



全链路数据治理
数据建模
数据分层
ods(Operation Data Store 贴源层):直接接入源数据-业务库、埋点日志、消息队列等。
dwd(data warehouse details 数据细节层):ods层数据去空/脏数据、离群值等,业务层和数仓层的隔离层,保持和ods层相同粒度。
dwm(data warehouse middle 数据中间层):dwd层数据轻微聚合,算出统计指标,生成中间表。
dws(data warehouse service 数据服务层):dwm层数据整合汇总,形成主题数据,用于OLAP、数据分发等,通常是宽表。
ads(application data service 数据应用层):存放在ES、Redis、PG等,供数据分析和挖掘使用,通常为数据报表。
数据表分类
全量表:没有分区,数据是前一天的所有数据,每次往全量表里面写数据都会覆盖之前的数据。
问题:无法记录历史数据。
快照表:有时间分区,每个分区里面的数据都是分区时间对应的所有全量数据。
问题:分区存储了许多重复的数据。
增量表:记录每天新增数据的表,记录差集。
拉链表:一种维护历史状态以及最新状态数据的一种表。拉链表也是分区表,有些不变的数据或已经达到状态终点的数据就会把它放在分区里面,分区字段为开始时间:start_date和结束时间:end_date。
维度表:只能是事实表的一个分析角度。
实体表:是一条条客观存在的事物数据。
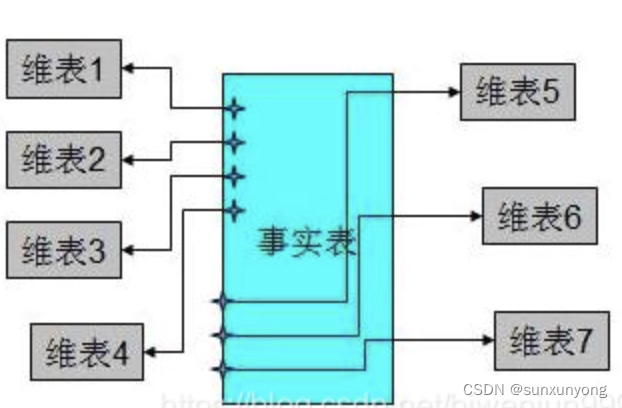
事实表:是通过各种维度和一些指标值得组合来确定一个事实的。
数仓模型
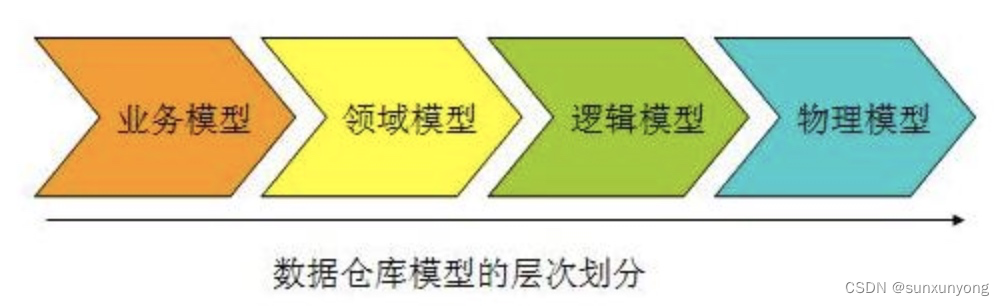
业务建模,生成业务模型,主要解决业务层面的分解和程序化。
领域建模,生成领域模型,主要是对业务模型进行抽象处理,生成领域概念模型。
逻辑建模,生成逻辑模型,主要是将领域模型的概念实体以及实体之间的关系进行数据库层次的逻辑化。
物理建模,生成物理模型,主要解决逻辑模型针对不同关系型数据库的物理化以及性能等一些具体的技术问题。
