码的效率,使得代码更加规范。
算法的五大特征:
- 输入: 算法具有0个或多个输入
- 输出: 算法至少有1个或多个输出
- 有穷性: 算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成
- 确定性:算法中的每一步都有确定的含义,不会出现二义性
- 可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
算法效率衡量:
实现算法程序的执行时间可以反应出算法的效率,但是单靠时间并不能客观准确判断,为了创立一个标准,定义了“时间复杂度”
时间复杂度:每天机器执行时间不同,但是基本运算数量基本相同,用运算数量来判断时间复杂度
在效率判断时,我们需要关注最坏时间复杂度。提供了一个保证
时间复杂度的基本计算规则:
- 基本操作,即只有常数项,认为其时间复杂度为O(1)
- 顺序结构,时间复杂度按加法进行计算
- 循环结构,时间复杂度按乘法进行计算
- 分支结构,时间复杂度取最大值
- 判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
- 在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度
大O表示法:
用0(n²)来表示n²所带的系数和常数
常见时间复杂度之间的关系:
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) <O(n2log(n)) < O(n3) < O(2n) < O(n!) < O(n的n次方)
list和字典内置操作时间复杂度
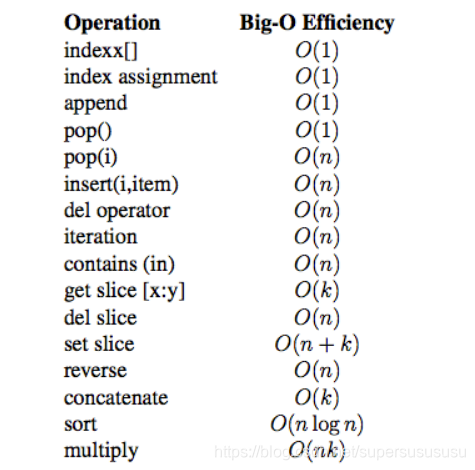

数据结构引用
不同数据结构引用的办法不同,列表字典元组等都已经是数据结构而不是简单的基本类型
抽象数据类型:
把数据类型和数据类型上的运算捆在一起,进行封装,例如:插入,删除等

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









