



MongoDB
第 0 章 MongoDB 简介
0.1 MongoDB 概念
MongoDB 是一个面向文档存储的数据库,所谓文档就是 bson 数据结构(二进制 json)。
| MongoDB 概念 | SQL 概念 |
|---|---|
| 数据库 database | 数据库 database |
| 集合 collection | 表 table |
| 文档 document | 行 row |
| 字段 field | 列 column |
| 索引 index | 索引 index |
| _id | 主键 primary key |
| 视图 view | 视图 view |
| 聚合操作 $lookup | 聚合操作 table joins |
0.2 MongoDB 安装
0.2.1 Ubuntu 下安装 MongoDB
下载地址:www.mongodb.com/try/download/community
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.4.22.tgz
tar zxvf mongodb-linux-x86_64-rhel70-4.4.22.tgz -C /opt/mongodb
cd /opt/mongodb
mv mongodb-linux-x86_64-rhel70-4.4.22 mongodb-4.4.22
添加环境变量:
vim /etc/profile
# 在文件末尾添加以下两行
export MONGODB_HOME=/opt/mongodb/mongodb-4.4.22
PATH=$PATH:$MONGODB_HOME/bin
# 保存退出后执行
source /etc/profile
# 检查配置是否生效
mongod --help
0.2.2 Windows 下安装 MongoDB
下载地址:www.mongodb.com/try/download/community。下载完解压,准备配置过程。
- 首先要在 MongoDB 的 data 文件夹里新建一个 db 文件夹和一个 log 文件夹,然后在 log 文件夹下新建一个文件 mongo.log
- 然后将 MongoDB 的 bin 目录添加到环境变量 path 中
- 以管理员身份运行 cmd 命令窗口,进入 MongoDB 的 bin 目录下,输入以下命令:
cd D:\Tools\MongoDB-Windows\bin
mongod --dbpath "D:\Tools\MongoDB-Windows\data\db" --logpath "D:\Tools\MongoDB-Windows\data\log\mongo.log" -install -serviceName "MongoDB"
- 在 Windows 的服务中可以看到名为 MongoDB 的服务启动了:
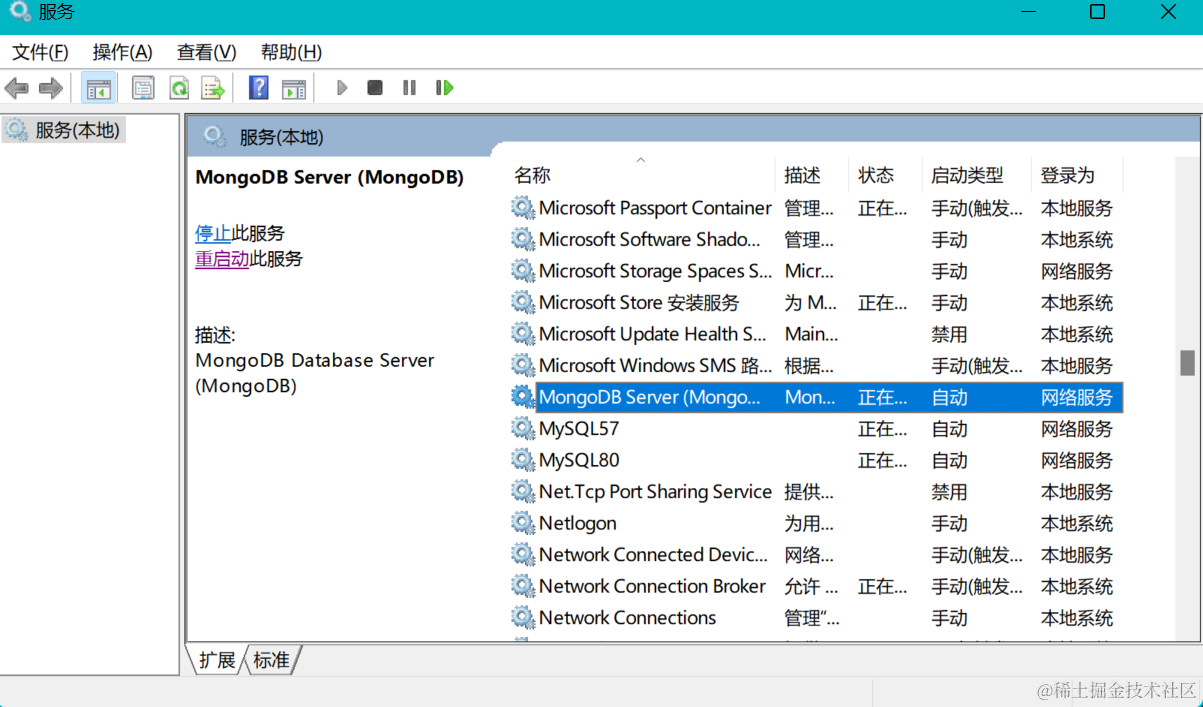
- 然后在 cmd 中输入以下命令即可启动:
mongo
0.3 MongoDB 配置文件
0.3.1 systemLog 系统日志
| systemLog | 说明 |
|---|---|
| verbosity | 日志级别,默认 0 表示包含 info 信息, |
| path | 日志文件路径 |
| logAppend | 默认 false,表示重启后创建一个新的日志文件。如果为 true,表示重启后在现有日志尾部继续添加日志 |
| destination | 日志输出的目的地,若为 file 表示输出到文件,若不指定则输出到标准输出中 |
0.3.2 processManagement 进程管理
| processManagement | 说明 |
|---|---|
| fork | 是否运行在后台,默认 false。一般设置为 true |
| pidFilePath | pid 文件路径,不指定则不会创建 |
| timeZoneInfo | 要从中加载时区数据库的完整路径,默认使用 MongoDB 内置时区数据库。Linux 下默认路径为 usr/share/zoneinfo |
0.3.3 net 网络管理
| net | 说明 |
|---|---|
| port | 端口。对于 mongod 和 mongos 实例,默认为 27017。对于分片成员,默认为 27018。对于配置服务器成员,默认为 27019 |
| bindIp | 绑定内网 ip。若绑定所有 IPV4 地址,则设置为 0.0.0.0 |
| maxIncomingConnections | 进程允许的最大连接数,默认 65536 |
| wireObjectCheck | 当客户端写入数据时,是否检测数据的有效性,默认为 true |
| serviceExecutor | 默认 synchronous,使用同步网络,并在每个连接的基础上管理网络线程池 |
0.3.4 security 安全管理
| security | 说明 |
|---|---|
| keyFile | 存储共享密钥文件的路径,MongoDB 实例在分片集群中使用共享密钥进行相互认证 |
| authorization | 启用或禁用基于角色的访问控制(RBAC)来管理每个用户对数据库资源和操作的访问,默认 disabled 禁用,若要开启设置为 enabled |
0.3.5 storage 存储管理
| storage | 说明 |
|---|---|
| dbPath | mongod 实例存储其数据的目录 |
| journal.enabled | 启用或禁用持久性日志以确保数据文件保持有效和可恢复,默认 true 启用日志记录。该设置仅对 mongod 可用 |
| journal.commitIntervalMs | mongod 进程在日志操作之间允许的最大间隔时间(毫秒)。取值范围是 1 ~ 500 毫秒。在 WiredTiger 上默认的日志提交间隔是 100 毫秒 |
| engine | mongod 数据库的存储引擎。默认 wiredTiger |
| oplogMinRetentionHours | 指定保留 oplog 条目的最小小时数,默认为 0 |
0.3.6 sharding 分片管理
| sharding | 说明 |
|---|---|
| clusterRole | mongod 实例在分片集群中所扮演的角色,configsvr 表示将此实例作为配置服务器启动;shardsvr 表示将此实例作为一个分片启动 |
第 1 章 CRUD operations
1.1 insert
插入操作将新文档添加到集合。如果当前不存在该集合,则插入操作将创建该集合。
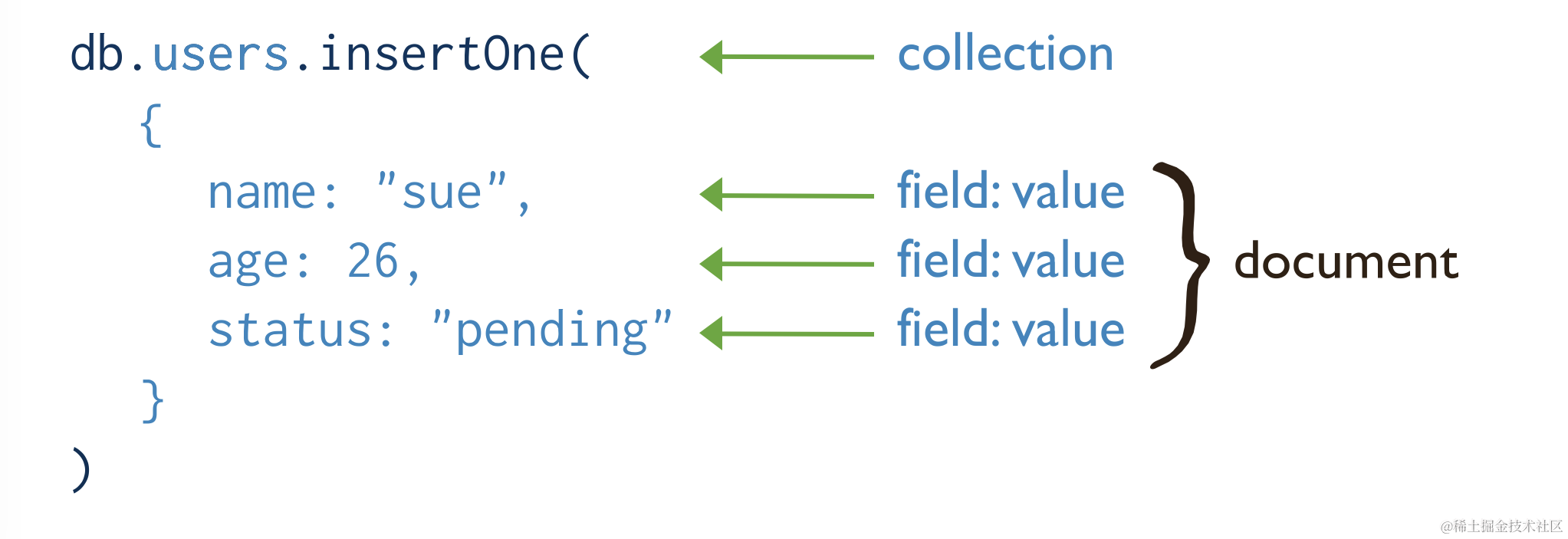
1.1.1 insertOne 插入单个文档
db.col.insertOne(
<document>,
{
writeConcern: <document>
}
)
1.1.2 insertMany 插入多个文档
db.col.insertMany(
[ <document 1>, <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
1.2 find
查询集合的文档:
db.col.find(query, projection)
| Parameter | Type | Description |
|---|---|---|
| query | document | 指定查询选择条件(Optional) |
| projection | document | 指定要使用投影运算符返回的字段(Optional) |

| 条件查询语句 | 查询方式 |
|---|---|
| db.col.find( { “name”: /^h/ } ) | 模糊查询 |
| db.col.find( { “likes”: {$gt: 80} } ) | 比较查询 |
| db.col.find( { “hobbies”: {$in: [ “mongodb”, “Java”, “PY” ]}} ) | 包含查询 |
| db.col.find( { “hobbies”: {$nin: [ “mongodb”, “Java”, “PY” ]}} ) | |
| db.col.find( { $and: [{ “name”: “sun” }, { “likes”: 100 } ] } ) | 逻辑查询 |
| db.col.find( { $or: [{ “name”: “sun” }, { “likes”: 200 } ] } ) |
| 条件查询语句 | 统计指标 |
|---|---|
| db.col.find().count() | 集合的文档数量 |
| db.col.find().limit(num) | 返回不超过 num 个数量的文档 |
| db.col.find().skip(num) | 跳过 num 个数量的文档,返回其他文档 |
