




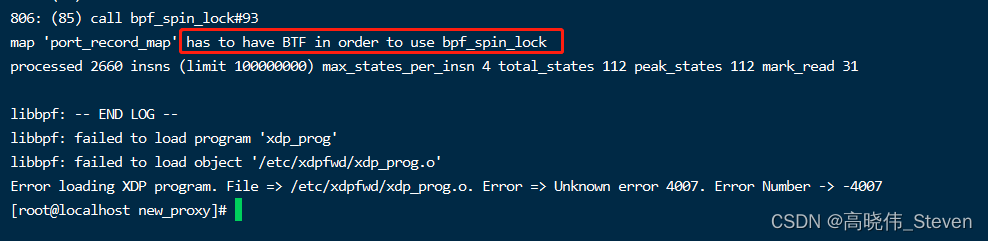
 本文介绍了BPF自旋锁的使用方法,包括其在多核竞争情况下的作用原理及如何应用于BPF map元素的访问控制。通过示例代码详细展示了自旋锁的加锁与解锁过程,并解释了BPF类型格式注释的重要性。
本文介绍了BPF自旋锁的使用方法,包括其在多核竞争情况下的作用原理及如何应用于BPF map元素的访问控制。通过示例代码详细展示了自旋锁的加锁与解锁过程,并解释了BPF类型格式注释的重要性。
使用BPF时,多核之间难免会有竞争,为了应对这种情况,BPF引入了BPF自旋锁(bpf_spin_lock)的概念,它允许对map元素进行操作时锁定对map元素的访问。自旋锁仅可存储于array、hash和cgroup类型的map中。
// 信号量
// /usr/include/linux
struct bpf_spin_lock {
__u32 val;
};
// 内核
// 加锁+解锁
// tools/testing/selftests/bpf/bpf_helpers.h
static void (*bpf_spin_lock)(struct bpf_spin_lock *lock) =
(void *) BPF_FUNC_spin_lock;
static void (*bpf_spin_unlock)(struct bpf_spin_lock *lock) =
(void *) BPF_FUNC_spin_unlock;
这里复制下书上的事例。这个访问控制,精度比较细。对每一个元素使用了自旋锁。另外map必须用BPF类型格式(BPF Type Format,BTF)注释,这样verifier就知道如何解释这个结构。类型格式通过向二进制对象添加调试信息,使内核和其他工具对BPF数据结构有了更丰富的理解。
struct concurrent_element {
struct bpf_spin_lock semaphore;
int count;
}
struct bpf_map_def SEC("maps") concurrent_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(struct concurrent_element),
.max_entries = 100,
};
// 这个宏很重要,如果没有则在verifier时会报错
BPF_ANNOTATE_KV_PAIR(concurrent_map, int, struct concurrent_element);
int bpf_program(struct pt_regs *ctx) {
int key = 0;
struct concurrent_element init_value = {};
struct concurrent_element *read_value;
bpf_map_create_elem(&concurrent_map, &key, &init_value, BPF_NOEXIST);
read_value = bpf_map_lookup_elem(&concurrent_map, &key);
bpf_spin_lock(&read_value->semaphore);
read_value->count += 100;
bpf_spin_unlock(&read_value->semaphore);
}
BPF_ANNOTATE_KV_PAIR()宏很重要,作用是为特定maps添加类型解释,就是使用它为map进行BPF类型格式(BPF Type Format,BTF)注释的。如果不执行这个宏,就会报has to have BTF in order to use bpf spin lock的错误。
当程序或map加载之后可以通过下面命令查看其类型信息:
bpftool map dump id 386
bpftool prog show id 72
bpftool btf show
bpftool btf dump id 60 format c
重点来了
我使用的libbpf中并没有实现BPF_ANNOTATE_KV_PAIR()这个宏的定义,如果你也遇到同样的情况,可以自己手动把下面的宏定义加到代码或头文件中。
#define BPF_ANNOTATE_KV_PAIR(name, type_key, type_val) \
struct ____btf_map_##name { \
type_key key; \
type_val value; \
}; \
struct ____btf_map_##name \
__attribute__ ((section(".maps." #name), used)) \
____btf_map_##name = { }
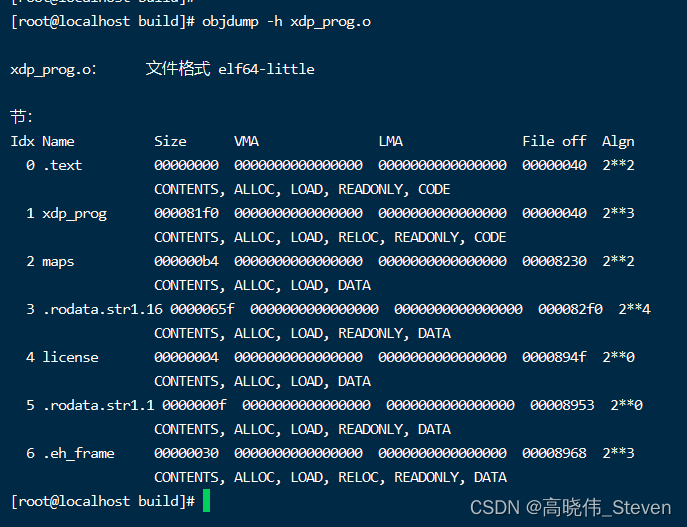
重新编译加载代码后,has to have BTF in order to use bpf spin lock的错误依然存在。使用objdump -h xdp_prog.o命令,可以看到文件中并没有.BTF段。
这个问题的解决方法是在用clang编译时加上-g选项。重新编译后的结果如下图,可以看到.BTF段。
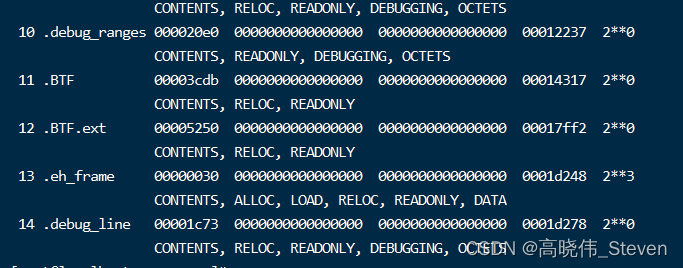
重启程序,verifier时就不再报错了。




















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











