



Mysql
1.死锁问题
1.批量行锁引发的死锁
表结构
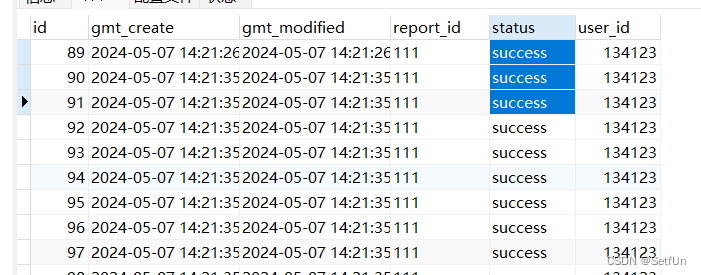
如图:
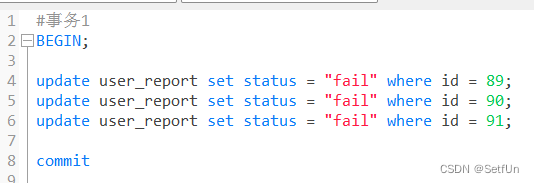
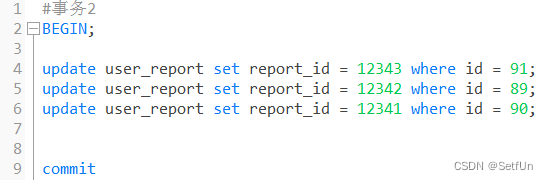
| 事务 1 | 事务2 |
| 执行2,4(id=89的索引添加行锁) | |
| 执行2,4(id=91的索引添加了行锁) | |
| 执行5(id=90的索引添加了行锁) | |
| 执行5(线程进入阻塞状态,id=89的索引在事务1已经获取锁了) | |
| 执行6(id=91的索引数据已经被事务2上锁了) | |
| 线程相互等待:死锁 |
解决办法:
- 使用in语句 update user_report set status = "fail" where id in (91,89,90) mysql会有优化器自动使批量语句按照同一顺序执行
- 拆表,事务1改的是status字段 事务2改的是report_id字段 直接把report_id拆到别的表里就可以避免对同一条数据进行操作而造成死锁
2.间隙锁引发的死锁问题
出现死锁原因总结:间隙锁之间不不互斥,间隙锁和行锁互斥
表数据
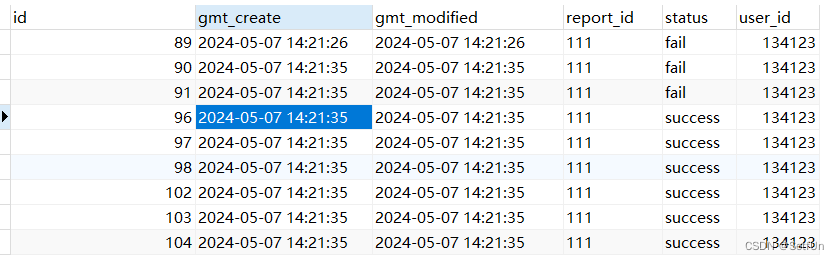
在Mysql 5.6 版本下,可重复度隔离级别下


| 事务 1 | 事务2 |
| 执行2,3(直接在id(91,96)中间上了间隙锁) | |
| 执行2,3(直接在id(91,96)中间上了间隙锁)因为间隙锁不互斥所以可以创建第二把锁 | |
| 执行5(进入阻塞状态,他需要事务2释放事务2的间隙锁) | |
| 执行5(他需要事务1释放事务1的间隙锁),导致死锁 |
解决办法:
- 降低事务隔离级别可以到 读已提交
- 使用分布式锁 ,不要在查询语句里加锁(不要加for update)
3.普通索引回表引发死锁问题
腾讯云数据库的事务隔离级别都是RC的
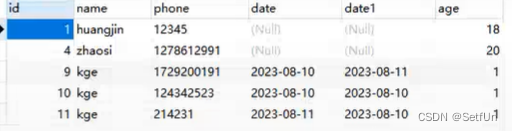
这么一张表
有一个name_date的联合索引,还有一个id的主键索引
事务1 update user set name = "a" where name = "kge" and date1>="2023-08-10" and phone = "214231";
update user set name = "qwe" where name = "kge" and date1="2024-08-10"
事务2 update user set name="aaa" where name = "kge" and date1>=2023-08-10 and phone = "124342523"
4.索引合并引发的死锁问题 merge_index
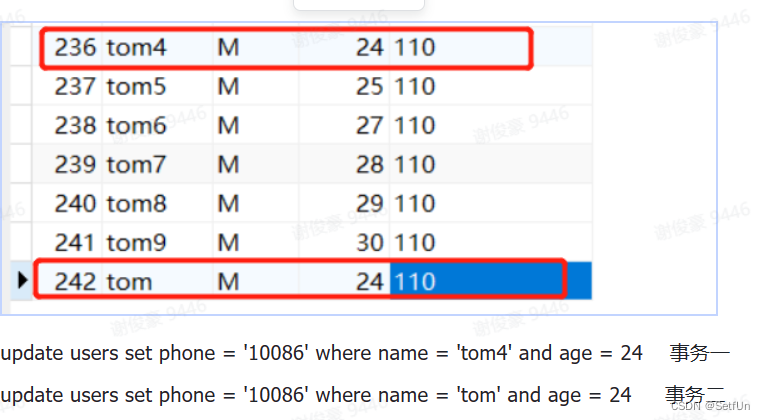
| 事务1 | 事务2 |
| 锁住idx_name索引中的name为tom4的索引项 | |
| 锁住idx_name索引中的name为tom的索引项 | |
| 回表锁住Primary索引|中的id为236的索引项 | |
| 回表锁住Primary索引中的id为242的索引项 | |
| 锁住idx_age索引|中的age为24的索引项 | |
| 试图锁住idx_age索引中的age为24的索引项,发现该索引项目锁住了,等事务一释放age为24的索引项 | |
| 试图回表锁住Primary索引引中的id为242,236的索引项。发现242索引被事务二锁住了,等待释放。 | |
| 导致死锁了。 |
Spring源码
1.谈谈Spring IOC的理解,原理与实现?
总:
控制反转:理论思想,原来的对象是由使用者来进行控制,有了spring之后,可以把整个对象交给spring来帮我们进行管理
Dl:依赖注入,把对应的属性的值注入到具体的对象中,@Autowired,populateBean完成属性值的注入
容器:存储对象,使用map结构来存储,在spring中一般存在三级缓存,singletonobjects存放完整的bean对象,整个bean的生命周期,从创建到使用到销毁的过程全部都是由容器来管理(bean的生命周期)
分:
1、一般聊ioc容器的时候要涉及到容器的创建过程(beanFactory,DefaultListableBeanFactory),向bean工厂中设置一些些参数(BeanPostProcessor,Aware接口的子类)等等属性
2、加载解析bean对象,准备要创建的bean对象的定义对象beanDefinition,(xml或者注解的解析过程)
3、beanFactoryPostProcessor的处理,此处是扩展点,PlaceHolderConfigurSupport,ConfigurationClassPostProcessor
4、BeanPostProcessor的注册功能,方便后续对bean对象完成具体的扩展功能
5、通过反射的方式讲BeanDefinition对象实例化成具体的bean对象,
6、bean对象的初始化过程(填充属性,调用aware子类的方法,调用BeanPostProcessor前置处理方法,调用init-mehtod方法,调用BeanPostProcessor的后置处理方法)
7、生成完整的bean对象,通过getBean方法可以直接获取
8、销毁过程
面试官,这是我对ioc的整体理解,包含了一些详细的处理过程,您看一下有什么问题,可以指点我一下(允许你把整个流程说完)
老师,我没看过源码怎么办?