| db.col.find().sort(“likes”: 1) | 对文档按照 likes 字段升序排序 |
| db.col.find().sort(“likes”: -1) | 对文档按照 likes 字段降序排序 |
1.3 update
更新操作修改集合中的现有文档。
1.3.1 updateOne 更新集合中的单个文档
db.col.updateOne(
<filter>,
<update>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string>
}
)
1.3.2 updateMany 更新集合中的多个文档
db.col.updateMany(
<filter>,
<update>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string>
}
)

1.3.3 replaceOne 替换集合中的单个文档
db.collection.replaceOne(
<filter>,
<replacement>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
hint: <document|string>
}
)
1.4 delete
删除操作从集合中删除文档。
1.4.1 deleteOne 删除匹配的第一个文档
db.col.deleteOne(
<filter>,
{
writeConcern: <document>,
collation: <document>,
hint: <document|string>
}
)
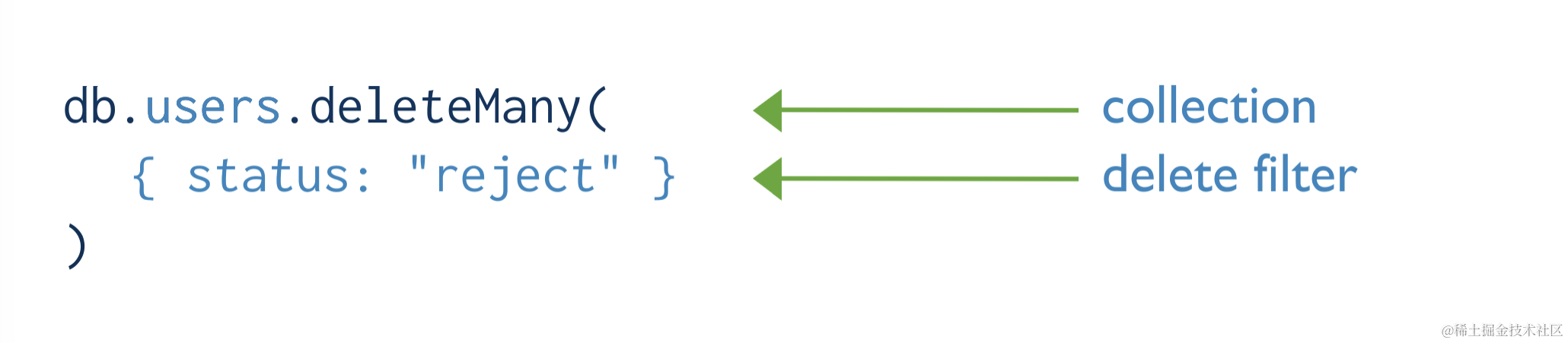
1.4.2 deleteMany 删除匹配的所有文档
db.col.deleteMany(
<filter>,
{
writeConcern: <document>,
collation: <document>
}
)
1.5 CRUD 参数
1.5.1 writeConcern
writeConcern 描述了 MongoDB 写操作时确认级别。在分片集群中,mongos 实例将 writeConcern 传递给分片。
对于多文档事务,可以在事务级别中设置 writeConcern,而不是在每个操作上显式设置 writeConcern。
副本集和分片集群支持设置全局默认 writeConcern,未显式指明 writeConcern 的写操作继承 setDefaultRWConcern 中的 writeConcern 设置:
db.adminCommand(
{
setDefaultRWConcern : 1,
defaultReadConcern: { <read concern> },
defaultWriteConcern: { <write concern> },
writeConcern: { <write concern> },
comment: <any>
}
)
writeConcern 包括以下字段:
{ w: <value>, j: <boolean>, wtimeout: <number> }
w 指定请求确认写操作复制到 mongod 实例的数量。如果一个副本集包含 1 个主节点和 2 个 副节点,w: 2 需要主节点和 1 个副节点的确认,w: 3 需要主节点和 2 个副节点的确认。
j 是一个布尔值,表示是否确认 w 指定的实例的写操作已经写入磁盘日志。
wtimeout 指定 writeConcern 的时间限制,单位毫秒。wtimeout 只适用于 w > 1 的情况,wtimeout = 0 表示没有时间限制。
一般对于副本集和分片集群,我们需要配置 writeConcern 来确认写操作复制到指定数量的副本集成员。
1.5.2 collation
collation 排序允许用户为字符串比较指定特定语言的规则,具有以下语法:
{
locale: <string>,
caseLevel: <boolean>,
caseFirst: <string>,
strength: <int>,
numericOrdering: <boolean>,
alternate: <string>,
maxVariable: <string>,
backwards: <boolean>
}
https://www.mongodb.com/docs/current/reference/collation/
1.5.3 hint
hint 显式指定使用索引,类型为 document。比如在集合中创建索引:
db.col.createIndex( { grade: 1 } )
以下删除操作显式指定使用该索引:
db.col.deleteOne(
{ "points": { $lte: 20 }, "grade": "F" },
{ hint: { grade: 1 } }
)
1.5.4 projection
projection 投影参数确定在匹配文档中返回哪些字段,为以下形式:
{ <field1>: <value>, <field2>: <value> ... }
value 为 1 或 true 表示返回该字段,value 为 0 或 false 表示不返回该字段。
1.5.5 ordered
ordered 表示应该操作是否为有序,默认 true 表示有序。
1.5.6 upsert
update 操作中的 upsert 参数类型为 boolean,值为 true 表示如果没有文档与 filter 匹配,则创建新文档。默认为 false,表示如果没有文档与 filter 匹配,不会创建新文档。
1.5.7 arrayFilters
update 操作中的 arrayFilters 参数类型为 array,用于确定在对数组字段进行更新操作时要修改哪些数组元素。
比如创建集合如下:
db.students.insert([
{ "_id" : 1, "grades" : [ 95, 92, 90 ] },
{ "_id" : 2, "grades" : [ 98, 100, 102 ] },
{ "_id" : 3, "grades" : [ 95, 110, 100 ] }
])
要修改某个 document 的 grade 数组中大于等于 100 的所有元素为 100:
db.students.updateOne(
{ grades: { $gte: 100 } },
{ $set: { "grades.$[element]" : 100 } },
{ arrayFilters: [ { "element": { $gte: 100 } } ] }
)
更新完成后,集合文档如下:
{ "_id" : 1, "grades" : [ 95, 92, 90 ] }
{ "_id" : 2, "grades" : [ 98, 100, 100 ] }
{ "_id" : 3, "grades" : [ 95, 110, 100 ] }
1.6 Bulk Write Operations
MongoDB 为客户端提供了批量写操作的能力,通过 db.col.bulkWrite() 提供批量插入、更新和删除操作的能力。批量写操作分为有序和无序。有序操作是串行的,如果其中一个写操作处理过程出现错误, MongoDB 不处理剩余的其它写操作。无序操作是并行的,如果其中一个写操作处理过程出现错误, MongoDB 继续处理剩余的其它写操作。默认情况下,bulkWrite 是有序的,如果要指定无序,设置 ordered: false。
比如创建 pizzas 集合如下:
db.pizzas.insertMany( [
{ _id: 0, type: "pepperoni", size: "small", price: 4 },
{ _id: 1, type: "cheese", size: "medium", price: 7 },
{ _id: 2, type: "vegan", size: "large", price: 8 }
] )
执行 bulkWrite() 操作使用 insertOne 添加两个文档,使用 updateOne 更新文档,使用 deleteOne 删除文档,使用 replaceOne 替换文档:
try {
db.pizzas.bulkWrite( [
{ insertOne: { document: { _id: 3, type: "beef", size: "medium", price: 6 } } },
{ insertOne: { document: { _id: 4, type: "sausage", size: "large", price: 10 } } },
{ updateOne: {
filter: { type: "cheese" },
update: { $set: { price: 8 } }
} },
{ deleteOne: { filter: { type: "pepperoni"} } },
