






 本文主要介绍了awk在Linux中的应用,作为'三剑客'之一,awk擅长格式化文本和复杂处理。它逐行处理文件,以空格作为默认分隔符,$1到$NF表示分割后的字段,$0表示整行。awk支持print和printf动作,可以用于输出多列或拼接字符串。此外,可通过BEGIN和END块自定义处理,并能设置输入和输出分隔符。内置变量如NR(行号)、NF(字段数量)提供了更多灵活性。
本文主要介绍了awk在Linux中的应用,作为'三剑客'之一,awk擅长格式化文本和复杂处理。它逐行处理文件,以空格作为默认分隔符,$1到$NF表示分割后的字段,$0表示整行。awk支持print和printf动作,可以用于输出多列或拼接字符串。此外,可通过BEGIN和END块自定义处理,并能设置输入和输出分隔符。内置变量如NR(行号)、NF(字段数量)提供了更多灵活性。
参考原文:https://blog.youkuaiyun.com/liang5603/article/details/80855426
grep sed awk 被称为linux中的“三剑客”
grep更适合单纯的查找或匹配文本
sed更适合编辑匹配到的文本
awk更适合格式化文本,对文本进行较复杂格式处理
- awk最常用的动作(action)就是print和printf
- awk是逐行处理的,处理完一行再处理下一行,默认以“换行符”为标记,识别每一行。
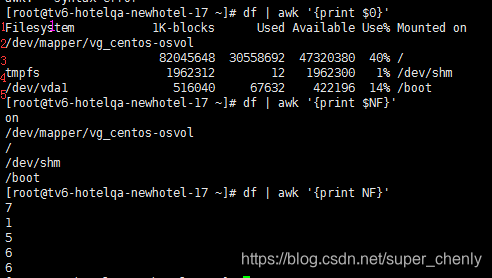
- awk默认使用空格作为分隔符去分割当前行。分割完的第一个字段为$1(不是$0,$0表示所有行),以此类推。
- $ N F 表 示 表 示 分 割 后 的 最 后 一 列 , N F 和 NF表示表示分割后的最后一列,NF和 NF表示表示分割后的最后一列,NF和NF不一样,NF表示每行被分割的数量。(NR - Number of Record)
-
输出多列(多个参数值)。使用逗号隔开awk ‘{print $1,$2,$3}’:结果以空格分开,但是不加逗号会连接在一起输出
-
awk可用于拼接。被拼接字符串用双引号括起来 如:awk’{print “column1:”$1,“column2:”$2}’,注意$1这种内置变了不能使用双引号,否则被当做普通文本输出。
-
输出所有行:awk’{print $0}’ 等价于 awk ‘{print}’
-
awk语法: awk[options]‘pattern{Action}’ file
如 :
$ awk ‘BEGIN{print “wolaiceshibegin…”} {print $1,$2}’ awktest.txt
$ awk ‘{print $1,$2}END{print “test ending”}’ awktest.txt -
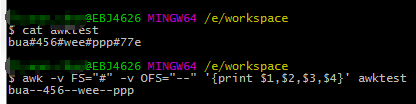
设置输入分隔符(列以什么分隔符为准split):awk -F或者awk -v -FS 如awk -F# ‘print $1,$2’ test.txt
-
设置输出分隔符(输出列以什么分隔符join):awk -v OFS 如awk -v FS="#" -v OFS=’—’‘print $1,$2’ test.txt (输入和输出一起用,OFS output field seperator)
-
-
awk变量: 分为内置变量和自定义变量
-
如NR代表行号,NF代表每行被分列数:
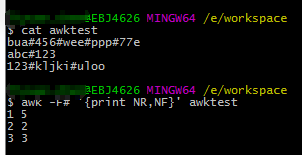
细心如你一定注意到了一个细节,就是在打印 $0 , $1, 2 这 些 内 置 变 量 的 时 候 , 都 有 使 用 到 " 2 这些内置变量的时候,都有使用到" 2这些内置变量的时候,都有使用到"“符号,但是在调用 NR , NF 这些内置变量的时候,就没有使用" " , 如 果 你 有 点 不 习 惯 , 那 么 可 能 是 因 为 你 已 经 习 惯 了 使 用 b a s h 的 语 法 去 使 用 变 量 , 在 b a s h 中 , 我 们 在 引 用 变 量 时 , 都 会 使 用 ",如果你有点不习惯,那么可能是因为你已经习惯了使用bash的语法去使用变量,在bash中,我们在引用变量时,都会使用 ",如果你有点不习惯,那么可能是因为你已经习惯了使用bash的语法去使用变量,在bash中,我们在引用变量时,都会使用符进行引用,但是在awk中,只有在引用$0、 1 等 内 置 变 量 的 值 的 时 候 才 会 用 到 " 1等内置变量的值的时候才会用到" 1等内置变量的值的时候才会用到"”,引用其他变量时,不管是内置变量,还是自定义变量,都不使用"$",而是直接使用变量名。

















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