具体的细节我记不太清了,但是spring中的bean都是通过反射的方式生成的,同时其中包含了很多的扩展点,比如最常用的对BeanFactory的扩展,对bean的扩展,我们在公司对这方面的使用是比较多的,除此之外,ioc中最核心的也就是填充具体bean的属性,和生命周期。|
2.谈一下spring IOC的底层实现
反射,工厂,设计模式(会的说,不会的不说),关键的几个方法
createBeanFactory,getBean,doGetBean,createBean,doCreateBean,createBeanlnstance(getDeclaredConstructor,newinstance),populateBean,initializingBean
1、先通过createBeanFactory创建出一个Bean工厂(DefaultListableBeanFactory)
2、开始循环创建对象,因为容器中的bean默认都是单例的,所以优先通过getBean,doGetBean从容器中查找,找不到的话,
3、通过createBean,doCreateBean方法,以反射的方式创建对象,一般情况下使用的是无参的构造方法(getDeclaredConstructor,newlnstance)
4、进行对象的属性填充populateBean
3.描述一下bean的生命周期?
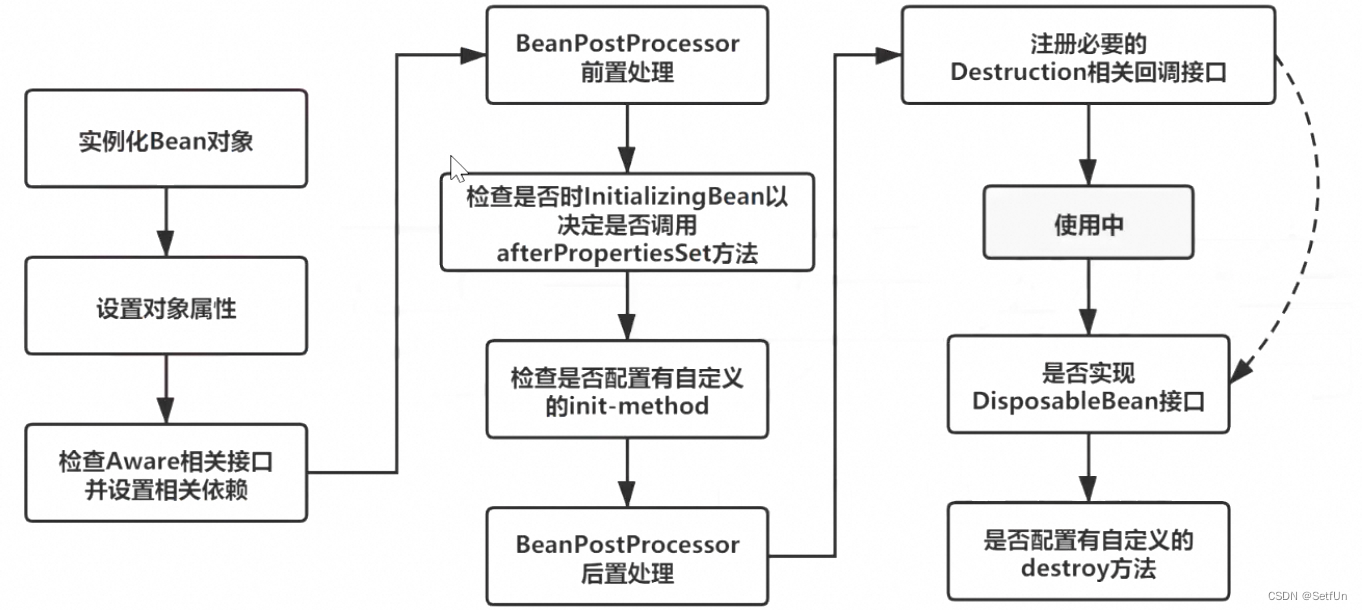
在表述的时候不要只说图中有的关键点,要学会扩展描述
1、实例化bean:反射的方式生成对象
2、填充bean的属性:populateBean(),循环依赖的问题(三级缓存)
3、调用aware接口相关的方法:invokeAwareMethod(完成BeanName,BeanFactory,BeanClassLoader对象的属性设置)
4、调用BeanPostProcessor中的前置处理方法:使用比较多的有(ApplicationContextPostProcessor,设置ApplicationContext,Environment,ResourceLoader,EmbeddValueResolver等对象)
5、调用initmethod方法:invokelnitmethod(),判断是否实现了initializingBean接口,如果有,调用afterPropertiesSet方法,没有就不调用
6、调用BeanPostProcessor的后置处理方法:spring的aop就是在此处实现的,AbstractAutoProxyCreator注册Destuction相关的回调接口
7、获取到完整的对象,可以通过getBean的方式来进行对象的获取
8、销毁流程,1;判断是否实现了DispoableBean接口,2,调用destroyMethod方法
4.Spring是如何解决循环依赖的问题的?
三级缓存,提前暴露对象,aop
总:什么是循环依赖问题,A依赖B,B依赖A
分:先说明bean的创建过程:实例化,初始化(填充属性)
1、先创建A对象,实例化A对象,此时A对象中的b属性为空,填充属性b
2、从容器中查找B对象,如果找到了,直接赋值不存在循环依赖问题(不通),找不到直接创建B对象
3、实例化B对象,此时B对象中的a属性为空,填充属性a
4、从容器中查找A对象,找不到,直接创建
形成闭环的原因
此时,如果仔细琢磨的话,会发现A对象是存在的,只不过此时的A对象不是一个完整的状态,只完成了实例化但是未完成初始化,如果在程序调用过程中,拥有了某个对象的引用,能否在后期给他完成赋值操作,可以优先把非完整状态的对象优先赋值,等待后续操作来完成赋值,相当于提前暴露了某个不完整对象的引用,所以解决问题的核心在于实例化和初始化分开操作,这也是解决循环依赖问题的关键,当所有的对象都完成实例化和初始化操作之后,还要把完整对象放到容器中,此时在容器中存在对象的几个状态,完成实例化=但未完成初始化,完整状态,因为都在容器中,所以要使用不同的map结构来进行存储,此时就有了一级缓存和二级缓存,如果一级缓存中有了,那么二级缓存中就不会存在同名的对象,因为他们的查找顺序是1,2,3这样的方式来查找的。一级缓存中放的是完整对象,二级缓存中放的是非完整对象
为什么需要三级缓存?三级缓存的value类型是objectFactory,是一个函数式接口,存在的意义是保证在整个容器的运行过程中同名的bean对象只能有一个。
如果一个对象需要被代理,或者说需要生成代理对象,那么要不要优先生成一个普通对象?要
普通对象和代理对象是不能同时出现在容器中的,因此当一个对象需要被代理的时候,就要使用代理对象覆盖掉之前的普通对象,在实际的调用过程中,是没有办法确定什么时候对象被使用,所以就要求当某个对象被调用的时候,优先判断此对象是否需要被代理,类似于一种回调机制的实现,因此传入lambda表达式的时候,可以通过lambda表达式来执行对象的覆盖过程,getEarlyBeanReference()
因此,所有的bean对象在创建的时候都要优先放到三级缓存中,在后续的使用过程中,如果需要被代理则返回代理对象,如果不需
要被代理,则直接返回普通对象
4.1.缓存的放置时间和删除时间
三级缓存:createBeanlnstance之后:addSingletonFactory
二级缓存:第一次从三级缓存确定对象是代理对象还是普通对象的时候,同时删除三级缓存getSingleton
一级缓存:生成完整对象之后放到一级缓存,删除二三级缓存:addSingleton
5.Bean Factory与FactoryBean有什么区别?
