



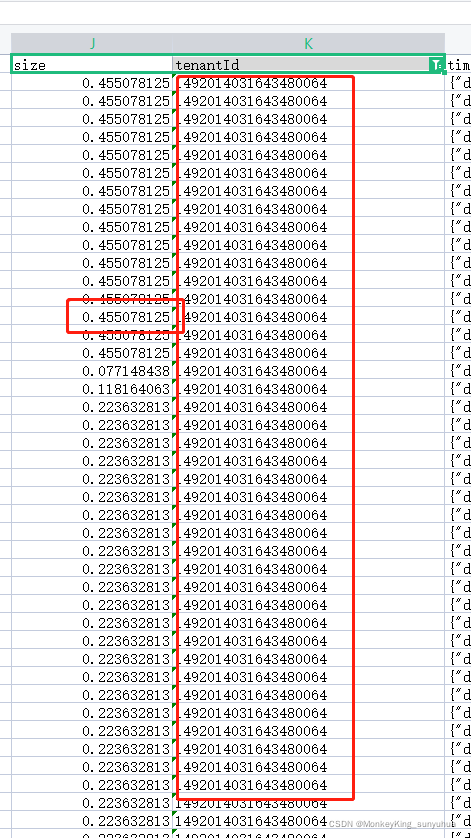
现在存在一个execl,根据tenantId这一列找出size的最大值;
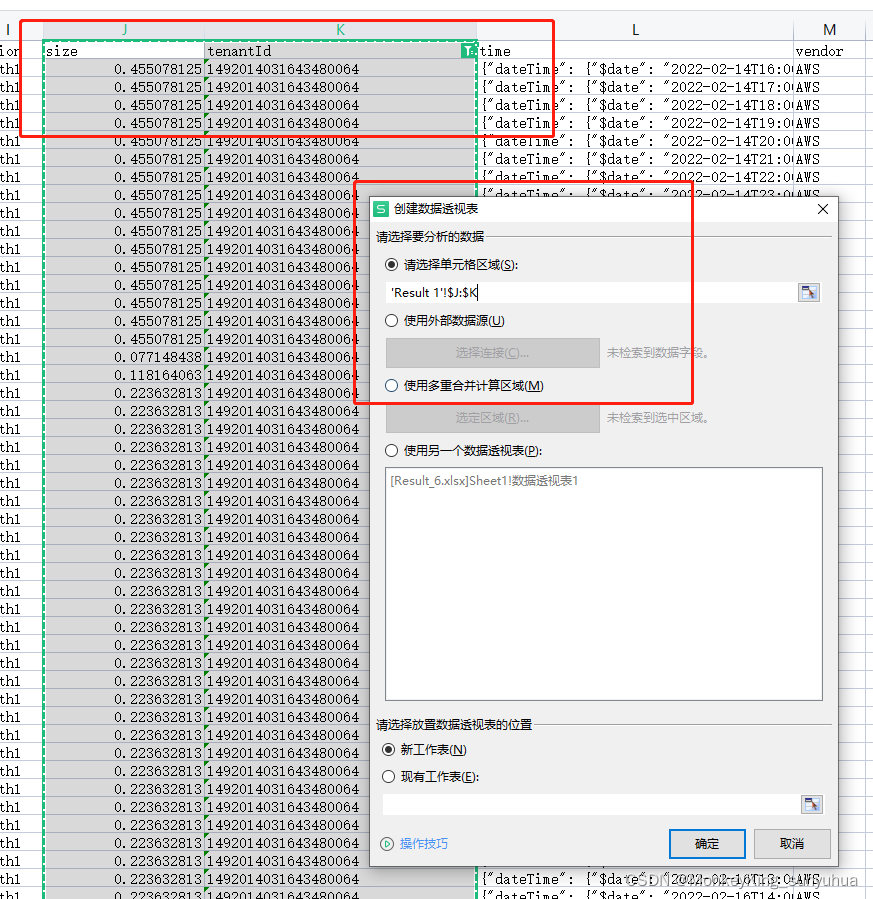
使用数据透视图的功能
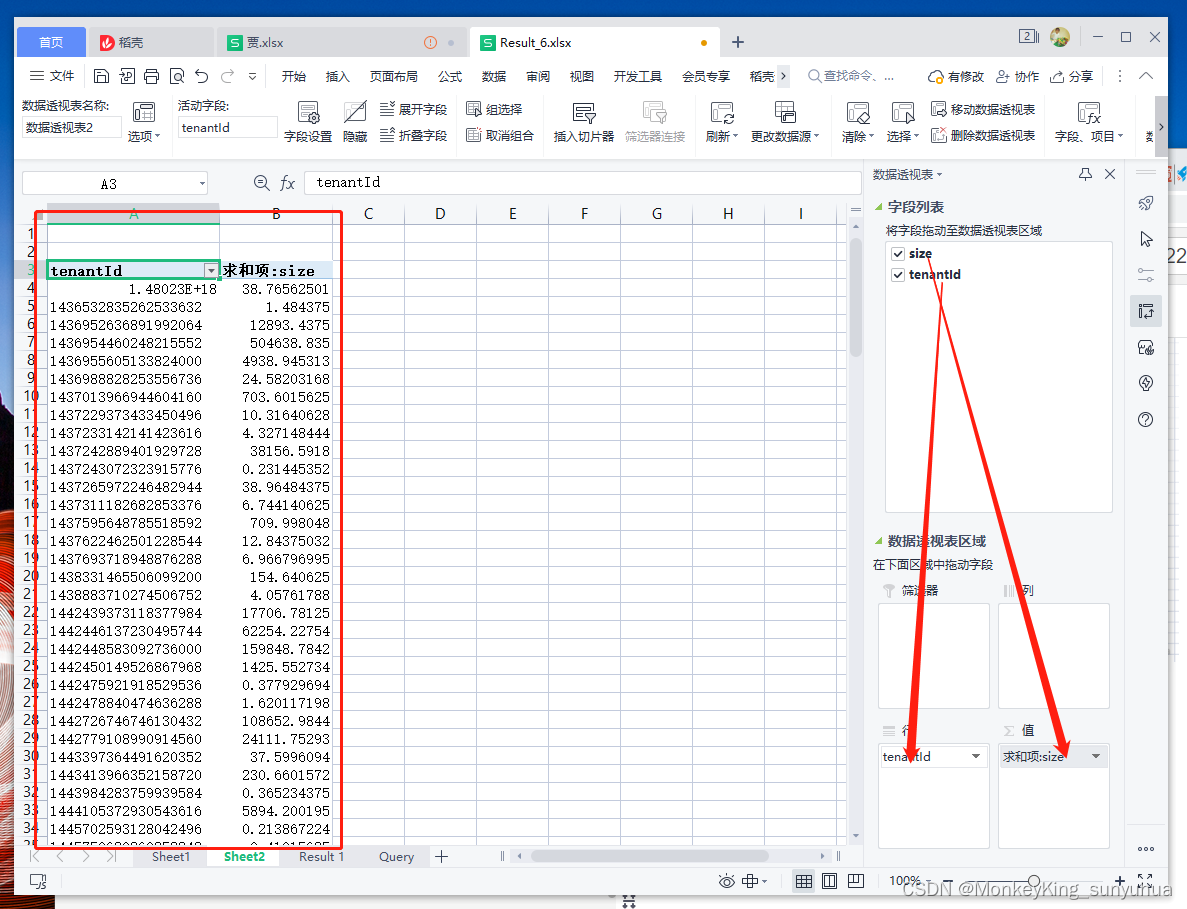
然后求和项修改为最大值项
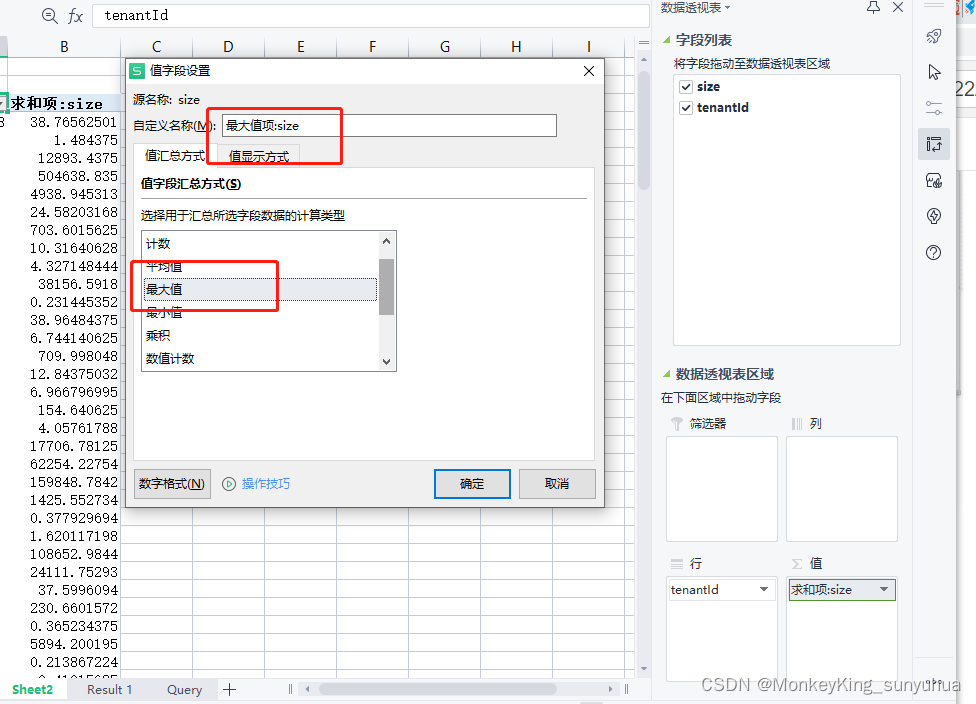