{ replaceOne: {
filter: { type: "vegan" },
replacement: { type: "tofu", size: "small", price: 4 }
} }
] )
} catch( error ) {
print( error )
}
第 2 章 聚合操作
聚合操作处理多个文档并返回计算结果。聚合管道是执行聚合操作的首选方法。聚合管道由一个或多个处理文档的阶段组成。每个阶段对输入文档执行一个操作。例如,阶段可以过滤文档、分组文档和计算值。从一个阶段输出的文档被传递到下一个阶段。聚合管道可以返回文档组的结果。例如,返回总数、平均值、最大值和最小值。
2.1 $match 和 $group 阶段
比如一个名为 orders 的集合有以下文档:
db.orders.insertMany( [
{ _id: 0, product: "Steel beam", status: "new", quantity: 10 },
{ _id: 1, product: "Steel beam", status: "urgent", quantity: 20 },
{ _id: 2, product: "Steel beam", status: "urgent", quantity: 30 },
{ _id: 3, product: "Iron rod", status: "new", quantity: 15 },
{ _id: 4, product: "Iron rod", status: "urgent", quantity: 50 },
{ _id: 5, product: "Iron rod", status: "urgent", quantity: 10 }
] )
以下示例包含两个阶段,返回每个产品的紧急订单总数:
db.orders.aggregate( [
{ $match: { status: "urgent" } },
{ $group: { _id: "$product", sumQuantity: { $sum: "$quantity" } } }
] )
$match阶段,将文档过滤成 status 为 urgent 的文档,然后输出到$group阶段$group阶段,按照产品 product 对文档进行分组,使用$sum计算每个产品的总数,该总数存储在聚合管道返回的 sumQuantity 字段中
返回结果为:
[
{ _id: 'Steel beam', sumQuantity: 50 },
{ _id: 'Iron rod', sumQuantity: 60 }
]
2.2 $count 阶段
$count 阶段返回输入到该阶段文档数量的计数
比如一个名为 scores 的集合有以下文档:
db.col.insertMany( [
{ "_id" : 1, "subject" : "History", "score" : 88 },
{ "_id" : 2, "subject" : "History", "score" : 92 },
{ "_id" : 3, "subject" : "History", "score" : 97 },
{ "_id" : 4, "subject" : "History", "score" : 71 },
{ "_id" : 5, "subject" : "History", "score" : 79 },
{ "_id" : 6, "subject" : "History", "score" : 83 }
] )
执行两个阶段的聚合操作:
db.scores.aggregate(
[
{ $match: { score: { $gt: 90 } } },
{ $count: "passing_scores" }
]
)
$match阶段,将分数大于 90 的文档传递到下一阶段$count阶段返回聚合管道中剩余文档的计数,并将该值分配给一个名为 passing_scores 的字段
返回结果为:
{ "passing_scores" : 2 }
2.3 $limit 阶段
$limit 阶段限制传递到管道下一阶段的文档数量
db.col.aggregate([
{ $limit : 5 }
]);
2.4 $skip 阶段
$skip 阶段跳过传递到该阶段指定数量的文档,并将其余文档传递到管道中的下一个阶段
db.col.aggregate([
{ $skip : 5 }
]);
2.5 $sort 阶段
$sort 阶段对所有输入文档进行排序,并按排序顺序将它们返回到管道
比如一个名为 col 的集合有以下文档:
db.col.insertMany( [
{ "_id" : 1, "name" : "Central Park Cafe", "borough" : "Manhattan"},
{ "_id" : 2, "name" : "Rock A Feller Bar and Grill", "borough" : "Queens"},
{ "_id" : 3, "name" : "Empire State Pub", "borough" : "Brooklyn"},
{ "_id" : 4, "name" : "Stan's Pizzaria", "borough" : "Manhattan"},
{ "_id" : 5, "name" : "Jane's Deli", "borough" : "Brooklyn"}
] )
使用 $sort 阶段对 borough 字段进行升序排序,如果 borough 字段相同,则按 _id 字段升序排序:
db.col.aggregate(
[
{ $sort : { borough : 1, _id: 1 } }
]
)
返回结果为:
{ "_id" : 3, "name" : "Empire State Pub", "borough" : "Brooklyn" }
{ "_id" : 5, "name" : "Jane's Deli", "borough" : "Brooklyn" }
{ "_id" : 1, "name" : "Central Park Cafe", "borough" : "Manhattan" }
{ "_id" : 4, "name" : "Stan's Pizzaria", "borough" : "Manhattan" }
{ "_id" : 2, "name" : "Rock A Feller Bar and Grill", "borough" : "Queens" }
2.6 $unset 阶段
$unset 阶段从文档中移除字段
比如一个名为 books 的集合有以下文档:
db.books.insertMany([
{ "_id" : 1, title: "Antics", isbn: "000112222", author: { last:"An", first: "Auntie" } ] },
{ "_id" : 2, title: "Babble", isbn: "999999999", author: { last:"Bumble", first: "Bee" } ] }
])
移除 isbn 字段以及 author 数组字段中的 first 字段:
db.books.aggregate([
{ $unset: [ "isbn", "author.first" ] }
])
返回结果为:
{ "_id" : 1, "title" : "Antics", "author" : { "last" : "An" } ] }
{ "_id" : 2, "title" : "Babble", "author" : { "last" : "Bumble" } ] }
2.7 $unwind 阶段
$unwind 阶段从输入文档中解构一个数组字段,为每个元素输出一个文档。每个输出文档都是输入文档,其中数组字段的值被元素替换
比如一个名为 col 的集合有以下文档:
db.col.insertOne({ "_id" : 1, "item" : "ABC1", sizes: [ "S", "M", "L"] })
使用 $unwind 阶段为 size 数组中的每个元素输出一个文档:
db.col.aggregate( [ { $unwind : "$sizes" } ] )
返回结果为:
{ "_id" : 1, "item" : "ABC1", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "L" }
2.8 $set 阶段
$set 阶段向文档添加新字段
比如一个名为 scores 的集合有以下文档:
db.scores.insertMany([
{ _id: 1, student: "Maya", homework: [ 10, 5, 10 ], quiz: [ 10, 8 ] },
{ _id: 2, student: "Ryan", homework: [ 5, 6, 5 ], quiz: [ 8, 8 ] }
])