相同点:都是用来创建Bean对象的
不同点:使用BeanFactory创建对象的时候,必须要遵循严格的生命周期流程,太复杂了,,如果想要简单的自定义某个对象的创建,同时创建完成的对象想交给spring来管理,那么就需要实现FactroyBean接口了
isSingleton:是否是单例对象
getobjectType:获取返回对象的类型
getObject:自定义创建对象的过程(new,反射,动态代理)
6.Spring中用到的设计模式?
单例模式:bean默认都是单例的
原型模式:指定作用域为prototype
工厂模式:BeanFactory
代理模式:动态代理
模板方法:postProcessBeanFactory,onRefresh,initPropertyValue
策略模式:XmlBeanDefinitionReader,PropertiesBeanDefinitionReader
观察者模式:listener,event,multicast
适配器模式:Adapter
装饰者模式:BeanWrapper
责任链模式:使用aop的时候会先生成一个拦截器链
委托者模式:delegate
7.Spring的AOP的底层实现原理?
aop是ioc的一个扩展功能,先有的ioc再有的aop,只是在ioc的整个流程中新增的一个扩展点而已
总:aop概念,应用场景,动态代理
分:
bean的创建过程中有一个步骤可以对bean进行扩展实现,aop本身就是一个扩展功能,所以在BeanPostProcessor的后置处理方法
中来进行实现
1、代理对象的创建过程(advice,切面,切点)
2、通过jdk或者cglib的方式来生成代理对象
3、在执行方法调用的时候,会调用到生成的字节码文件中,直接回找到DynamicAdvisoredlnterceptor类中的intercept方法,从此方法开始执行
4、根据之前定义好的通知来生成拦截器链
5、从拦截器链中依次获取每一个通知开始进行执行,在执行过程中,为了方便找到下一个通知是哪个,会有一个CglibMethodlnvocation的对象,找的时候是从-1的位置一次开始查找并且执行的。
Spring的5种通知
- 前置通知(Before advice) - 在方法执行之前运行的通知,比如用于检查权限。
- 后置通知(After returning advice) - 在方法正常完成后执行的通知,可以访问方法的返回值。
- 异常通知(After throwing advice) - 如果方法通过抛出异常退出,则执行此通知。
- 最终通知(After (finally) advice) - 无论方法通过何种方式退出(正常返回或抛出异常),此通知都会执行,类似于try-catch块中的finally块。
- 环绕通知(Around advice) - 围绕方法执行,可以在方法调用之前和之后执行自定义行为。它可以决定是否继续执行方法,修改返回值,或处理或抛出异常。
8.Spring的事务是如何回滚的?
总:spring的事务是由aop来实现的,首先要生成具体的代理对象,然后按照aop的整套流程来执行具体的操作逻辑,正常情况下要
通过通知来完成核心功能,但是事务不是通过通知来实现的,而是通过一个Transactionlnterceptor来实现的,然后调用invoke来实现具体的逻辑
分:1、先做准备工作,解析各个方法上事务相关的属性,根据具体的属性来判断是否开始新事务
2、当需要开启的时候,获取数据库连接,关闭自动提交功能,开起事务
3、执行具体的sql逻辑操作
4、在操作过程中,如果执行失败了,那么会通过completeTransactionAfterThrowing看来完成事务的回滚操作,回滚的具体逻辑是通过doRollBack方法来实现的,实现的时候也是要先获取连接对象,通过连接对象来回滚
5、如果执行过程中,没有任何意外情况的发生,那么通过commitTransactionAfterReturning来完成事务的提交操作,提交的具体逻辑是通过doCommit方法来实现的,实现的时候也是要获取连接,通过连接对象来提交
6、当事务执行完毕之后需要清除相关的事务信息cleanupTransactionlnfd
9.谈一下spring事务传播?
传播特性有几种?7种
Required,Requires_new,nested,Support,Not_Support,Never,Mandatory
某一个事务嵌套另一个事务的时候怎么办?
A方法调用B方法,AB方法都有事务,并且传播特性不同,那么A如果有异常,B怎么办,B如果有异常,A怎么办?
总:事务的传播特性指的是不同方法的嵌套调用过程中,事务应该如何进行处理,是用同一个事务还是不同的事务,当出现异常的
时候会回滚还是提交,两个方法之间的相关影响,在日常工作中,使用比较多的是required,Requires_new,nested
分:1、先说事务的不同分类,可以分为三类:支持当前事务,不支持当前事务,嵌套事务
工
2、如果外层方法是required,内层方法是,required,requires_new,nested
3、如果外层方法是requires_new,内层方法是,required,requires_new,nested
4、如果外层方法是nested,内层方法是,required,requires_new,nested
Redis
1.说一下你在项目中的redis的应用场景?
先说5种数据结构:
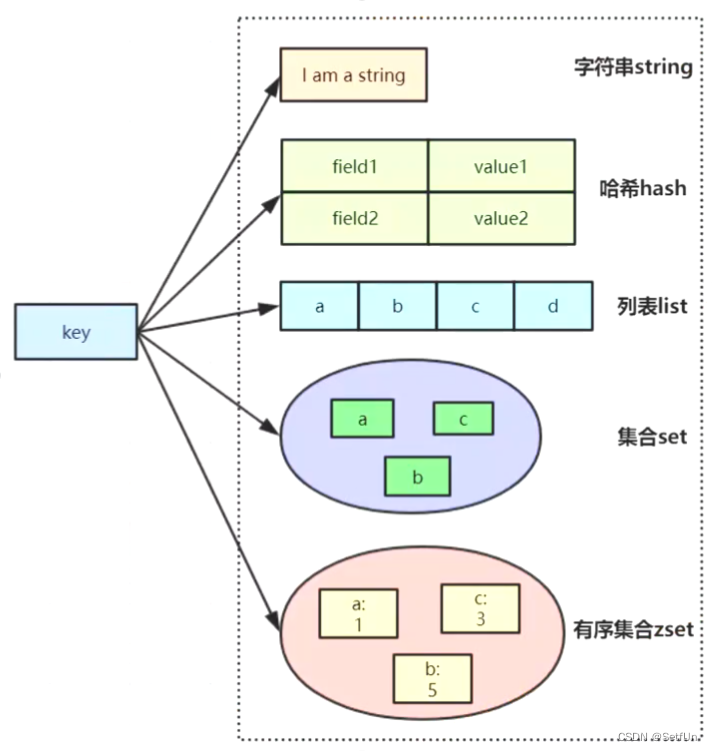
2.Set、Zset分 别用于哪些场景?
