







hashSet和TreeSet的区别:
1、HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,用的是key;
2、hashSet和TreeSet都的元素都具有唯一性,TreeSet多了一个排序功能;
3、HashCode和equals是提供给HashSet用的,因为不需要排序所以只要关注唯一性即可,
hashCode是用来计算hash值的,hash值是用来确定hash表索引的,具有在内存中定位对象位置的功能
hash表中一个索引处存放一个链表,所以需要通过equal方法循环比较链表上的每一个对象才可以确定键值对应的实体(Entity)
put时如果hash表中没有定位到,则新增一个实体并返回null,如果定位到了则覆盖原来的值,并返回原来的值;
TreeMap使用comparator对键值进行排序,Comparator可以在创建键值的时候指定,如果创建的时候没有指定就使用key.compareTo方法,这就要求key必须实现Comparable接口;
TreeMap使用Tree数据结构实现的,所以使用comparator接口就可以了
HashCode冲突问题:
综述:通过一定的算法将key的hashCode转换成数组的index;将key,value,hashcode保存到数组的index位置上;
Hashcode冲突问题:
1、 某些key的hashcode相同
2、 Hashcode不同,但通过了一定的算法映射到数组上的index相同
HashMap的解决方法:
a、 hashMap本身数据结构:
使用Entry存储数据的,Entry封装了HashMap的key,value,hash值,next指针
b、 存储过程:
根据hashCode得到存储位置index后存储的不仅仅是改元素的key,value,hash值还有
指向下一个entry的引用;如果出现了hashcode冲突问题则新建一个entry对象,将改entry的对象指向已存在的entry;一个index指向的可能不是一个entry;也有可能是一个entry链,如下图:
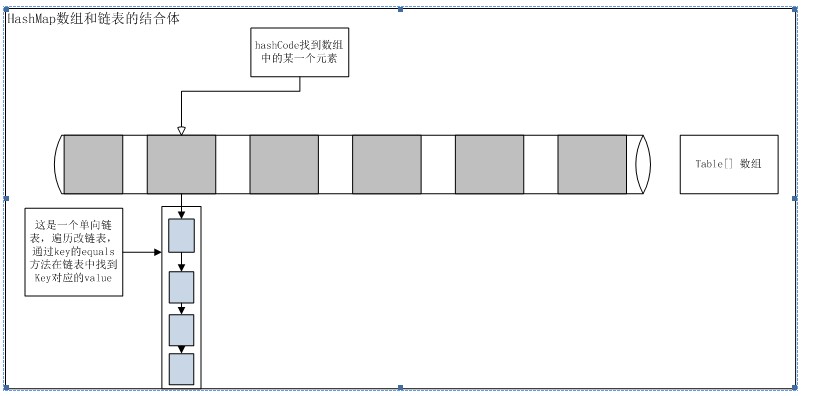
c、取值过程:
还是hash—index---entry的过程,不是直接return改index上的entry对象,而是检查entry链上真正对应的那个entry对象
hashMap的get(key)方法说明:
1、 根据key算出hash值
2、 根据hash值算出数组的index
3、 根据index获取一个Extry链,Entry<K,V> e = table[indexFor(hash, table.length) ,如上图浅蓝色部分
4、 遍历entry对象,通过key的equal方法找到key对应的value
Set是如何实现排序的:
HashSet是按照hash值排序的,不保证集合的迭代顺序,不保证该顺序的恒久不变,允许null元素;
TreeSet 按照元素的自然顺序排序或者按照构造时传入的比较器进行排序
LinkedHashSet 按照插入的顺序排序

















 8312
8312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