下面的操作使用两个 $set 阶段在输出文档中包含三个新字段:
db.scores.aggregate( [
{
$set: {
totalHomework: { $sum: "$homework" },
totalQuiz: { $sum: "$quiz" }
}
},
{
$set: {
totalScore: { $add: [ "$totalHomework", "$totalQuiz" ] } }
}
] )
返回结果为:
{
"_id" : 1,
"student" : "Maya",
"homework" : [ 10, 5, 10 ],
"quiz" : [ 10, 8 ],
"totalHomework" : 25,
"totalQuiz" : 18,
"totalScore" : 43
}
{
"_id" : 2,
"student" : "Ryan",
"homework" : [ 5, 6, 5 ],
"quiz" : [ 8, 8 ],
"totalHomework" : 16,
"totalQuiz" : 16,
"totalScore" : 32
}
2.9 $unionWith 阶段
$unionWith 阶段将两个集合的管道结果合并为一个结果集,输出到下一阶段
比如一个名为 col 的集合有以下文档:
db.col1.insertMany( [
{ store: "General Store", item: "Chocolates", quantity: 150 },
{ store: "ShopMart", item: "Chocolates", quantity: 50 },
{ store: "General Store", item: "Cookies", quantity: 100 },
] )
比如一个名为 col2 的集合有以下文档:
db.col2.insertMany( [
{ store: "General Store", item: "Cheese", quantity: 30 },
{ store: "ShopMart", item: "Cheese", quantity: 50 },
{ store: "General Store", item: "Chocolates", quantity: 125 },
] )
下面的聚合创建一个 col_union 集合,使用 $unionWith 来组合 col1 和 col2 的文档:
db.col1.aggregate( [
{ $unionWith: "col2" }
] )
返回结果为:
{ "store" : "General Store", "item" : "Chocolates", "quantity" : 150 }
{ "store" : "ShopMart", "item" : "Chocolates", "quantity" : 50 }
{ "store" : "General Store", "item" : "Cookies", "quantity" : 100 }
{ "store" : "General Store", "item" : "Cheese", "quantity" : 30 }
{ "store" : "ShopMart", "item" : "Cheese", "quantity" : 50 }
{ "store" : "General Store", "item" : "Chocolates", "quantity" : 125 }
2.10 $merge 阶段
$merge 阶段将聚合管道的结果写入指定集合,它必须是管道中的最后一个阶段
https://www.mongodb.com/docs/v7.0/reference/operator/aggregation/merge/
第 3 章 索引
3.1 索引简介
索引支持 MongoDB 中查询的高效执行。如果没有索引,MongoDB 必须扫描集合中的每个文档才能返回查询结果。如果一个查询存在一个合适的索引,MongoDB 使用这个索引来限制它必须扫描的文档的数量。如果您的应用程序在相同的字段上重复运行查询,您可以在这些字段上创建索引以提高性能。
虽然索引提高了查询性能,但添加索引对写操作的性能有负面影响。对于具有高读写比率的集合,索引开销很大,因为每次插入都必须更新索引。
3.2 索引类型
3.2.1 单字段索引 Single Field Indexes
单字段索引存储来自集合中单个字段的信息。默认情况下,所有集合在 _id 字段上都有一个索引。可以在文档中的任何字段上创建单字段索引,包括顶层文档字段、嵌入的文档、以及嵌入文档中的字段。
创建索引时,需要指定在其上创建索引的字段和索引值的排序顺序:1 按升序排序、-1 按降序对值进行排序。
比如一个名为 schools 的集合有以下文档:
db.schools.insertOne(
{
"studentsEnrolled": 1000,
"location": { state: "NY", city: "New York" }
}
)
在 studentsEnrolled 字段上创建升序索引:
db.schools.createIndex( { studentsEnrolled: 1 } )
该索引可以支持 studentsEnrolled 字段的升序排序:
db.schools.find().sort({ studentsEnrolled: 1 })
也可以通过反向遍历索引来支持 studentsEnrolled 字段的降序排序:
db.schools.find().sort({ studentsEnrolled: -1 })
在 location.state 子字段上创建升序索引:
db.schools.createIndex( { "location.state": 1 } )
3.2.2 复合索引 Compound Indexes
MongoDB 支持在多个字段上自定义索引,即复合索引。复合索引中列出的字段顺序具有重要意义。例如一个复合索引为 { userid: 1, score: -1 },那么该索引首先按 userid 升序排序,然后在每个 userid 值内按 score 降序排序。
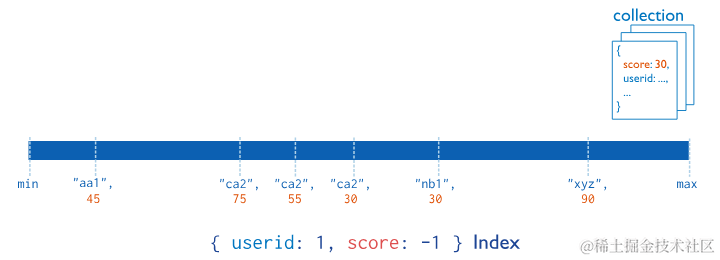
要创建复合索引,请使用以下原型:
db.<collection>.createIndex( {
<field1>: <sortOrder>,
<field2>: <sortOrder>,
...
<fieldN>: <sortOrder>
} )
对于使用复合索引进行排序的查询,sort 中所有键的指定排序方向必须与索引键模式匹配,或者逆匹配。例如,索引键模式 { a: 1, b: -1 } 可以支持 { a: 1, b: -1 } 和 { a: -1, b: 1 } 的排序,但不能支持 { a: -1, b: -1 } 或 { a: 1, b: 1 } 的排序。
如果排序键对应索引键的前缀,MongoDB 可以用该索引对查询结果进行排序。例如复合索引为:
db.data.createIndex( { a:1, b: 1, c: 1, d: 1 } )
下面查询和排序操作使用索引前缀对结果进行排序,而不是使用内存中的结果集:
| 例子 | 使用复合索引前缀 |
|---|---|
| db.data.find().sort( { a: -1, b: -1 } ) | { a: 1, b: 1 } |
| db.data.find( { a: { $gt: 4 } } ).sort( { a: 1, b: 1 } ) | { a: 1, b: 1 } |
| db.data.find( { a: 5, b: { $lt: 3} } ).sort( { b: 1 } ) | { a: 1, b: 1 } |
在查询文档中,只有排序子集前面的索引字段必须使用相等条件,其它索引字段可以指定其它条件。如果没有在与排序规范重叠的索引前缀上指定相等条件,则命令不会有效使用索引。例如:
db.data.find( { a: { $gt: 2 } } ).sort( { c: 1 } )
db.data.find( { c: 5 } ).sort( { c: 1 } )
这两个操作命令不会有效使用 index { a: 1, b: 1, c: 1, d: 1 }。
3.2.3 多键索引 Multikey Indexes
多键索引从包含数组值的字段中收集和排序数据。多键索引提高了对数组字段查询的性能。如果索引字段包含数组值,MongoDB 会自动判断是否创建多键索引,不需要显式指定索引是多键类型。
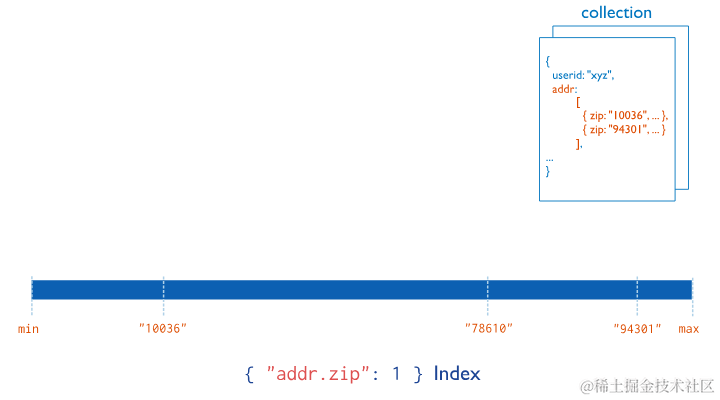
要创建一个多键索引,请使用以下原型:
db.<collection>.createIndex( { <arrayField>: <sortOrder> } )
3.2.4 文本索引 Text Indexes