3.redis是单线程还是多线程?
redis是单线程的。
redis单线程是如何处理多的并发客户端连接?
Redis的I/O多路复用: redis利用epol来实现0多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
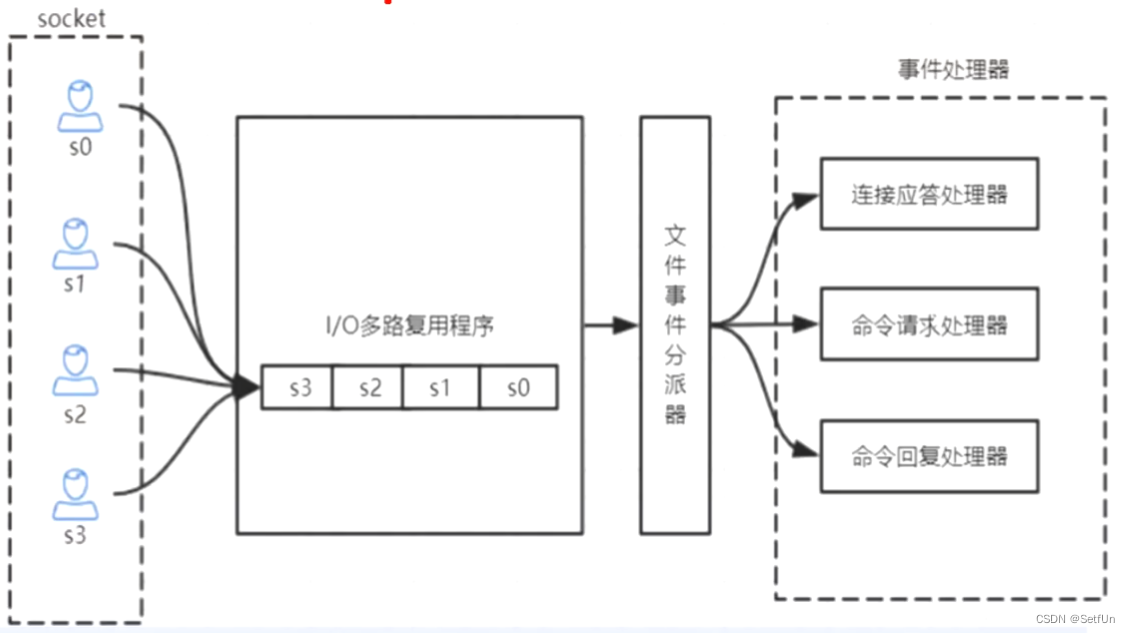
4.redis存在线程安全的问题吗? 为什么?
不存在 因为他是单线程的
5.遇到过缓存穿透吗? 详细描述一下。
6.遇到过缓存击穿吗? 详细描述一下
7.如何避免缓存雪崩?
8.缓存如何回收的?
9.如何进行缓存预热?
10.数据库与缓存不一致如何解决?
11.简述一下主从不一致的问题?
12.描述一下redis持久化原理?
13.Redis也打不住了,万级流量会打到DB上,该怎么处理?
14.
16.Redis有哪些持久化方式?
RDB AOF
17.为什么使用setnx?
并发编程
一、原子性高频问题
1.1 Java中如何实现线程安全?
多线程操作共享你给数据出现的问题
锁:
- 悲观锁:synchronized,lock
- 乐观锁:CAS
可以根据业务情况,选择ThreadLocal,让每个线程玩自己的数据
1.2 CAS底层实现
最终回答:先从比较和交换的角度去聊清楚,在Java端聊到native方法,然后再聊到C++中的cmpxchg的指令,再聊到lock指令保证cmpxchg原子性
Java的角度,CAS在Java层面只可以看到native方法。
你会知道比较和交换
- 先比较一下值是否与预期一致,如果一致,交换,返回true
- 先比较一下值是否与预期不一致,如果不一致,不交换,返回false
可以去Unsafe类中提供的CAS操作
四个参数:哪个对象,哪个属性的内存偏移量,oldValue,newValue

native是直接效用本地依赖库C++中的方法
https://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/69087d08d473/src/share/vm/prims/unsafe.cpp

https://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/69087d08d473/src/os_cpu/linux_x86/vm/atomic_Iinux_x86.inline.hpp
在CAS底层,如果是多核的操作系统,需要追加一个lock指令
单核不需要加,因为cmpxchg是一行指令,不能再被拆分了

看到cmpxchg,是汇编的指令,CPU硬件底层就支持比较和交换(cmpxchg),cmpxchg并不是原子性的。(cmpxchg的操作是不可以再拆分的指令)
所以才会出现判断CPU是否是多核,如果是多核就追加lock指令。
lock指令你可以理解为是CPU层面的锁,一般锁的粒度就是缓存行级别的锁,当然也有总线锁,但是成本太高,CPU会根据情况选择
1.3 CAS的常见问题
ABA
ABA不一定是问题!因为一些只存在++,--的这种操作,即使出现ABA问题,也不影响结果
线程A:期望将value从A1-B2
线程B:期望将value从B2-A3
线程C:期望将value从A1-C4
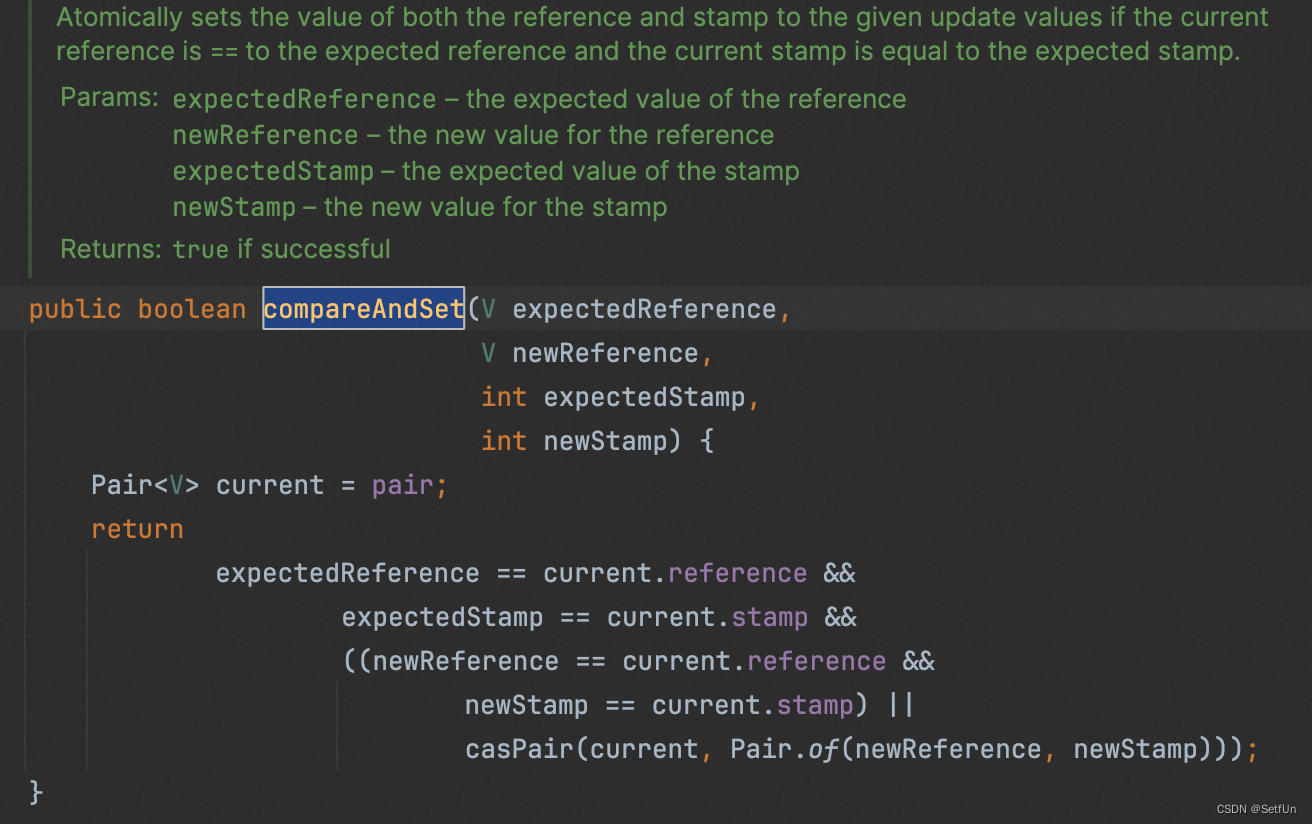
按照原子性来说,无法保证线程安全。
解决方案很简单,Java端已经提供了。
说人话就是,在修改value的同时,指定好版本号。
JUC下提供的AtomicStampedReference就可以实现。
自旋次数过多
回答方式:可以从synchronized或者LongAdder层面去聊
自旋次数过多,会额外的占用大量的CPU资源!浪费资源。
回答方式:可以从synchronized或者LongAdder层面去聊
- synchronized方向:从CAS几次失败后,就将线程挂起 (WAITING),避免占用CPU过多的资源!
- LongAdder方向:这里是基于类似分段锁的形式去解决(要看业务),传统的AtmoicLong是针对内存中唯一的一个值去++, LongAdder在内存中搞了好多个值,多个线程去加不同的值,当你需要结果时,我将所有值累加,返回给你。|
只针对一个属性保证原子性
处理方案:学了AQS就懂了。ReentrantLock基于AQS实现,AQS基于CAS实现核心功能
1.4 四种引用+ThreadLocal的问题?
四种引用类型:
- 强引用: User xx = new User();xx就是强引用,只要引用还在,GC就不会回收!
- 软引用:用一个SofeReference引用的对象,就是软引用,如果内存空间不足,才会回收只有软引用指向对象。一般用于做缓存。