1、范式建模法(Third Normal Form,3NF)
主要解决关系型数据库得数据存储。
范式是数据库逻辑模型设计的基本理论,一个关系模型可以从第一范式到第五范式进行无损分解,这个过程也可称为规范化。在数据仓库的模型设计中目前一般采用第三范式,它有着严格的数学定义。从其表达的含义来看,一个符合第三范式的关系必须具有以下三个条件 :
每个属性值唯一,不具有多义性 ;
每个非主属性必须完全依赖于整个主键,而非主键的一部分 ;
每个非主属性不能依赖于其他关系中的属性,因为这样的话,这种属性应该归到其他关系中去。
2、维度建模法
按照事实表,维表来构建数据仓库,数据集市。
星型模式(Star-schema):针对各个维表作了大量的预处理。
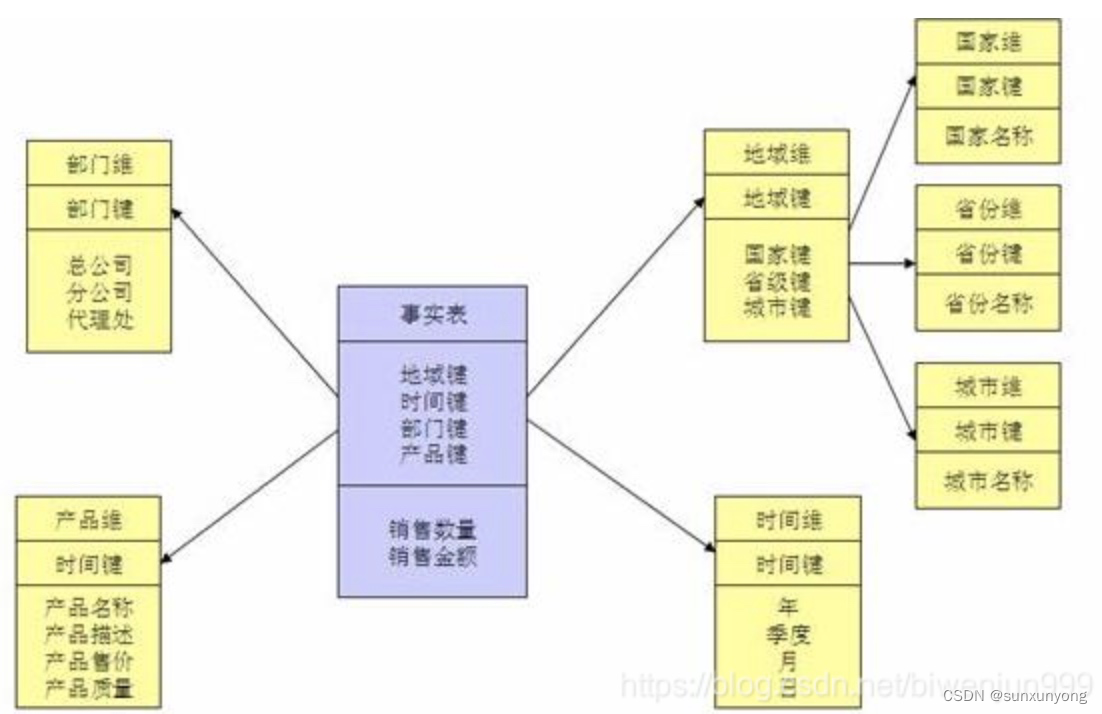
雪花模型:需要关联多层维表,性能比星型模型要低。
元数据管理
小分区治理
利用hudi的upsert特性,减少小分区。
数据血缘关系
利用atlas分析hive得表与表,字段与字段之间的血缘关系。
数据存储管理
小文件治理
hdfs 合并
hive merge
存储压缩
hdfs EC/三副本
hive snappy
冷热温数据管理
纠删码、Alluxio、presto/trino
数据时效性保障
湖仓一体,流批一体
数据安全
数据备份和恢复
冷备份、快照
权限细化管理
表、字段权限管理
kerberos开启
Kerberos是一种比普通的基于密码的认证更加安全的认证协议。使用Kerberos,即使在其他计算机上访问服务时也永远不会通过网络发送密码。
Kerberos提供了一种机制,允许用户和机器向网络标识自己,并接收对管理员配置的区域和服务的定义的、受限的访问权限。Kerberos通过认证实体的身份对其进行认证证,并且Kerberos还保护此认证数据,使其不会被外人访问、使用或篡改。
审计日志
埋点监控


















 1492
1492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