文本索引支持对包含字符串内容的字段进行文本搜索查询。在搜索字符串内容中的特定单词或短语时,文本索引可以提高性能。一个集合只能有一个文本索引,但该索引可以覆盖多个字段。
要创建一个文本索引,请使用以下原型:
db.<collection>.createIndex(
{
<field1>: "text",
<field2>: "text",
...
}
)
3.2.5 哈希索引 Hashed Indexes
哈希索引支持使用哈希分片键进行分片,哈希分片键使用字段的哈希索引作为分片键,在分片集群中对数据进行分区。哈希分片键对集合进行分片可以使数据分布更均匀。
以 _id 字段创建一个哈希索引:
db.col.createIndex( { _id: "hashed" } )
也可以创建一个复合哈希索引:
db.col.createIndex( { "fieldA" : 1, "fieldB" : "hashed", "fieldC" : -1 } )
在包含数组的字段上创建哈希索引,或试图将数组插入哈希索引字段都将返回错误。MongoDB 不支持在哈希索引上指定唯一约束。
3.3 索引属性
3.3.1 TTL indexes
TTL 索引是一种特殊的单字段索引,MongoDB 可以使用它在一定时间后自动从集合中删除文档,适用于建立在只需要保存有限时间的字段数据上。
例如,要为 eventlog 集合的 lastModifiedDate 字段创建 TTL 索引,TTL 值为 3600 秒:
db.eventlog.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } )
- 如果字段是一个数组,并且数组元素为多个日期值,那么使用数组中最早的日期值来计算过期阈值
- 如果 TTL 索引字段不是日期值或者是日期值的数组,那么文档不会过期
- _id 字段不支持 TTL 索引。TTL 索引是一种单字段索引,复合索引不支持 TTL。如果一个字段已经存在非 TTL 单字段索引,则该字段不能再创建 TTL 索引
3.3.2 Unique indexes
唯一索引保证被索引的字段不会存储重复的值,创建集合时默认在 _id 字段上创建唯一索引。
例如,在 members 集合的 user_id 字段创建唯一索引:
db.members.createIndex( { "user_id": 1 }, { unique: true } )
该可以创建复合唯一索引,此时 MongoDB 会对索引键值的组合强制唯一:
db.members.createIndex( { groupNumber: 1, lastname: 1, firstname: 1 }, { unique: true } )
3.3.3 Partial indexes
部分索引仅对集合中满足指定过滤器表达式的文档进行索引。部分索引具有较低的存储需求,并降低索引创建和维护的性能成本。
例如,创建一个复合索引,该索引仅在 rating 字段大于 5 的文档上生效:
db.restaurants.createIndex(
{ cuisine: 1, name: 1 },
{ partialFilterExpression: { rating: { $gt: 5 } } }
)
3.3.4 Hidden indexes
隐藏索引对查询规划器不可见,不能用于查询。通过隐藏索引,用户可以在不实际删除索引的情况下评估删除索引的负面影响。
例如,在 borough 字段上创建一个隐藏升序索引:
db.addresses.createIndex(
{ borough: 1 },
{ hidden: true }
);
例如,对指定字段创建隐藏索引:
db.addresses.hideIndex( { borough: 1 } );
或者指定索引名创建隐藏索引:
db.addresses.hideIndex( "borough_1" );
取消隐藏索引则使用 unhideIndex 命令。
3.4 索引管理
3.4.1 查看索引
db.col.getIndexes()
3.4.2 删除索引
db.col.dropIndex("index")
db.col.dropIndexes()
3.5 获取索引访问信息
3.5.1 $indexStats
使用 $indexStats 聚合阶段获取关于集合的每个索引使用情况的统计信息。例如,下面的聚合操作返回 order 集合上索引使用的统计信息:
db.orders.aggregate( [ { $indexStats: { } } ] )
3.5.2 使用 explain() 返回查询计划
在 executionStats 模式下使用 db.collection.explain() 或 cursor.explain() 方法返回关于查询过程的统计信息,包括使用的索引、扫描的文档数量和处理查询所需的时间(以毫秒为单位)。
在 allplansexexecution 模式下运行 db.collect .explain() 或 cursor.explain() 方法,查看在计划选择期间收集的部分执行统计信息。
第 4 章 安全
MongoDB 提供了各种功能,例如身份验证、访问控制、加密,以确保 MongoDB 部署的安全性。
| 身份验证 | 授权 | TLS/SSL |
|---|---|---|
| Authentication | Role-Based Access Control(基于角色的访问控制) | TLS/SSL (传输加密) |
| SCRAM | Enable Access Control(启用访问控制) | 配置 TLS/SSL 的 mongod 和 mongos |
| x.509 | 管理用户和角色 | 客户端 TLS/SSL 配置 |
4.1 Enable Access Control
启用访问控制会强制进行身份验证,要求用户只能执行其角色决定的操作。
4.1.1 创建管理用户
连接 mongo 实例:
mongo --port 27017
例如,在 admin 数据库中创建用户 root ,角色为 admin 数据库的 root:
use admin
db.createUser(
{
user: "root",
pwd: "123",
roles: [ { role: "root", db: "admin" } ]
}
)
4.1.2 重启具有访问控制的 mongo 实例
db.adminCommand( { shutdown: 1 } )
exit
在配置文件中添加:
security:
authorization: enabled
连接到该实例的客户端现在必须认证 MongoDB 用户,客户端只能执行由其分配角色决定的操作。
4.1.3 以用户管理员身份进行连接和身份验证
mongo --port 27017 -u "root" -p 123
4.1.4 创建其他用户
通过管理员用户身份验证后,使用 db.createUser() 创建其他用户。
例如将用户 myTester 添加到 test 数据库,该用户在 test 数据库具有 readWrite 角色,在 reporting 数据库具有 read 角色:
use test
db.createUser(
{
user: "myTester",
pwd: "123",
roles: [ { role: "readWrite", db: "test" },
{ role: "read", db: "reporting" } ]
}
)
创建该用户后,断开 mongo 连接。
4.1.5 以 myTester 身份验证连接 mongo 实例
mongo --port 27017 -u "myTester" --authenticationDatabase "test" -p 123
4.2 Authentication
MongoDB 支持一下身份验证机制:
- SCRAM ,默认鉴权机制,分为 SCRAM-SHA-1 和 SCRAM-SHA-256
- x.509 证书认证,用于副本集和分片集群成员的客户端认证和内部认证,需要一个安全的 TLS / SSL 连接
4.3 Role-Based Access Control
MongoDB 使用基于角色的访问控制 Role-Based Access Control 来管理安全。
4.3.1 内置角色
MongoDB 为每个数据库提供内置的数据库用户和数据库管理角色,只在 admin 数据库提供所有其它内置角色。
| 角色 | 权限 | 分类 |
|---|---|---|
| root | readWriteAnyDatabase + dbAdminAnyDatabase + userAdminAnyDatabase + clusterAdmin + restore + backup | 超级用户角色 |
| readAnyDatabase | 提供除 local 和 config 数据库外所有数据库的只读权限 | 所有数据库角色 |
| readWriteAnyDatabase | 提供除 local 和 config 数据库外所有数据库的读写权限 | 所有数据库角色 |