- 弱引用: WeakReference引用的对象,一般就是弱引用,只要执行GC,就会回收只有弱引用指向的对象。可以解决内存泄漏的问题,看ThreadLocal即可ThreadLocal的问题:Java基础面试题2 -- 第16题。
- 虚引用: PhantomReference引用的对象,就是虚引用,拿不到虚引用指向的对象,一般监听GC回收阶段,或者是回收堆外内存时使用。
二、可见性高频问题:
2.1 Java的内存模型
回答方式。先全局描述。在处理指令时,CPU会拉取数据,优先级是从L1到L2到L3,如果都没有,需要从 内存中拉取,JMM就是在CPU和主内存之间,来协调,保证可见、有序性等操作。
一定要聊JMM,别上来聊JVM的内存结构,不是一个东西(Java Memory Model)
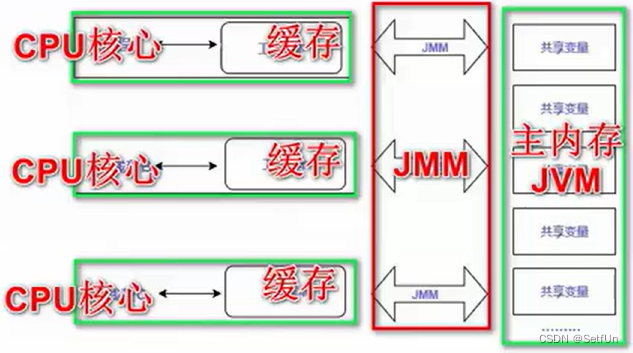
CPU核心,就是CPU核心(寄存器)
缓存是CPU的缓存,CPU的缓存分为L1(线程独享),L2(内核独享),L3(多核共享)
JMM就是Java内存模型的核心,可见性,有序性都基于这实现。
主内存JVM,就是你堆内存。
2.2 保证可见性的方式
啥是可见性:可见性是指线程间的,对变量的变化是否可见
Java层面中,保证可见性的方式有很多:
- volatile,用volatile基本数据类型,可以保证每次CPU去操作数据时,都直接去主内存进行读写。
- synchronized, synchronized的内存语义可以保证在获取锁之后,可以保证前面操作的数据是可见的。
- lock (CAS-volatile),也可以保证CAS或者操作volatile的变量之后,可以保证前面操作的数据是可见的。
- final,是常量必须可见
public class Test {
private static boolean flag =true;
public static void main(String[] args) throws InterruptedException {
new Thread(() ->{
while (flag){
}
System.out.printf("t1线程结束。");
}).start();
Thread.sleep(100);
flag = false;
}
}
//运行结果:一直运行。。。。
synchronized的可见性
public class Test {
private static boolean flag =true;
public static void main(String[] args) throws InterruptedException {
new Thread(() ->{
while (flag){
synchronized (Test.class){
}
}
System.out.printf("t1线程结束。");
}).start();
Thread.sleep(100);
flag = false;
}
}
// 运行结果:t1线程结束。
volatile的可见性
public class Test {
private static volatile boolean flag =true;
public static void main(String[] args) throws InterruptedException {
new Thread(() ->{
while (flag){
}
System.out.printf("t1线程结束。");
}).start();
Thread.sleep(100);
flag = false;
}
}
// 运行结果:t1线程结束。
2.3 volatile修饰引用类型
volatile只对引用数据类型的地址可见,对内部对象的属性不保证可见。
But,这个结论只能在hotspot中实现,如果换一个版本的虚拟机,可能效果就不一样了。volatile修饰引用数据类型,JVM压根就没规范过这种操作,不同的虚拟机厂商,可以自己实现。|
public class Test {
static class A{
boolean b= true;
void run(){
while (b){
}
System.out.printf("A的run方法结束。。");
}
}
static volatile A a = new A();
public static void main(String[] args) throws InterruptedException {
new Thread((a::run)).start();
Thread.sleep(11);
}
}
//运行结果:程序一直运行。。。
2.4 有了MESI协议,为啥还有volatile?
