



简短版:
• “RTX”更多是一个品牌/架构标签(含消费级 GeForce RTX 与专业工作站 RTX A 系列),强调光线追踪(RT Cores)+ AI/Tensor Cores,面向游戏、内容创作与专业可视化/工程场景。
• “Tesla”是英伟达过去用于数据中心/计算加速卡的品牌(如 K80、P100、V100、T4)。自 2020 年起,英伟达不再使用 Tesla 品牌,转而称为 NVIDIA Data Center GPUs(如 A100、H100、B100)。
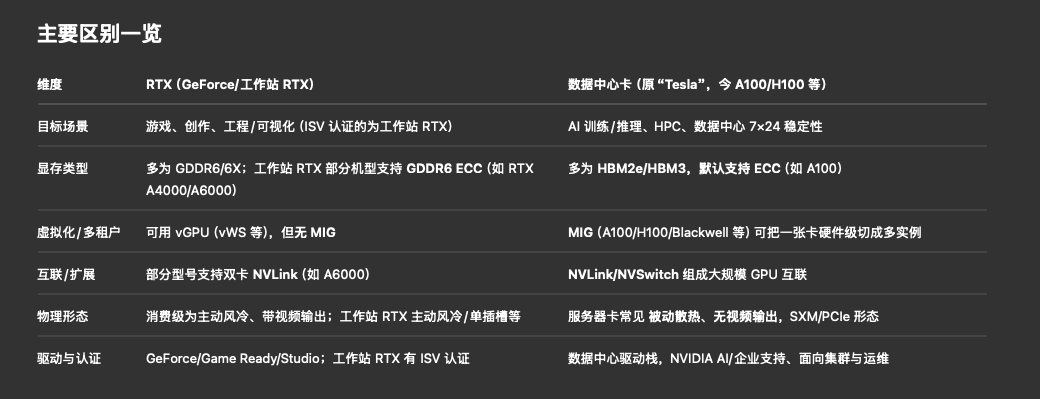
证据:RTX/RT 核心定位与生态(光追/AI) ;Tesla 品牌已停用、改称数据中心 GPU(A100 等);A100 的 MIG 与数据中心特性(HBM、MIG、带宽) ;数据中心 NVLink/NVSwitch 扩展能力 ;工作站 RTX(A6000/A4000)关于 GDDR6 + ECC 与 NVLink 说明 。
怎么选(结合你要做的 RAG 重排)
• 线上推理/多租户:优先 数据中心卡(如 L4/A10 用于推理,或 A100/H100 视预算),因为更好管控、可做虚拟化/分区(MIG 取决于型号)。
• 单机开发/中小流量:工作站 RTX(如 RTX A6000/5000 Ada)或高端 GeForce RTX(如 4090)足够;注意显存与稳定散热。
• 需要 NVLink 拼大显存或高速跨卡:选支持 NVLink 的 工作站 RTX(如 A6000 双卡)或 数据中心平台(NVLink/NVSwitch)。
一句话记:RTX 是用户/工作站端(光追+创作/工程),“Tesla”则是历史名—如今的“数据中心 GPU”面向 AI/HPC 与上机房的可运维性。如果你要给 bge-reranker 这类轻量推理上生产,常见选型是 L4/A10(数据中心) 或 A6000/4090(开发/中小量);要硬件多租户隔离就看 MIG(A100/H100/Blackwell)。



















 3887
3887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