| dbAdminAnyDatabase | 提供除 local 和 config 数据库外所有数据库的管理权限 | 所有数据库角色 |
| userAdminAnyDatabase | 提供除 local 和 config 数据库外所有数据库的用户管理权限 | 所有数据库角色 |
| read | 读取所有非系统集合和 system.js 集合 | 单个数据库用户角色 |
| readWrite | 读写所有非系统集合和 system.js 集合 | 单个数据库用户角色 |
| dbAdmin | 在当前数据库执行管理权限 | 单个数据库管理角色 |
| userAdmin | 在当前数据库执行用户管理权限 | 单个数据库管理角色 |
| dbOwner | 对数据库执行任何管理操作,结合了 readWrite、dbAdmin、userAdmin 角色授予权限 | 单个数据库管理角色 |
| clusterManager | 提供集群管理和监控操作 | 集群管理角色 |
| clusterMonitor | 提供对监控工具的只读访问 | 集群管理角色 |
| hostManager | 提供监控和管理服务端的能力 | 集群管理角色 |
| clusterAdmin | 提供最大的集群管理权限,结合了 clusterManager、clusterMonitor、hostManager 角色授予权限 | 集群管理角色 |
| backup | 备份数据 | 备份恢复角色 |
| restore | 恢复数据 | 备份恢复角色 |
4.3.2 用户管理
| 命令 | 说明 |
|---|---|
| db.auth() | 将用户身份验证到对应数据库 |
| db.changeUserPassword() | 修改已有用户的密码 |
| db.createUser() | 创建新用户 |
| db.dropUser() | 删除数据库的某个已有用户 |
| db.dropAllUsers() | 删除数据库的所有已有用户 |
| db.getUser() | 返回指定用户的信息 |
| db.getUsers() | 返回该数据库所有用户的信息 |
| db.grantRolesToUser() | 将角色及其权限授予用户 |
| db.revokeRolesFromUser() | 移除用户的角色 |
| db.updateUser() | 更新用户数据 |
4.3.3 角色管理
| 命令 | 说明 |
|---|---|
| db.createRole() | 创建角色并指定其权限 |
| db.dropRole() | 删除用户自定义角色 |
| db.dropAllRoles() | 删除该数据库所有用户自定义角色 |
| db.getRole() | 返回指定角色的信息 |
| db.getRoles() | 返回该数据库所有用户自定义角色的信息 |
| db.grantPrivilegesToRole() | 为用户自定义角色分配权限 |
| db.revokePrivilegesFromRole() | 删除用户自定义角色的指定权限 |
| db.grantRolesToRole() | 指定该用户自定义角色继承的角色 |
| db.revokeRolesFromRole() | 从角色中删除其继承的角色 |
| db.updateRole() | 更新用户自定义角色数据 |
第 5 章 MongoDB 副本集
MongoDB 副本集是一组维护相同数据集的 MongoDB 实例。副本集的主要成员包括主节点、从节点以及仲裁节点。
5.1 主节点 Primary
在副本集中,有且只有一个主节点能够接收和确认所有写操作,主节点将其数据集的所有写操作记录在操作日志 oplog 中。
副本集的所有成员都可以接收读操作,但是在默认情况下客户端将其读操作定向到主节点。如果要修改该默认行为,参考 5.8 节。
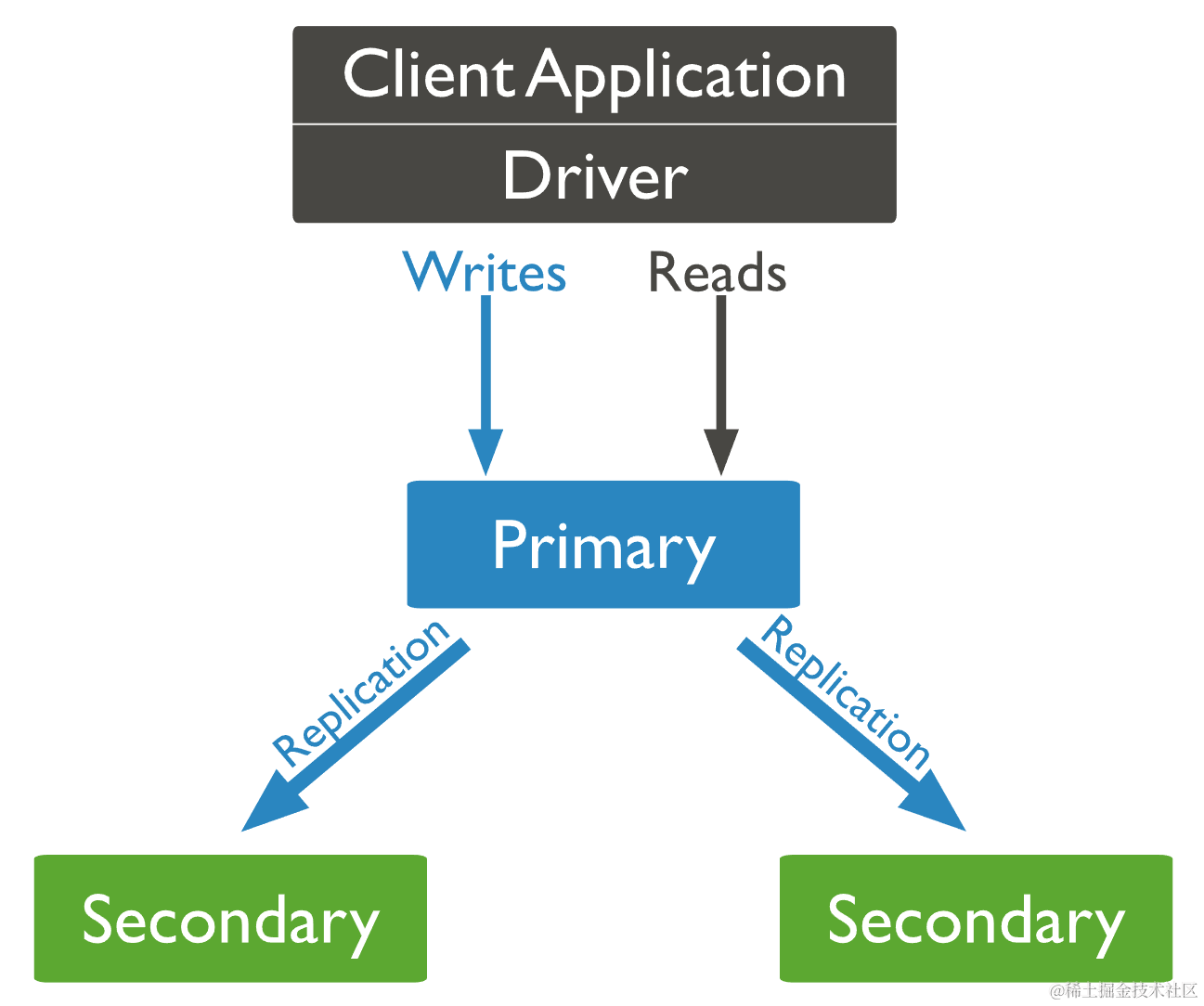
5.2 从节点 Secondary
从节点异步地复制主节点的 oplog,并将操作应用于自身数据集。一个副本集可以有多个从节点。
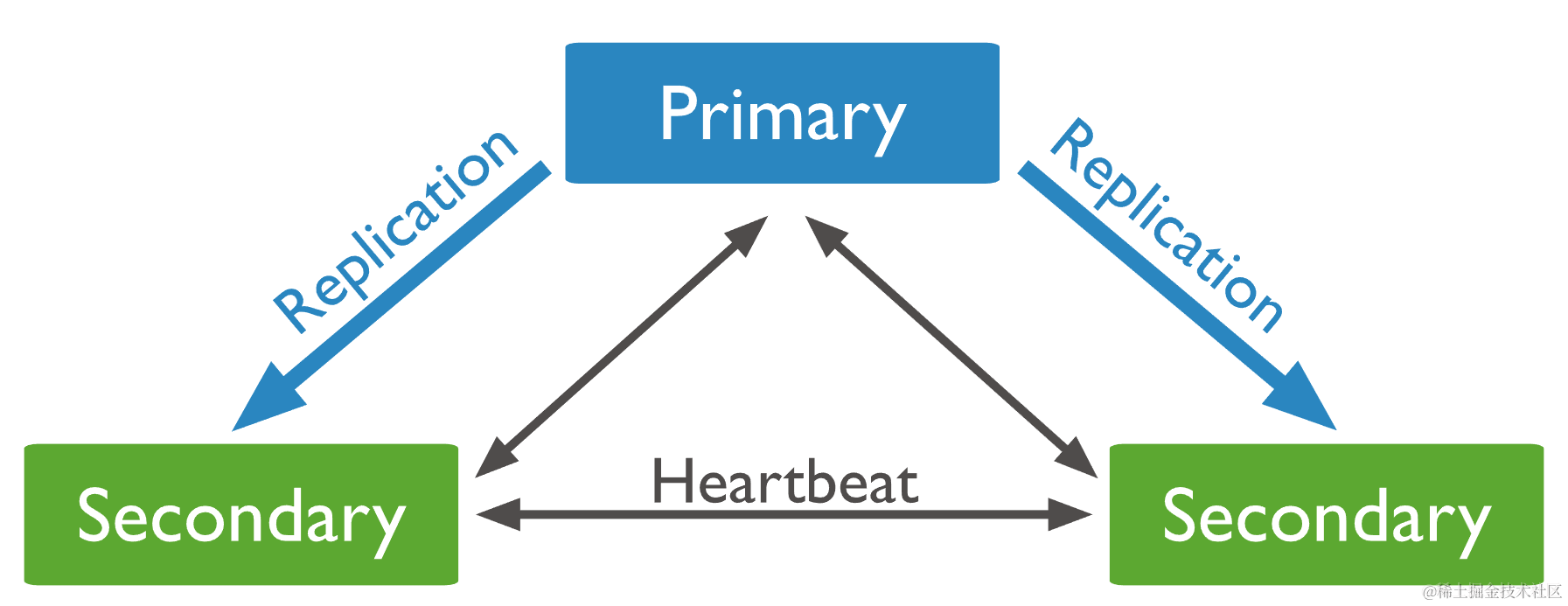
副本集成员之间每两秒向彼此发送心跳。当主节点超过配置的 electionTimeoutMillis(默认 10s)周期时间内没有与其他成员通信,则被认为不可用。此时会触发一次选举,从剩余的从节点中选举一个作为新的主节点。在选举完成前无法处理写操作。
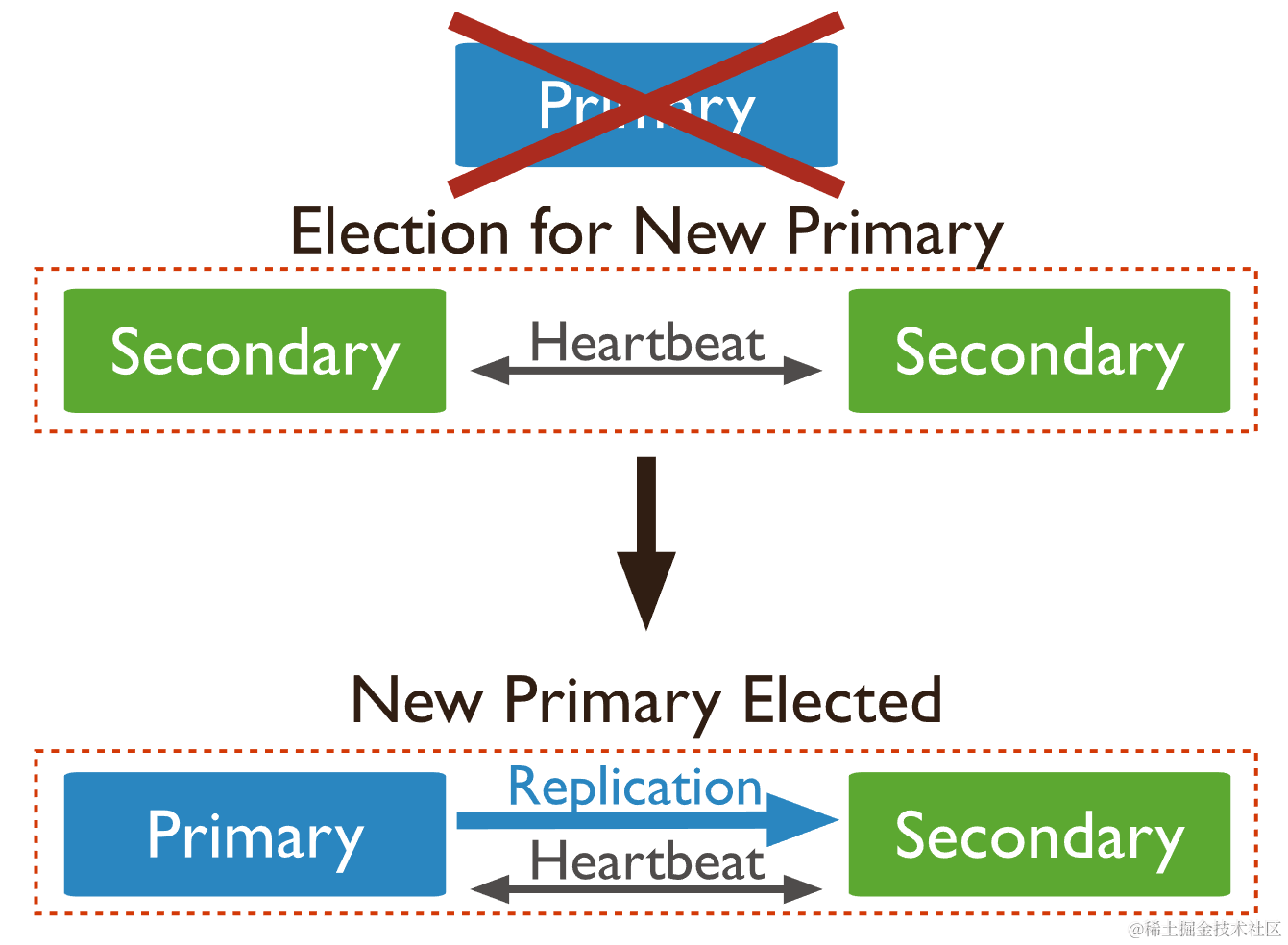
5.3 仲裁节点 Arbiter
仲裁节点只参与主节点选举(占一个投票权),而不持有数据。仲裁节点的优先级默认为 0,仲裁节点永远是仲裁节点,不会变成主节点或从节点。
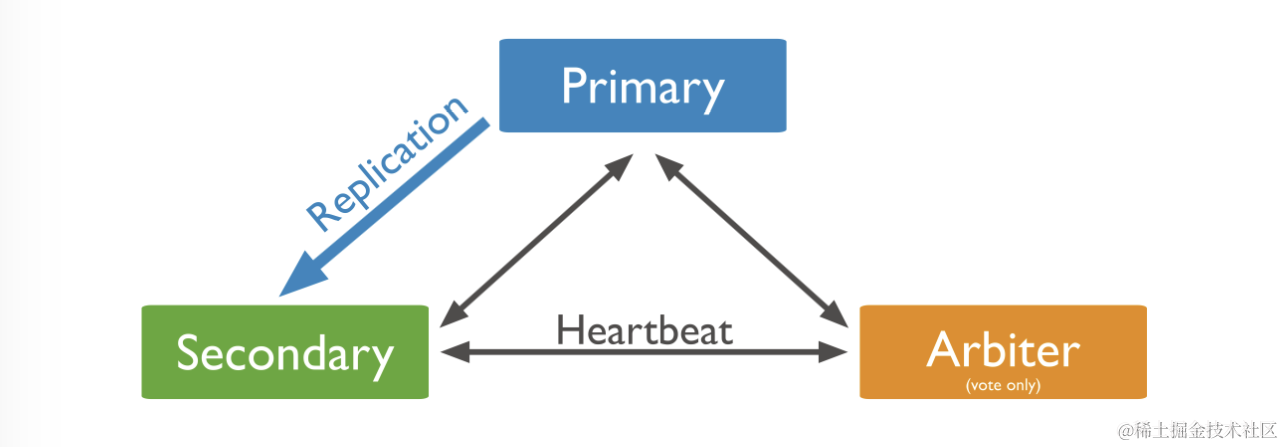
5.4 优先级为 0 的从节点
优先级 priority 为 0 的从节点不能被选举为主节点。除此之外,该从节点功能和普通从节点一样。
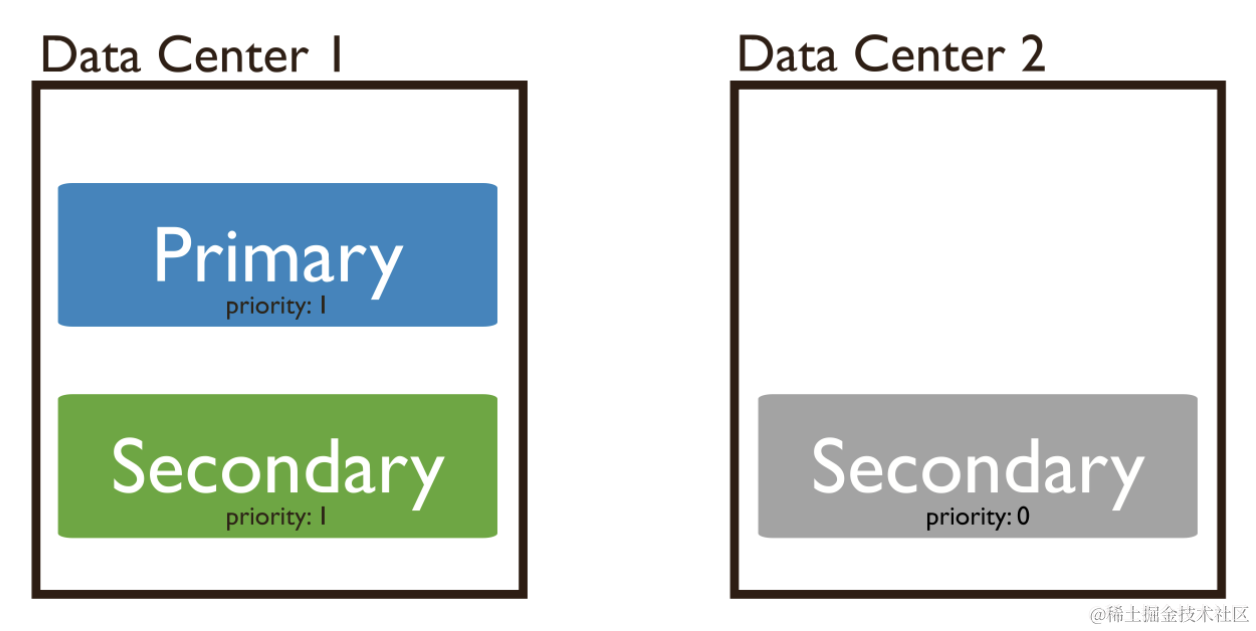
5.5 无投票权的从节点
如果将 priority 为 0 的从节点的 votes 属性也设为 0 ,那么它也失去了投票权。无投票权的成员优先级一定是 0。
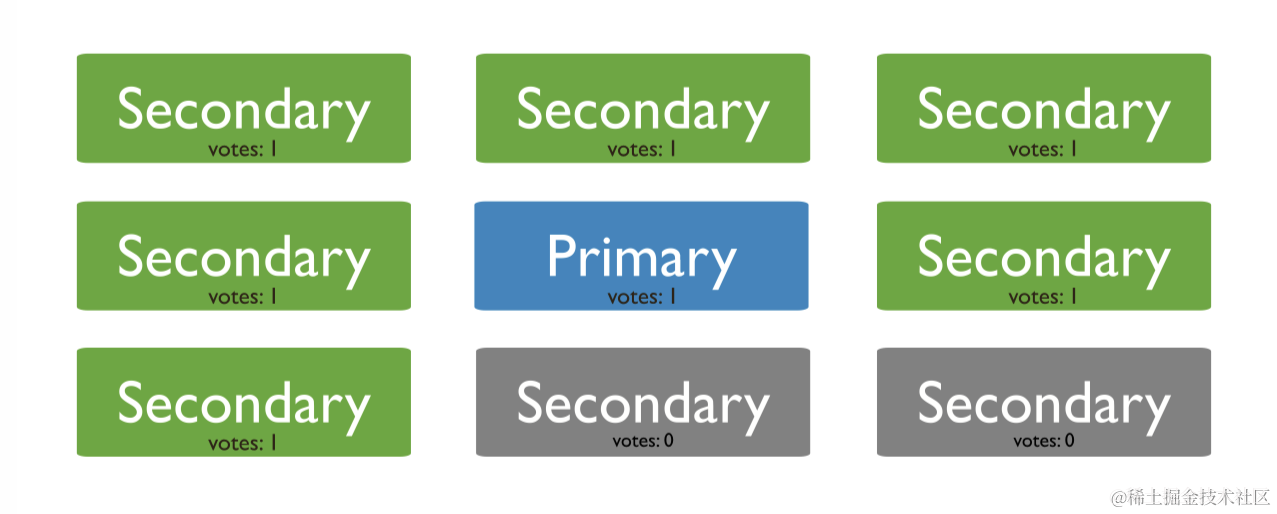
5.6 隐藏节点
隐藏节点首先必须是优先级为 0 的从节点,然后它的 hidden 属性为 true。隐藏节点对客户端不可见,即客户端不会读到隐藏节点的数据,其它功能与普通从节点一样,专门用于维护主节点数据集。

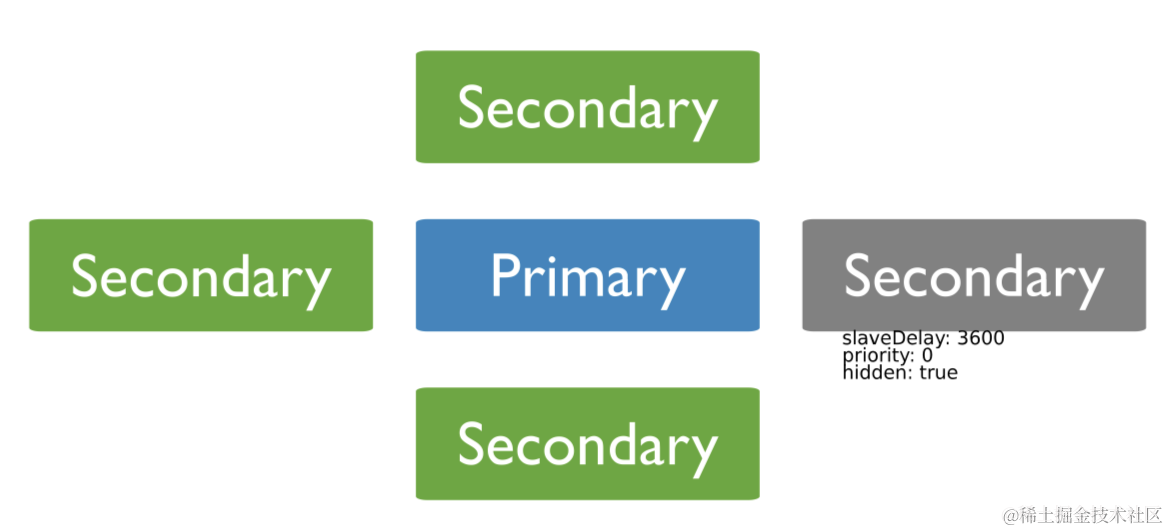
5.7 延迟节点
延迟节点首先必须是优先级为 0 的隐藏节点,然后设置了 slaveDelay 属性不为 0。
延迟节点包含较早(延迟)状态的副本集数据集,例如当前时间为 9:00,延迟节点有一小时延迟,那么该延迟节点中不会有 8:00 之后的操作。
延迟节点作为数据集的滚动备份或运行的历史快照,可以帮助我们恢复副本集。
5.8 读取首选项

默认情况下,客户端从主节点读取数据。但是客户端可以指定读取首选项:
| Read Preference | 说明 |
|---|---|
| primary | 默认模式,只从主节点中读取,保证数据是最新的。包含读操作的多文档事务必须使用该模式 |
| primaryPreferred | 大多数情况读取主节点,主节点不可用时可以读取副节点 |
| secondary | 只从副节点中读取 |
| secondaryPreferred | 大多数情况读取副节点,副节点都不可用时可以读取主节点 |
| nearest | 根据指定的延迟阈值,从随机的符合条件的副本集成员中读取 |
5.9 oplog
5.9.1 oplog 简介
oplog 是一个特殊的有大小上限的集合,保留了修改数据库存储数据的滚动记录。副本集中的成员可以从其它任何成员导入 oplog 记录。
oplog 中的每个操作都是幂等的。也就是说,无论对目标数据集应用一次还是多次,oplog 操作都会产生相同的结果。
5.9.2 oplog 大小
当第一次启动副本集成员时,如果没有指定 oplog 大小,则创建默认大小:如果是 WiredTiger 存储引擎,oplog 初始大小为可用磁盘空间的 5%。最小值为 990MB,最大值为 50GB。
在 mongod 创建 oplog 时,可以使用 oplogSize 选项指定 oplog 的大小。在第一次启动副本集成员后,也可以使用 replSetResizeOplog 命令更改 oplog 的大小。
5.9.3 oplog 保留最小时间
当 oplog 达到最大配置大小,且 oplog 记录时间超过配置的最小小时数,MongoDB 会删除 oplog 记录。
可以在配置文件中指定保留 oplog 条目的最小小时数 storage.oplogMinRetentionHours。
5.9.4 oplog 窗口
oplog 记录带有时间戳,oplog 窗口是 oplog 中最新和最旧的时间戳之间的时间差。如果从节点失去与主节点的连接,那么只有在 oplog 窗口内恢复连接,从节点才能再次使用复制进行同步。
5.10 副本集数据同步
副本集的从节点同步或复制其它成员的数据。MongoDB 使用两种形式的数据同步:全量同步 initial sync 和增量复制 replication 。
5.10.1 initial sync
initial sync 将所有数据从副本集的一个成员拷贝到另一个成员。初始同步源取决于配置文件 initialSyncSourceReadPreference 的值,默认为 primary。
5.10.2 replication
从节点在初始同步后持续复制数据,从同步源中复制 oplog,并异步执行应用这些操作。同步源的选择取决于副本集链接设置,当启用链接时,从副本集成员中选择同步源;当禁用链接时,选择主节点为同步源。
