




 偏差和方差是评估模型性能的重要指标。偏差表示预测值与真实值的差距,方差则描述预测值的离散程度。理想模型应具有低偏差、低方差。过拟合时,模型对训练数据过于拟合,导致泛化能力差;欠拟合时,模型过于简单,不能捕捉数据特征。降低偏差通常通过增加模型复杂度,而减少方差则可通过增加数据量或正则化。选择模型时,应平衡偏差和方差,避免过度依赖特定测试数据集。
偏差和方差是评估模型性能的重要指标。偏差表示预测值与真实值的差距,方差则描述预测值的离散程度。理想模型应具有低偏差、低方差。过拟合时,模型对训练数据过于拟合,导致泛化能力差;欠拟合时,模型过于简单,不能捕捉数据特征。降低偏差通常通过增加模型复杂度,而减少方差则可通过增加数据量或正则化。选择模型时,应平衡偏差和方差,避免过度依赖特定测试数据集。
不同的model对应的error是不同的那么error是怎么来的呢?这里引入偏差和方差这两个概念。
概念引入
偏差(bias):描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据。
方差(variance):描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散。
红色靶心表示为实际值,蓝色点集为预测值。

低偏差,低方差:这是训练的理想模型,此时蓝色点集基本落在靶心范围内,且数据离散程度小,基本在靶心范围内。
低偏差,高方差:这是深度学习面临的最大问题,过拟合了。也就是模型太贴合训练数据了,导致其泛化(或通用)能力差,若遇到测试集,则准确度下降的厉害。
高偏差,低方差:这往往是训练的初始阶段。
高偏差,高方差:这是训练最糟糕的情况,准确度差,数据的离散程度也差。
李宏毅DL笔记P4
抽样分布
y^\hat{y}y^ 和 y∗y\asty∗真值和估测值
y^\hat{y}y^ 表示那个真正的function,而f∗f\astf∗表示这个f^\hat{f}f^ 的估测值
就好像在打靶,f^\hat{f}f^是靶的中心点,收集到一些data做training以后,你会得到一个你觉得最好的function即f∗f\astf∗,这个f∗f\astf∗落在靶上的某个位置,它跟靶中心有一段距离,这段距离就是由Bias和variance决定的。bias表示所有f∗f\astf∗的平均落靶位置和真值靶心的距离,variance表示这些f∗f\astf∗的集中程度
抽样分布的理论(概率论与数理统计)
假设独立变量为x(这里的x代表每次独立地从不同的training data里训练找到的f∗f\astf∗),那么:

总体方差是一组资料中各数值与其算术平均数离差平方和的平均数。
用样本均值x‾\overline{x}x 估测总体期望u
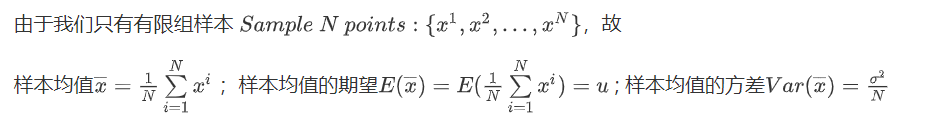
补充数学知识:算术平均是来自样本的,是近似的;数学期望是母体的,是精确的。
样本均值 x‾\overline{x}x 的期望是总体期望u也就是说是按概率对称地分布在总体期望u的两侧的;而 x‾\overline{x}x 分布的密集程度取决于N,即数据量的大小,如果N比较大, x‾\overline{x}x 就会比较集中,如果N比较小, x‾\overline{x}x 就会以为中心分散开来。综上,样本均值x‾\overline{x}x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1658
1658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









