




目录
1.语法顺序
select语句的语法格式如下。
select 字段列表
from 数据源
[ where条件表达式 ]
[ group by 分组字段
[ having条件表达式 ]
[ order by 排序字段 [ asc | desc ] ]
2.执行顺序
-
FROM 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
-
ON 对虚表VT1进行ON筛选,只有那些符合的行才会被记录在虚表VT2中。
-
JOIN 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, rug from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
-
WHERE 对虚拟表VT3进行WHERE条件过滤。只有符合的记录才会被插入到虚拟表VT4中。
-
GROUP BY 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
-
WITH CUBE or WITH ROLLUP 对表VT5进行cube或者rollup操作,产生表VT6.
-
HAVING 对虚拟表VT6应用having过滤,只有符合的记录才会被 插入到虚拟表VT7中。
-
SELECT 执行select操作,选择指定的列,插入到虚拟表VT8中。
-
DISTINCT 对VT8中的记录进行去重。产生虚拟表VT9.
-
ORDER BY 将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10.
-
TOP 取出指定行的记录,产生虚拟表VT11, 并将结果返回。
这些步骤执行时,每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入.这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只是最后一步生成的表才会返回 给调用者。
3.优化方法
1.join 方面
1.1.笛卡尔积:
在数学中,两个集合 X 和 Y 的笛卡儿积(Cartesian product),又称直积,表示为 X × Y,是其第一个对象是 X 的成员而第二个对象是 Y 的一个成员的所有可能的有序对.
假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}
1.2.join类型
cross join 是笛卡尔积 就是一张表的行数乘以另一张表的行数
inner join 只返回两张表连接列的匹配项
left join 第一张表的连接列在第二张表中没有匹配,第二张表中的值返回null
right join 第二张表的连接列在第一张表中没有匹配,第一张表中的值返回null
full join 返回两张表中的行 相当于 left join + right join
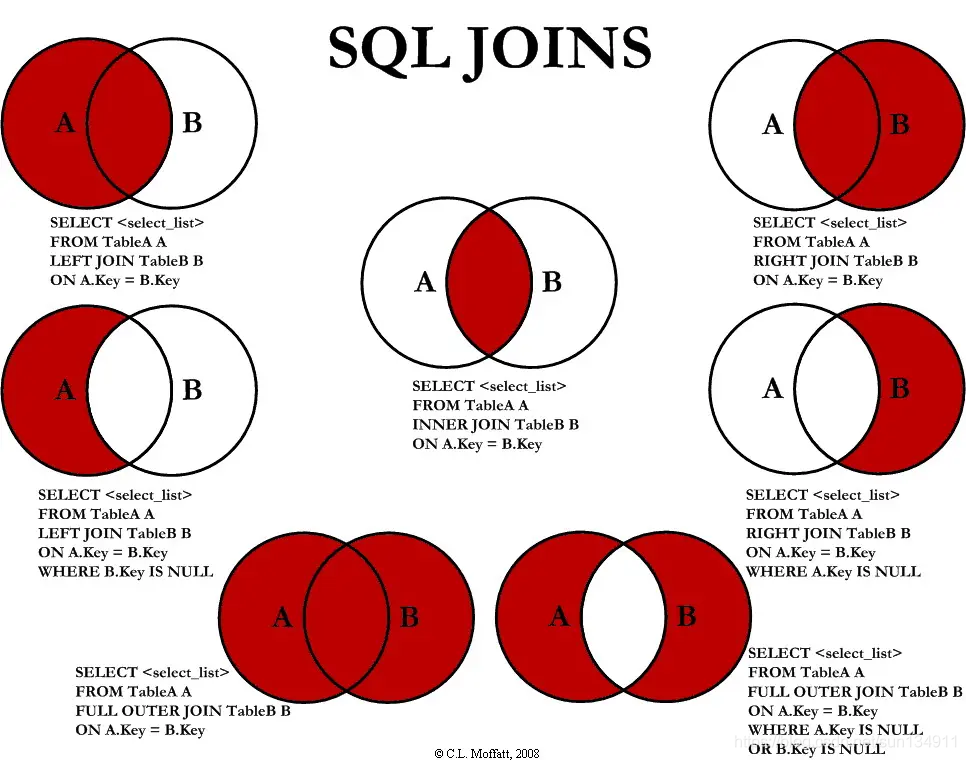
在对两张表的所有join 时,都需要构造笛卡尔积
以下语句为例子
select a.name,b.name
from T_left a Left Join T_Right b //1步骤
ON a.id = b.id //2步骤
1步骤 首先对From子句中的前两个表,执行笛卡尔积运算。运算结果 形成一个结果集合。

2步骤 按照 on中的条件 ,对上一步骤的结果集进行筛选,形成新的结果集
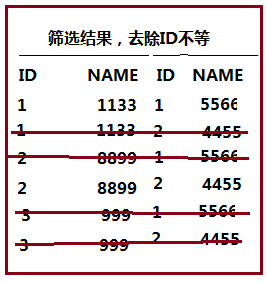
left join 为例 如果在t_left中存在为匹配到的行,则 把这些行以外部的形式添加到上一步的结果集,形成新的结果集
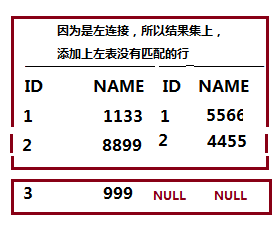
多个 join 从左到右执行
总结:先生成笛卡尔积,然后on条件过滤,如果join是inner则执行where过滤,如果是left ,rigth ,full ,就把过滤掉的主表数据在添加回来,然后执行where过滤。
如果是使用left,right,full时, on中的条件不是最终过滤,因为后面又可能会添加回来,而where才是最终过滤
2.where 方面
2.1 where的执行顺序
mysq:条件执行顺序是 从左往右,自上而下的
SQL server、orcale:条件执行顺序是从右往左,自下而上

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