5.11 副本集体系架构
生产系统的标准副本集部署是一个包含三个成员的副本集(一主一从一仲裁)。
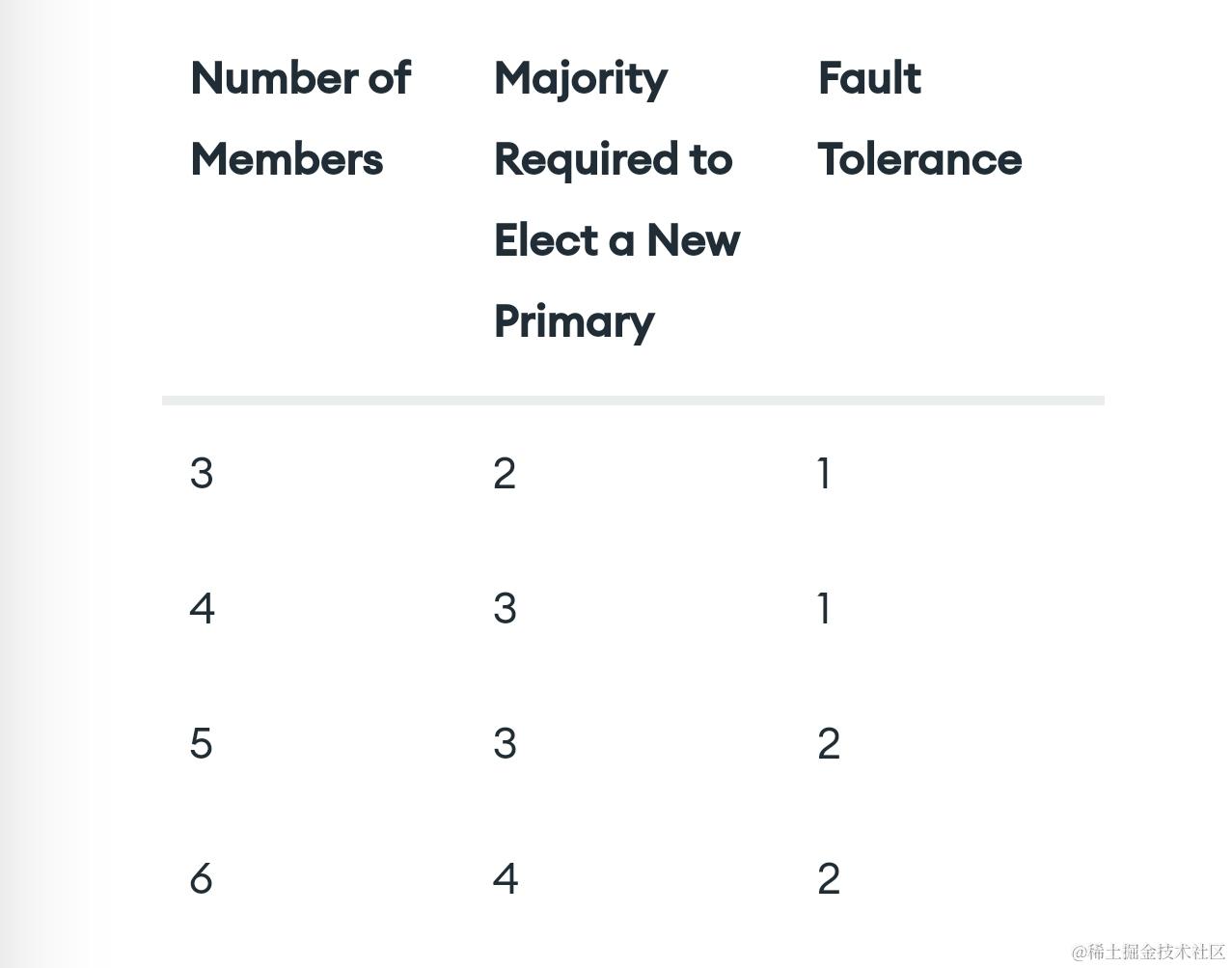
5.11.1 投票成员的最大数
一个副本集最多可以有 50 个成员,但是最多只能有 7 个有投票权的成员。投票成员的数量保证为奇数个。
5.11.2 考虑容错
副本集的容错指在不可用的情况下,仍然有足够的成员留在副本集中选举新的主节点。
5.12 副本集高可用性
5.12.1 选举
副本集通过选举来确定主节点。在选举完成前,副本集无法处理写操作。副本集触发选举的情况有:
- 向副本集添加一个新节点
- 启动副本集
- 从节点与主节点失去连接的时间超过配置的超时时间
- 使用 rs.stepDown() 或 rs.reconfig() 等方法执行副本集维护
5.12.2 副本集故障转移期间的回滚
当成员在故障转移后重新加入副本集时,回滚恢复对前主节点的写操作。当前主节点作为从节点重新加入该副本集时,它需要回滚其写操作,以维护与其它成员的数据库一致性。
如果写操作在主节点故障之前复制到副本集的另一个成员,并且该成员仍然可用,也不会发生回滚。
第 6 章 MongoDB 分片
分片是一种跨机器分发数据的方法,MongoDB 支持通过分片进行水平扩展,来支持非常大的数据集和高吞吐量操作的部署。
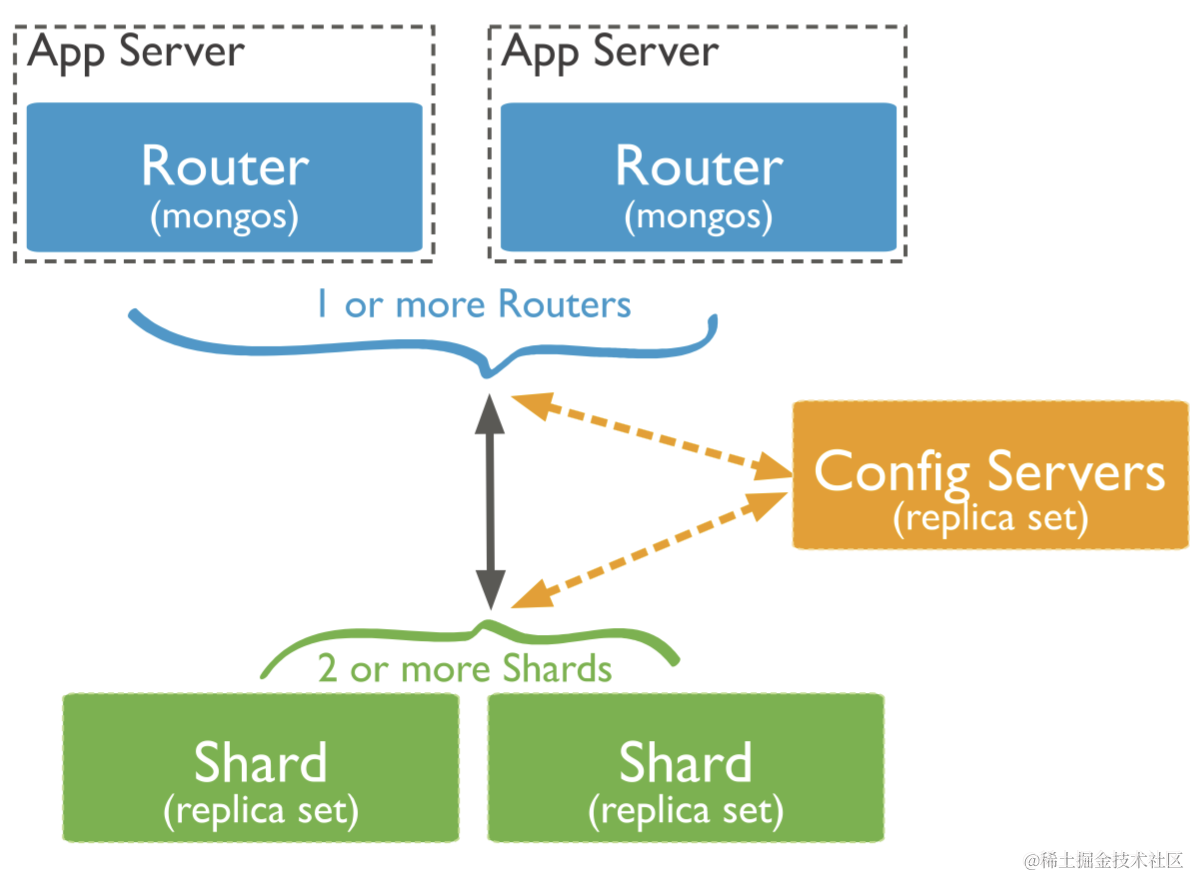
6.1 分片集群 Shared cluster
MongoDB 分片集群由以下组件组成:
- 分片 shard:每个分片包含一个分片数据子集,每个分片都部署为一个副本集
- 配置服务器副本集 config servers replica set(CSRS):存储分片集群的元数据和配置
- 查询路由器 mongos:提供客户端与分片集群之间的接口
6.1.1 分片 Shard
每个分片都作为一个副本集部署。
分片集群的每个数据库都有一个主分片 primary shard,用于保存该数据库所有未分片的集合。查询路由器 mongos 在创建一个新数据库时,通过在分片集群中选择数据量最少的分片来作为该数据库的主分片。
6.1.2 配置服务器 Config Servers
配置服务器存储分片集群的元数据,元数据包括每个分片上的块列表以及块的范围。
配置服务器还存储身份验证配置信息,如基于角色的访问控制 RBAC 或内部身份验证设置。
mongos 实例缓存这些数据,并使用这些数据将读写操作路由到正确的分片。
6.1.3 路由 Mongos
路由通过缓存来自 config servers 的元数据来跟踪哪些数据在哪些分片上。mongos 使用元数据将客户端操作路由到 mongos 实例中。
6.2 分片键 Shared Key
MongoDB 使用分片键将集合的文档分布到不同的分片上,即文档的分片键决定了文档的分片。分片键由文档中一个或多个字段组成。
6.2.1 分片键规范
在对集合进行分片时,必须指定分片键。使用 sh.shardCollection() 来对集合进行分片:
sh.shardCollection(<namespace>, <key>)
| 参数 | 说明 |
|---|---|
| namespace | “<database>.<collection>”,集合的完整名称空间 |
| key | { <shard key field1>: <1 | “hashed”>, … } ,指定文档字段作为 shard key,1 表示范围分片,“hashed” 表示哈希分片 |
6.2.2 分片键索引
所有已分片的集合必须有一个支持该分片键的索引。索引可以是分片键上的索引,也可以是复合索引,其中分片键是索引的前缀。
- 如果集合是空的,使用分片命令 sh.shardCollection() 会在分片键上创建索引(如果索引不存在的话)
- 如果集合不是空的,在使用分片命令 sh.shardCollection() 之前必须先创建索引
6.2.3 分片键选择
分片键的选择会影响块在可用分片上的创建和分布,从而影响分片集群内操作的整体效率和性能。MongoDB 支持两种分片策略:
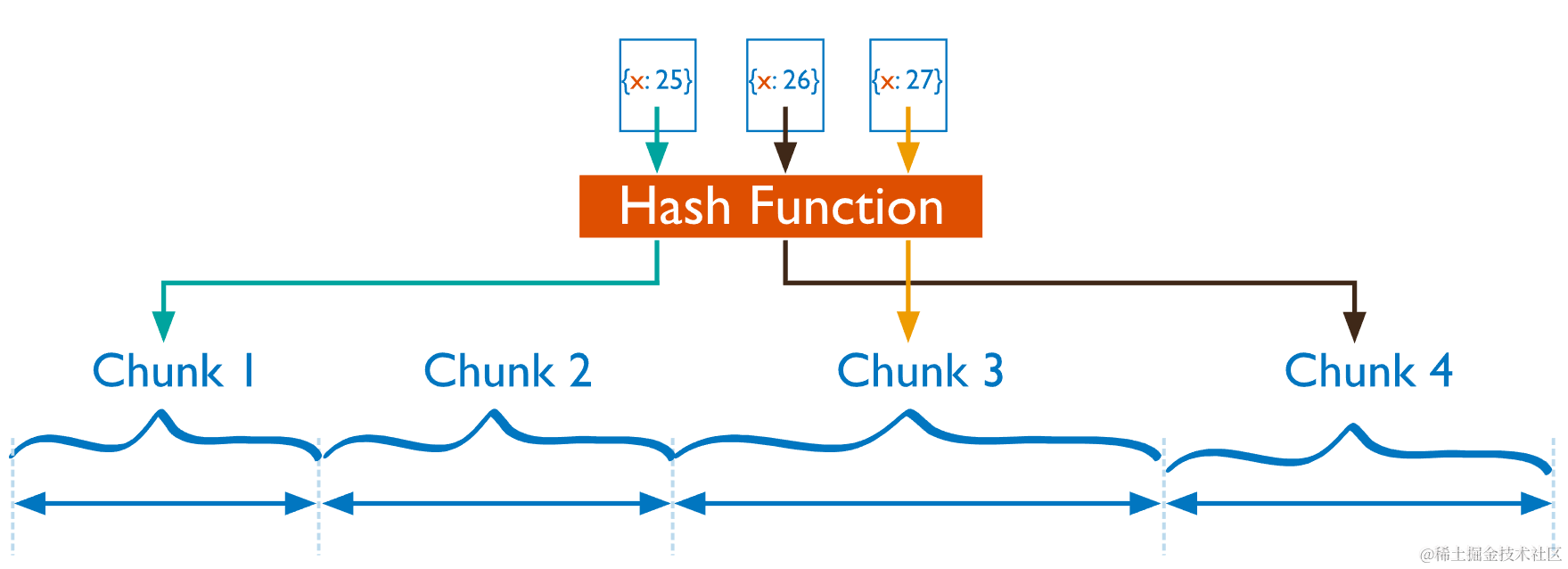
-
哈希分片 hashed sharding:哈希分片使用 「单字段哈希索引」 或「复合哈希索引」作为跨分片集群分区数据的分片键
- 单字段哈希索引:哈希索引计算单字段的哈希值作为索引值,同时这个值用作分片键
- 复合哈希索引:复合哈希索引计算复合索引中单字段的哈希值,该值与索引中其他字段一起用作分片键
-
范围分片 ranged sharding:根据分片键值将数据划分为若干范围。然后根据分片键值为每个块分配一个范围
- 范围分片适用于字段的值范围非常大,出现的频率低,并且以非单调速率变化
两种分片策略的对比如下:
- 范围分片方式提供高效的范围查询,给定一个分片键的范围,分发路由可以很简单地确定哪个数据块存储了请求需要的数据,并将请求转发到相应的分片中。不过范围分片会导致数据在不同分片上的不均衡。如果分片键所在的字段是线性增长的,一定时间内的所有请求都会落到某个固定的数据块中,最终导致分布在同一个分片中,一小部分分片承载了集群大部分的数据
- 哈希分片以范围查询性能的损失为代价,保证了集群中数据的均衡。哈希值的随机性使数据随机分布在每个数据块中,因此也随机分布在不同分片中。
- 一般推荐使用哈希分片,并且使用文档的 _id 字段作为分片键。因为它是必有的,同时能够保证每个文档都有不同的分片键,数据分块更精细
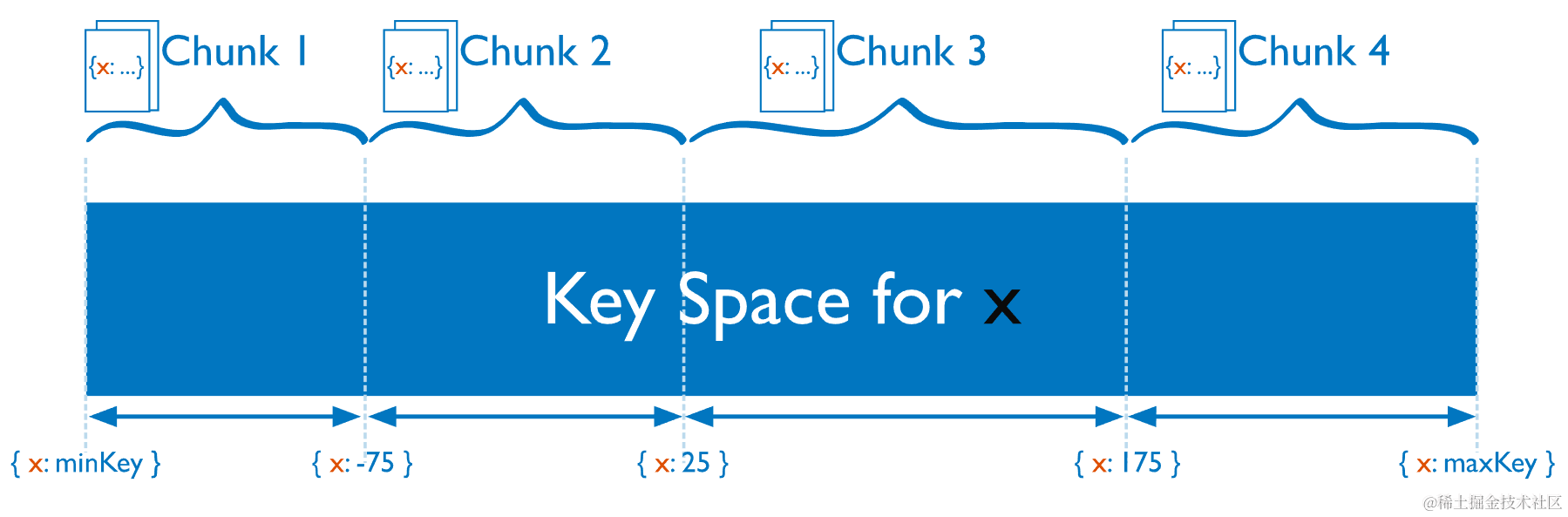
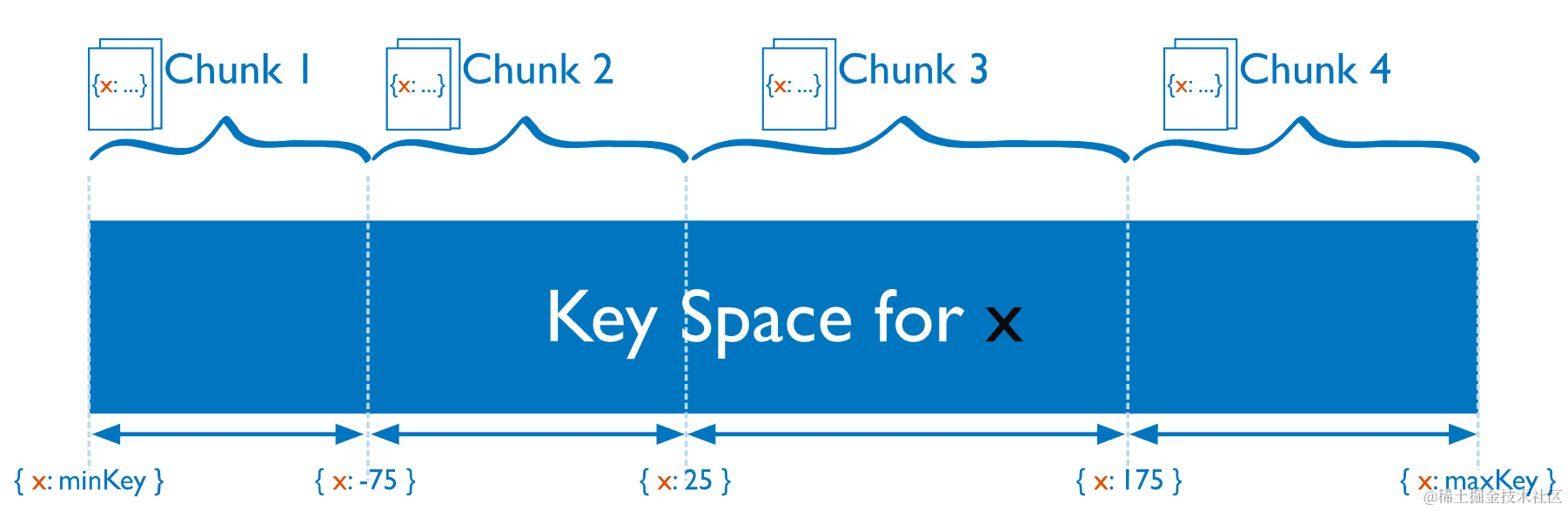
6.3 块 Chunk
MongoDB 将分片键的值的跨度划分为不重叠的分片键值范围,每个左闭右开的范围称为一个块。块均匀地分布在分片之间。如下图所示,分片键 X 的值被分为四个块:
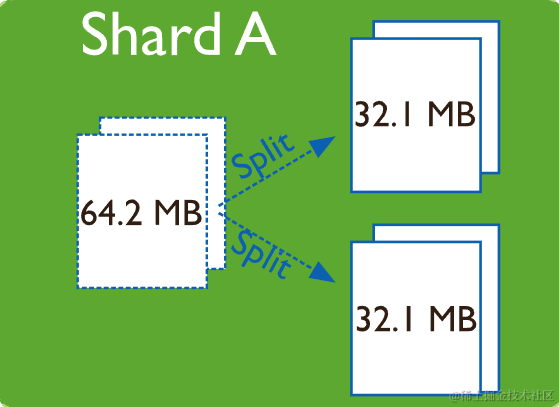
6.3.1 块拆分
当一个块增长超过指定的数据块大小,或者数据块中的文档数超过了每个数据块迁移的最大文档数,MongoDB 会进行块拆分。
块拆分可能导致集合的块在多个分片之间分布不均匀。在这种情况下,平衡器会跨分片重新分配块。
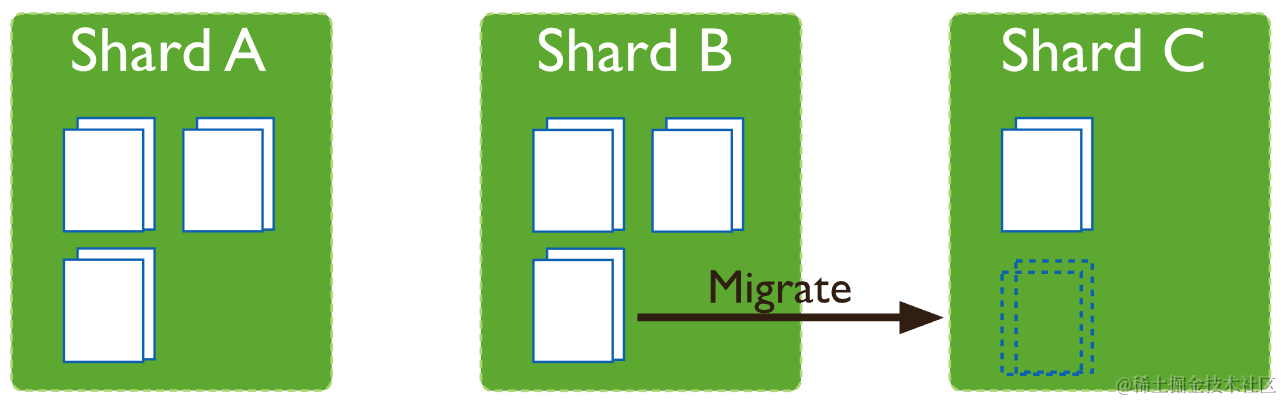
6.3.2 块迁移
平衡器 balancer 是一个管理块迁移的后台进程。当分片集合中块数量最多的分片与该分片集合中块数量最少的分片之间的块数量差达到迁移阈值,则平衡器开始跨集群迁移块,以确保数据均匀分布。平衡器在配置服务器副本集(CSRS)的主节点上运行。
6.3.3 块初始化
- 如果集合不为空,分片操作创建初始块,覆盖整个分片键值范围。创建的块数量取决于配置块大小(默认 64 M)。在初始块创建之后,平衡器 balancer 在适当的情况下跨分片迁移这些初始块,并管理块的分发
- 如果集合为空,分片操作为定义的区域范围创建空块,以及覆盖整个分片键值范围的任何附加块,并根据区域范围执行初始块分布
6.3.4 块大小
- 小块使数据分布更均匀,但代价是更频繁的迁移,在查询路由层 mongos 造成了开销
- 大块能有较少的数据迁移,减少路由开销。但是以潜在的数据不均匀分布为代价
- 在许多实际部署中,应避免频繁的迁移,所以块不能设置太小
6.4 分区 Zone
在分片集群中,可以根据分片键创建分区。每个分区与集群中一个或多个分片关联。一个分片可以与任意数量的分区相关联。一个分区覆盖的每一个范围总是包括它的下界而不包括它的上界。
下图展示了一个包含三个分片和两个分区的分片集群。A 分区下界为 1,上界为 10。B 分区下边界为 10,上边界为 20。Alpha 和 Beta 分片在 A 分区,Beta 分片也有在 B 分区。Charlie 分片没有相应的分区。分区之间没有共享和重叠范围([A]X:1-10;[B]X:10-20):
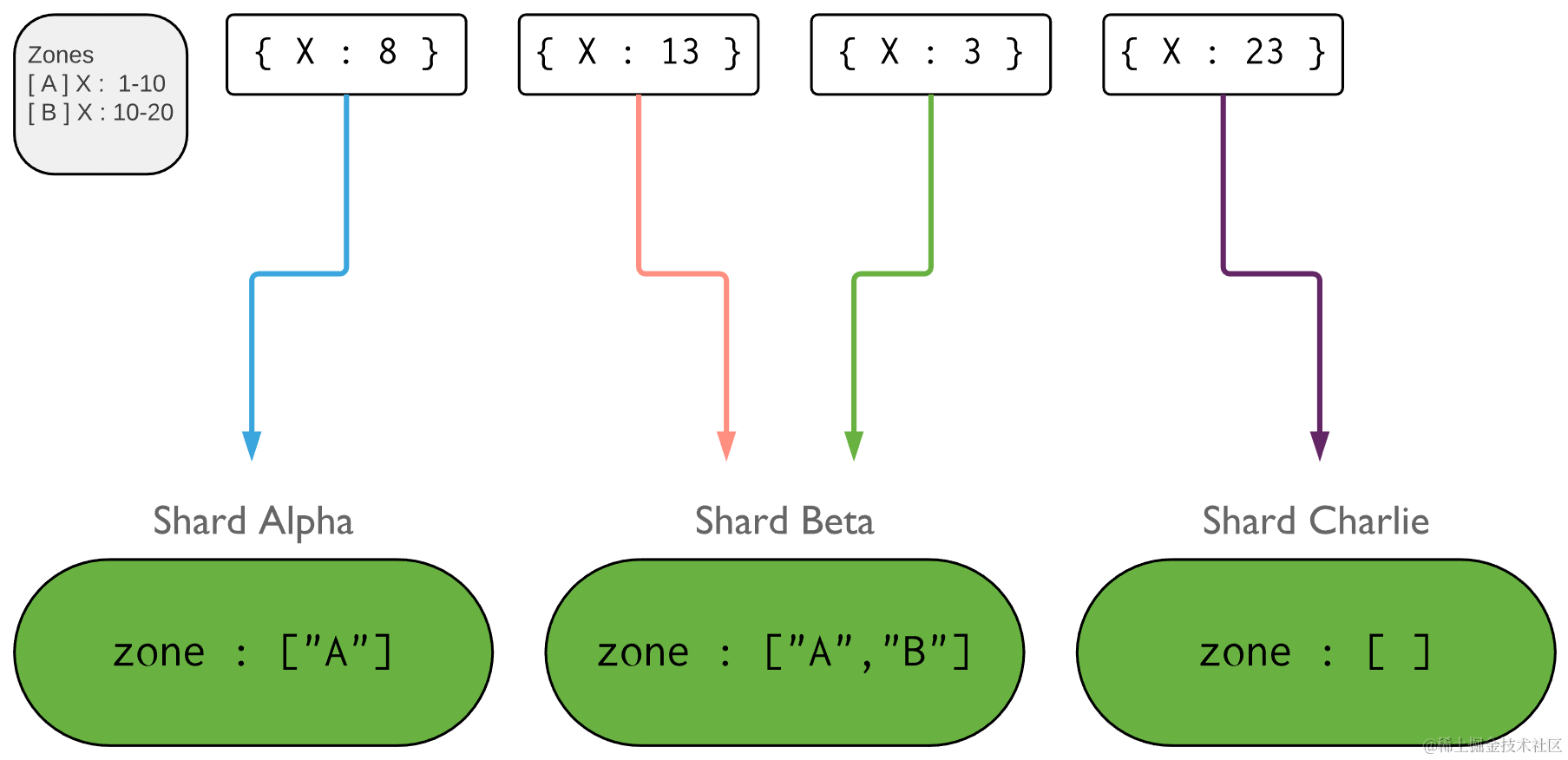
在一个平衡的集群中,MongoDB 只会将一个分区覆盖的块迁移到与该分区关联的那些分片上。
第 7 章 MongoDB 分片搭建
分片架构:两个分片节点副本集(3+3)+ 一个配置服务器副本集(3)+ 三个路由节点(3),共 12 个服务节点。
7.1 修改系统配置
修改系统进程允许打开的最大文件句柄,默认是 1024,改为 65535:
ulimit -SHn 65535
修改文件:
sudo vim/etc/security/limits.conf
# 在打开的文件中添加以下几行:
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 65535
保存并退出,使用以下命令查看句柄是否改为 65535:
ulimit -n
7.2 初始化 mongo-server 配置
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-ubuntu1804-4.4.14.tgz