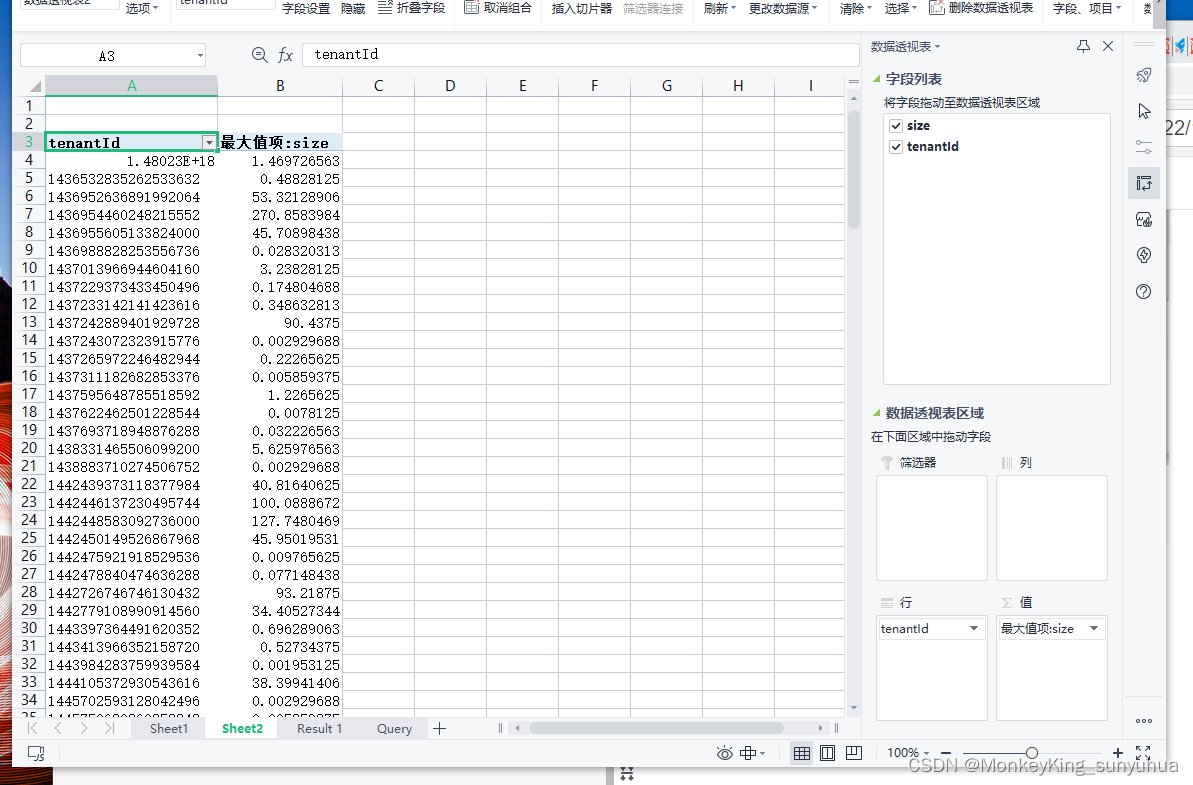
注意:如果值没有出来,检查求和项或者求大小值的项是不是常规或者数值类型,只有数值类型才能做计算
 本文介绍如何利用Excel的数据透视功能,针对tenantId列找出size的最大值,并将求和项调整为求最大值操作,同时强调检查数据类型以确保计算正确性。
本文介绍如何利用Excel的数据透视功能,针对tenantId列找出size的最大值,并将求和项调整为求最大值操作,同时强调检查数据类型以确保计算正确性。
现在存在一个execl,根据tenantId这一列找出size的最大值;
使用数据透视图的功能
然后求和项修改为最大值项
注意:如果值没有出来,检查求和项或者求大小值的项是不是常规或者数值类型,只有数值类型才能做计算

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






















 871
871