MESI是CPU缓存一致性的协议,大多数的CPU厂商都根据MESI去实现了缓存一致性的效果。
CPU已经有MESI协议了,volatile是不是有点多余啊!?
首先,这哥俩不冲突,一个是从CPU硬件层面上的一致性,一个是Java中JMM层面的一致性。
MESI协议,他有一套固定的机制,无论你是否声明了volatile,他都会基于这个机制来保证缓存的一致性(可见性)。同时,也要清楚,如果没有MESI协议,volatile也会存在一些问题,不过也有其他的处理方案(总线锁,时间成本太高了,如果锁了总线,就一个CPU核心在干活)。
MESI是协议,是规划,是interface,他需要CPU厂商实现。
既然CPU有MESI了,为啥还要volatile,那自然是MESI协议有问题。MESI保证了多核CPU的独占cache之间的可见性,但是CPU不是说必须直接将寄存器中的数据写入到L1,因为在大多是x86架构的CPU中,寄存器和L1之间有一个store buffer,寄存器值可能落到了store buffer, 没落到L1中,就会导致缓存不一致。而且除了x86架构的CPU,在arm和power的CPU中,还有load buffer, invalid queue都会或多或少影响缓存一致性!
回答的方式: MESI一些和volatile不冲突,因为MESI是CPU层面的,而CPU厂商很多实现不一样,而且CPU的架构中的一些细节也会有影响,比如Store Buffer会影响寄存器写入L1缓存。volatile的底层生成的是汇编的lock指令,这个指令会要求强行写入主内存,并且可以忽略Store Buffer这种缓存从而达到可见性的目的,而且会利用MESI协议,让其他缓存行失效。
2.5 volatile的可见性底层实现
volatile的底层生成的是汇编的lock指令,这个指令会要求强行写入主内存,并且可以忽略Store Buffer这种缓存从而达到可见性的目的,而且会利用MESI协议,让其他缓存行失效。
三、有序性高频问题
3.1 什么是有序性问题
在Java编译.java为.class时,会基于川IT做优化,将指令的顺序做调整,从而提升执行效率。
在CPU层面,也会对一些执行进行重新排序,从而提升执行效率。
这种指令的调整,在一些特殊的操作上,会导致出现问题。
3.2 volatile的有序性底层实现
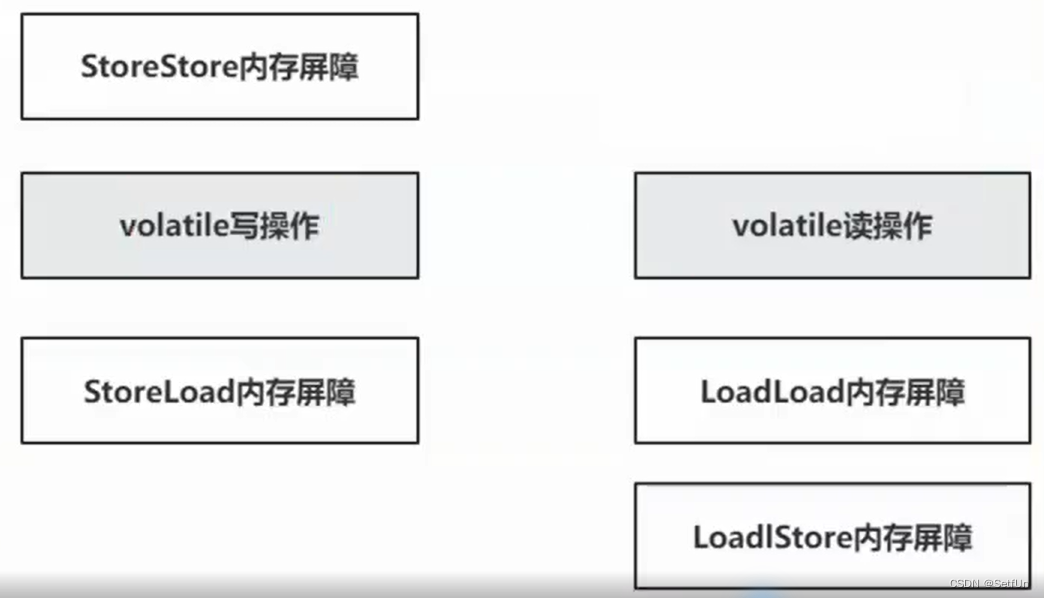
被volatile修饰的属性,在编译时,会在前后追加内存屏障。
- StoreStore:屏障前的读写操作,必须全部完成,再执行后续操作
- StoreLoad:屏障前的写操作,必须全部完成,再执行后续读操作
- LoadLoad:屏障前的读操作,必须全部完成,再执行后续读操作
- LoadStore:屏障前的读操作,必须全部完成,再执行后续写操作
四、synchronized高频问题:
4.1 synchronized锁的升级过程
锁就是对象,随便哪一个都可以,Java中所有对象都是锁。
无锁(匿名偏向)、偏向锁、轻量级锁、重量级锁
无锁(匿名偏向):一般情况下,new出来的一个对象,是无锁状态。因为偏向锁有延迟,在启动JVM的4s中,存在偏向锁,但是如果关闭了偏向锁延迟的设置,new出来的对象,就是匿名偏向。
偏向锁:当某一个线程来获取这个锁资源时,此时,就会变为偏向锁,偏向锁存储线程的ID
当偏向锁升级时,会触发偏向锁撤销,偏向锁撤销需要等到一个安全点,比如GC的时候,偏向撤销销的成本太高,所以默认开始时,会做偏向锁延迟。
安全点:GC,方法返回之前,调用某个方法之后,甩异常的位置,循环的末尾
轻量级锁:当在出现了多个线程的竞争,就要升级为轻量级锁(有可能直接从无锁变为轻量级锁,也有可能从偏向锁升级为轻量级锁),轻量级锁的效果就是基于CAS尝试获取锁资源,这里会用到自适应自旋锁,根据CAS成功与否,决定这次自旋多少次。
重量级锁:如果到了重量级锁,那就没啥说的了,如果有线程持有锁,其他竞争的,就挂起。
4.2 synchronized锁粗化&锁消除?