mkdir mongoldb
tar -zxvf mongodb-linux-x86_64-ubuntu1804-4.4.14.tgz -C ./mongodb --strip-components 1
cd mongoldb/bin
mkdir conf data log pid
vim keyfile
# keyfile 的内容自定义
"keyfile content"
# 保存退出后给文件授予执行权限
sudo chmod 600 keyfile
7.3 在三个节点上部署 Config Server Replica Set(CSRS)
CSRS 由一个主节点和两个从节点组成。
vim ./mongodb/bin/conf/config
sharding:
clusterRole: configsvr
storage:
dbPath: "/home/ubuntu/mongodb/bin/data"
journal:
enabled: true
systemLog:
destination: file
logAppend: true
path: " /home/ubuntu/mongodb/bin/log/mongo.log"
processManagement:
fork: true
pidFilePath: "/home/ubuntu/mongodb/bin/pid/mongo.pid"
net:
bindIp: 0.0.0.0
port: 27017
replication:
replSetName: "configServer"
security:
authorization: enabled
keyFile: "/home/ubuntu/mongodb/bin/keyfile"
三个节点启动进程并初始化:
./mongodb/bin/mongod -f ./conf/config
在任意一个 Config Server 节点上登录 mongo server:
mongo --port 27017
rs.initiate(
{
id: "configServer",
configsvr: true,
members: [
{ _id : 0, host: "<primary ip>: 27017" },
{ _id : 1, host: "<secondary ip1>: 27017" },
{ _id : 2, host: "<secondary ip2>: 27017" }
]
}
)
rs.status()
在主节点上登录,为 CSRS 创建 root 用户:
mongo --port 27017
use admin;
db.createUser( { user: "root", pwd: "password", roles: [ { role: "root", db: "admin" } ] } );
7.4 在三个节点上部署 Shard Replica Set
分片副本集由一个主节点、一个从节点、一个仲裁节点组成。以下只演示一个分片副本集的部署,另一个同理。
vim ./mongodb/bin/conf/config
sharding:
clusterRole: shardsvr
storage:
dbPath: "/home/ubuntu/mongodb/bin/data"
journal:
enabled: true
systemLog:
destination: file
logAppend: true
path: "/home/ubuntu/mongodb/bin/log/mongo.log"
processManagement:
fork: true
pidFilePath: "/home/ubuntu/mongodb/bin/pid/mongo.pid"
net:
bindIp: 0.0.0.0
port: 27017
replication:
replSetName: "shard0"
enableMajorityReadConcern: false
security:
authorization: enabled
keyFile: "/home/ubuntu/mongodb/bin/keyfile"
三个节点启动进程并初始化:
./mongodb/bin/mongod -f ./conf/config
在任意一个分片副本集节点上登录 mongo server:
mongo --port 27017
rs.initiate(
{
id: "shard0",
members: [
{ _id : 0, host: "<primary ip>: 27017" },
{ _id : 1, host: "<secondary ip>: 27017" },
{ _id : 2, host: "<arbiter ip>: 27017" }
]
}
)
rs.status()
在主节点上登录,为分片副本集创建 root 用户:
mongo --port 27017
use admin;
db.createUser( { user: "root", pwd: "password", roles: [ { role: "root", db: "admin" } ] } );
另外一个分片副本集 id 为 shard1,同理进行部署。
7.5 在三个节点上部署 mongos
为了保证高可用,集群中的 mongos 节点至少 3 个。
vim ./mongodb/bin/conf/config
sharding:
configDB: configServer/<primary ip>: 27017, <secondary ip1>: 27017, <secondary ip2>: 27017
systemLog:
destination: file
logAppend: true
path: "/home/ubuntu/mongodb/bin/log/mongo.log"
processManagement:
fork: true
pidFilePath: "/home/ubuntu/mongodb/bin/pid/mongo.pid"
net:
bindIp: 0.0.0.0
port: 27017
security:
keyFile: "/home/ubuntu/mongodb/bin/keyfile"
三个节点启动进程并初始化:
./mongodb/bin/mongos -f ./conf/config
在任意一个 mongos 节点上登录 mongo server:
mongo -u root -p password --port 27017
sh.addShard( "shard0/<primary ip>:27017,<secondary ip>:27017,<arbiter ip>:27017" )
sh.addShard( "shard1/<primary ip>:27017,<secondary ip>:27017,<arbiter ip>:27017" )
sh.status()
启动集群时,须先启动配置服务器副本集,再启动两个分片副本集,最后启动 mongos。
第 8 章 分片集群常用命令
| 常用分片命令 | 说明 |
|---|---|
| sh.status() | 查看分片状态 |
| sh.addShard(“<ip>:<port>”) | 添加分片 |
| sh.enableSharding(“<dbname>”) | 在指定数据库上建立分片键 |
| sh.shardCollection(“namespace”, key: {_id: “hashed”}) | 在指定命名空间(<database>.<collection>)上建立分片键,“hashed” 表示建立哈希分片,1 表示建立范围分片 |
| sh.shardCollection(“namespace”, key: {_id: 1}) | |
| sh.getBalancerState () | 查看是否在分片集群中启用了平衡器,返回一个布尔值。如果平衡器在主动迁移数据,则不会检查。还可以使用 sh.status() 查看是否启用了平衡器。current -enabled 字段表示平衡器是否启用,current -running 字段表示平衡器是否正在运行 |
| sh.isBalancerRunning() | 检查平衡器是是否处于 Running 状态 |
| 常用命令 | 说明 |
|---|---|
| db.serverStatus() | 查看所有的监控状态(显示太多了,一般不用) |
| db.serverStatus().network | 查看网络流量信息 |
| db.serverStatus().opcounters | 统计增删改查次数 |
| db.serverStatus().connections | 统计连接 |

















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