锁粗化(锁膨胀):(JIT优化)
while(){
sync(){
//多次的获得和释放,成本太高,优化为下面这种
}
}
--------------------------------------------
sync(){
while(){
//优化为这种
}
锁消除:在一个sync中,没有任何共享资源,也不存在锁竞争的情况,JIT编译时,就直接将锁的指令优化掉。
4.3 synchroized实现互斥性的原理
偏向锁:查看对象头中的MarkWord里的线程ID,是否是当前线程,如果不是,就CAS尝试改,如果是,就拿到了锁资源
轻量级锁:查看对象头中的MarkWord里 的Lock Record指针指向的是否是当前线程的虚拟机栈,如果是,拿锁执行业务,如果不是CAS,尝试修改,修改他几次,不成,再升级到重量级锁。
重量级锁:查看对象头中的MarkWord里的指向的ObjectMonitor,查看owner是否是当前线程。如果不是,扔到ObjectMonitor里的EntryList中,排队,并挂起线程,等待被唤醒。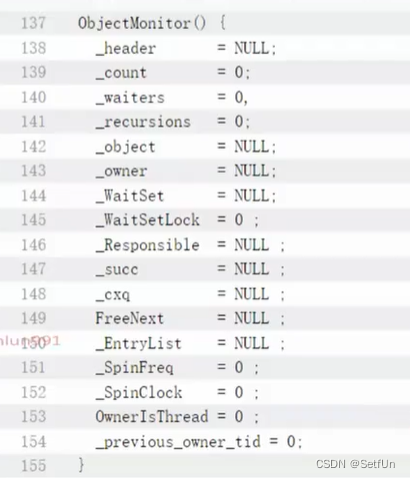
4.4wait方法为什么是Object的方法
执行wait方法需要持有sync锁。
sync锁可以是任意对象。
同时执行wait方法是在持有sync锁的时候,释放锁资源。
其次wait方法需要去操作ObjectMonitor,而操作ObjectMonitor就必须要在持有锁资源的前提的才能操作,将当前线程扔到WaitSet等待池中。
同理,notify方法需要将WaitSet等待池中线程扔到EntryList,如果不拥有ObjectMonitor,怎么操作!?
五、AQS高频问题
5.1AQS 是什么?
AQS就是一个抽象队列同步器,abstract queued sychronizer,本质就是一个抽象类。
AQS中有一个核心属性state,其次还有一个双向链表以及一个单项链表。
首先state是基于volatile修饰,再基于CAS修改,同时可以保证三大特性。(原子,可见,有序)
其次还提供了一个双向链表。有Node对象组成的双向链表。
最后在Condition内部类中,还提供了一个由Node对象组成的单向链表。
AQS是JUC下大量工具的基础类,很多工具都基于AQS实现的,比如lock锁。CountDownLatch,
Semaphore,线程池等等都用到了AQS。
state:就是一个int类型的数值,同步状态,至于到底是什么状态,看子类实现
condition和单向链表:都知道sync内部提供了wait方法和notify方法的使用,lock锁也需要实现这种机制lock锁就基于AQS内部的Condition实现了await和signal方法。(对标sync的wait和notify)
sync在线程持有锁时,执行wait方法,会将线程扔到WaitSet等待池中排队,等待唤醒
lcok在线程持有锁时,执行await方法,会将线程封装为Node对象,扔到Condition单向链表中,等待唤醒
condition是干什么的:将持有锁的线程封装为Node放到Condition单向链表中,并挂起线程,然后等到被唤醒了,就将Condition中的Node扔到AQS的双向链表等待获取锁
5.2唤醒线程时,AQS为什么从后往前遍历?
如果线程没有获取到资源,就需要将线程封装为Node对象,安排到AQS的双向链表中排队,并且可能会挂起线程
如果在唤醒线程时,head节点的next是第一个要被唤醒的,如果head的next节点取消了,AQS的逻辑是从tail点往前遍历,找到离head最近的有效节点?
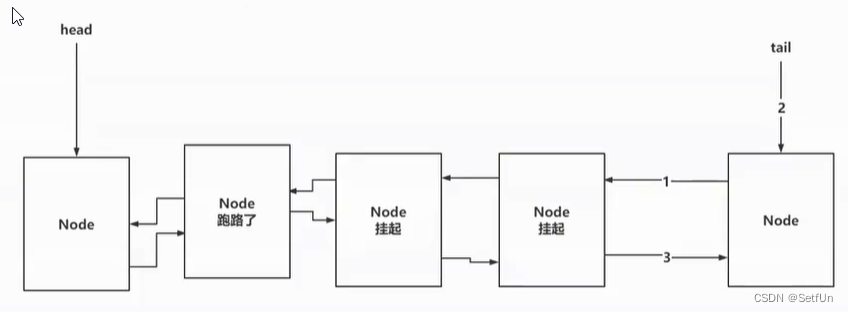
基于addWaiter方法中,是先将当前Node的prev指向之前双向链表末尾的节点(tail),再将tail指向我自己,再让prev节点(上一个节点)指向Node节点
如上图末尾,如果只执行到了2步骤,此时,Node加入到了AQS队列中,但是从prev节点往后,会找不到当前新加入的节点。如果从后往前找就可以找到最后的有效节点。
5.3 AQS为什么用双向链表,不用单向链表?
因为AQS中,存在取消节点的操作,节点被取消后,需要从AQS的双向链表中断开连接,
还需要保证双向链表的完整性,
- 需要将prev节点的next指针,指向next节点。
- 需要将next节点的prev指针,指向prev节点。
如果正常的双向链表,直接操作就可以了。
但是如果是单向链表,需要遍历整个单向链表才能完成的上述的操作。比较浪费资源。
5.4 AQS为什么要有一个虚拟的head节点
有一个哨兵节点更方便操作
另一个是因为AQS内部,每个Node都会有一些状态,这个状态不单单针对自己,还针对后续节点
- 1:当前节点取消了。
- 0:默认状态,啥事没有。
- -1:当前节点的后继节点,挂起了,
- -2:代表当前节点在Condition队列中(await将线程挂起了)
- -3:代表当前是共享锁,唤醒时,后续节点依然需要被唤醒。
Node节点的ws,表示很多信息,除了当前节点的状态,还会维护后继节点状态。
如果取消虚拟的head节点,一个节点无法同时保存当前阶段状态和后继节点状态。
同时,在释放锁资源时,就要基于head节点的状态是否是-1。来决定是否唤醒后继节点。
如果为-1,正常唤醒
如果不为-1,不需要唤醒,减少了一次可能发生的遍历操作,提升性能
5.5 ReentrantLock的底层实现原理
ReentrantLock底层是基于AQS
在线程基于ReentrantLock加锁时,首先基于CAS去修改state的属性,如果state从0变成1了,那就说明锁资源获得了
如果CAS失败了就放到双向链表中去等待,等待获取锁
持有锁的线程,如果执行了Condition 中的await()就放到单向链表中,等待,等待被重新唤醒并且重新竞争锁资源
JAVA中除了线程池中的Worker的锁之外,都是可重入锁
5.6 ReentrantLock的公平锁和非公平锁的区别
ReentrantLock的公平锁和非公平锁的区别在于lock()方法和tryAcquire()方法
Lock()方法:
- 非公平锁:直接尝试将state 0~1如果成功,拿锁直接走, 如果失败再执行tryAcquire()
- 公平锁:直接进行tryAcquire()
tryAcquire()方法:
- 非公平锁:如果当前线程没有锁资源,直接将state 从0~1如果成功就拿锁直接走
- 公平锁:先进行排队 等到是第一个的时候再将state从0~1
5.7 ReentrantReadWriteLock如何实现的读写锁
如果一个操作写少读多,还用互斥锁的话,性能太低,因为读读不存在并发问题,
怎么解决啊,有读写锁的出现。
ReentrantReadWriteLock也是基于AQS实现的一个读写锁,但是锁资源用state标识。
如何基于一个int来标识两个锁信息,有写锁,有读锁,怎么做的?
一个int,占了32个bit位。
在写锁获取锁时,基于CAS修改state的低16位的值
在读锁获取锁时,基于CAS修改state的高16位的值。
写锁的重入,基于state低16直接标识,因为写锁是互斥的。
读锁的重入,无法基于state的高16位去标识,因为读锁是共享的,可以多个线程同时持有。所以读锁的重入用的是ThreadLocal来表示,同时也会对state的高16为进行追加。
六、阻塞队列高频问题
6.1 说下你熟悉的阻塞队列
ArrayBlockingQueue, LinkedBlockingQueue, PriorityBlockingQueue
- ArrayBlockingQueue:底层基于数组实现,记得new的时候设置好边界。
- LinkedBlockingQueue:底层基于链表实现的,可以认为是无界队列,但是可以设置长度。
- PriorityBlockingQueue:底层是基于数组实现的二又堆,可以认为是无界队列,因为数组会扩容。
ArrayBlockingQueue, LinkedBlockingQueue是ThreadPoolExecutor线程池最常用的两个阻塞队列。
PriorityBlockingQueue:是ScheduleThreadPoolExecutor定时任务线程池用的默认的阻塞队 列
6.2 虚假唤醒
虚假唤醒在虚假队列的源码中就有体现
比如消费者1在消费数据时,会先判断队列是否有元素,如果元素个数为0,消费者1会挂起
此处判断元素为0的位置,如果用if循环会导致出现一个问题.
如果生产者添加了一个数据,会唤醒消费者1。
但是如果消费者1没拿到锁资源,消费者2拿到了锁资源井带走了数据的话。
消费者1再次拿到资源时,无法从队列获取到任何元素。导致出现逻辑问题
解决方案,将判断元素个数的位置,设置为while判断。
七、线程池高频问题(最重要)
7.1 线程池的7个参数
-
corePoolSize:核心线程数,也是线程池中常驻的线程数,线程池初始化时默认是没有线程的,当任务来临时才开始创建线程去执行任务
-
maximumPoolSize:最大线程数,在核心线程数的基础上可能会额外增加一些非核心线程,需要注意的是只有当workQueue队列填满时才会创建多于corePoolSize的线程(线程池总线程数不超过maxPoolSize)
-
keepAliveTime:非核心线程的空闲时间超过keepAliveTime就会被自动终止回收掉,注意当corePoolSize=maxPoolSize时,keepAliveTime参数也就不起作用了(因为不存在非核心线程);
-
unit:keepAliveTime的时间单位
-
workQueue:用于保存任务的队列,可以为无界、有界、同步移交三种队列类型之一,当池子里的工作线程数大于corePoolSize时,这时新进来的任务会被放到队列中
-
threadFactory:创建线程的工厂类,默认使用Executors.defaultThreadFactory(),也可以使用guava库的ThreadFactoryBuilder来创建
-
handler:线程池无法继续接收任务(队列已满且线程数达到maximunPoolSize)时的饱和策略,取值有AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy
7.2 线程池的状态有什么,如何记录的?
7.3 线程池常见的拒绝策略
7.4 线程池执行流程
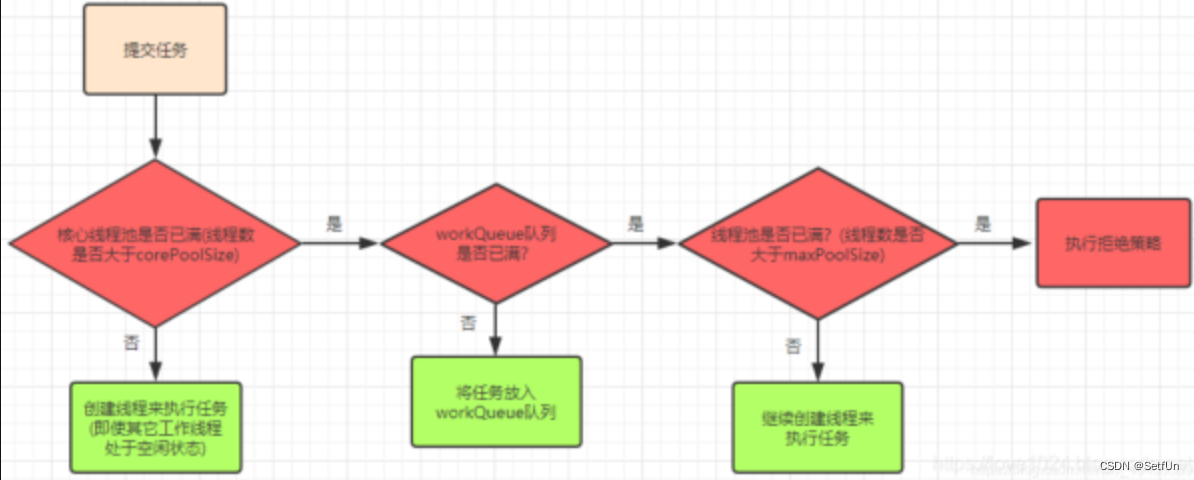
7.5 线程池为什么添加空任务的非核心线程
7.6 在没任务时,核心现在在干嘛?
7.7 工作线程抛出异常会导致什么问题?
7.8 工作线程继承AQS的目的是什么?
7.9 核心参数怎么设置?
MQ
1.消息如何保证幂等性
1.发送方通过传送唯一id保证消息的唯一
2.接收方(消费者)添加分布式锁
3.数据添加唯一索引
2.消息如何保证不丢失
1.发送方(生产者)保证消息的同步发送,等到mq返给我们已经确认收到消息了,再结束线程。
2.接收方(消费者)要先处理逻辑代码 等逻辑代码处理完了再ack
3.消息队列要设置持久化机制(因为mq的数据放在内存,要等数据落到磁盘后再返回给发送方消息已经接收ACK)。并且设置主从(防止机房烧了)
备注:消息保证不丢失问题如何引到消息幂等性问题:消费者先处理代码逻辑,如果再处理完成逻辑代码后,刚要去ack的时候 消费者的服务器宕机了 然后mq没收到ack确认 又一次发了重复消息


















 625
625



 到【灌水乐园】发言
到【灌水乐园】发言







