




预处理数
1. 标准化:去均值,方差规模化
Standardization标准化:将特征数据的分布调整成标准正太分布,也叫高斯分布,也就是使得数据的均值维0,方差为1.
标准化的原因在于如果有些特征的方差过大,则会主导目标函数从而使参数估计器无法正确地去学习其他特征。
标准化的过程为两步:去均值的中心化(均值变为0);方差的规模化(方差变为1)。
在sklearn.preprocessing中提供了一个scale的方法,可以实现以上功能。
preprocessing这个模块还提供了一个实用类StandarScaler,它可以在训练数据集上做了标准转换操作之后,把相同的转换应用到测试训练集中。
这是相当好的一个功能。可以对训练数据,测试数据应用相同的转换,以后有新的数据进来也可以直接调用,不用再重新把数据放在一起再计算一次了。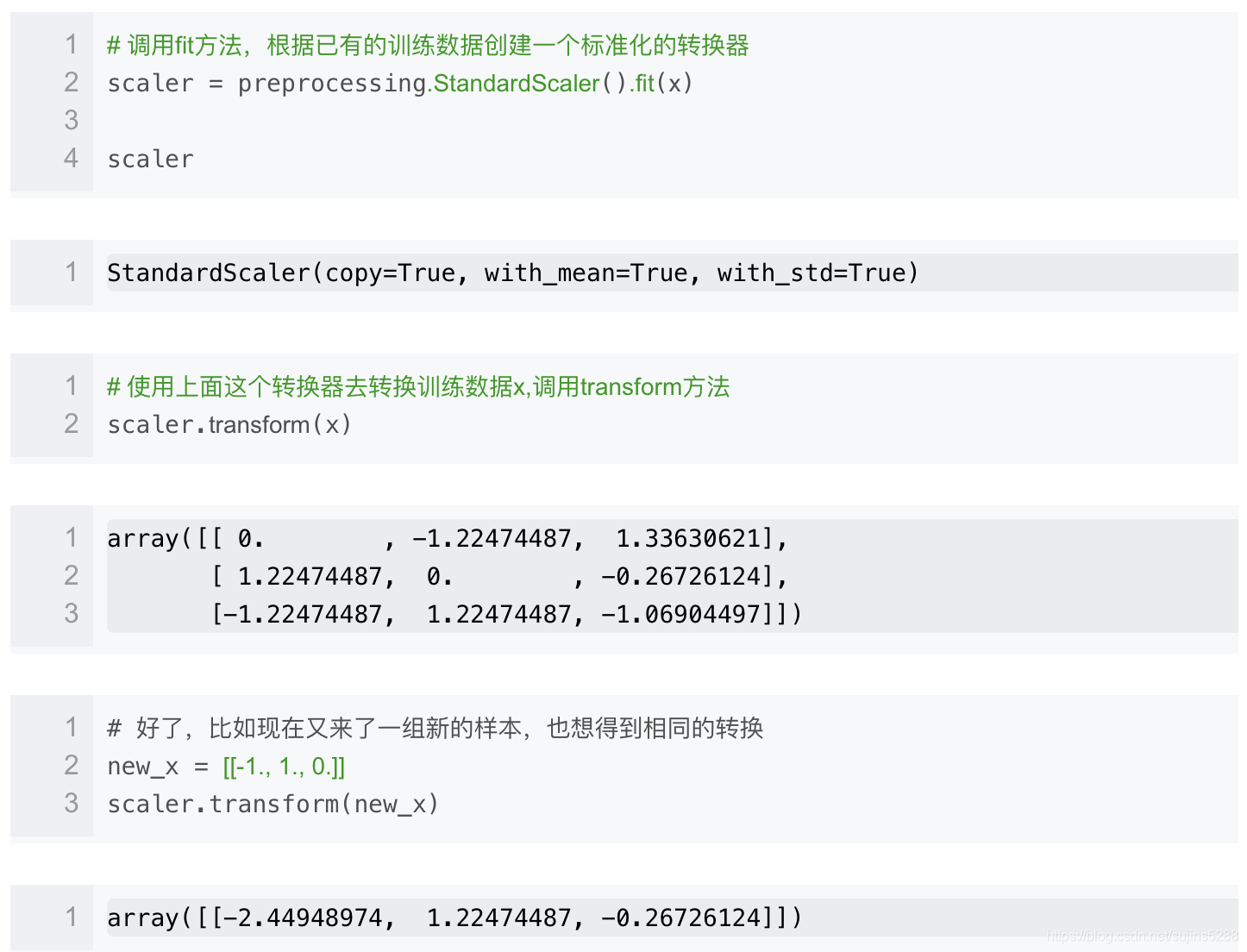
恩,完美。
另外,StandardScaler()中可以传入两个参数:with_mean,with_std.这两个都是布尔型的参数,默认情况下都是true,但也可以自定义成false.即不要均值中心化或者不要方差规模化为1.
1.1 规模化特征到一定的范围内
也就是使得特征的分布是在一个给定最小值和最大值的范围内的。一般情况下是在[0,1]之间,或者是特征中绝对值最大的那个数为1,其他数以此维标准分布在[[-1,1]之间
以上两者分别可以通过MinMaxScaler 或者 MaxAbsScaler方法来实现。
之所以需要将特征规模化到一定的[0,1]范围内,是为了对付那些标准差相当小的特征并且保留下稀疏数据中的0值。
MinMaxScaler
在MinMaxScaler中是给定了一个明确的最大值与最小值。它的计算公式如下:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std / (max - min) + min
以下这个例子是将数据规与[0,1]之间,每个特征中的最小值变成了0,最大值变成了1,请看: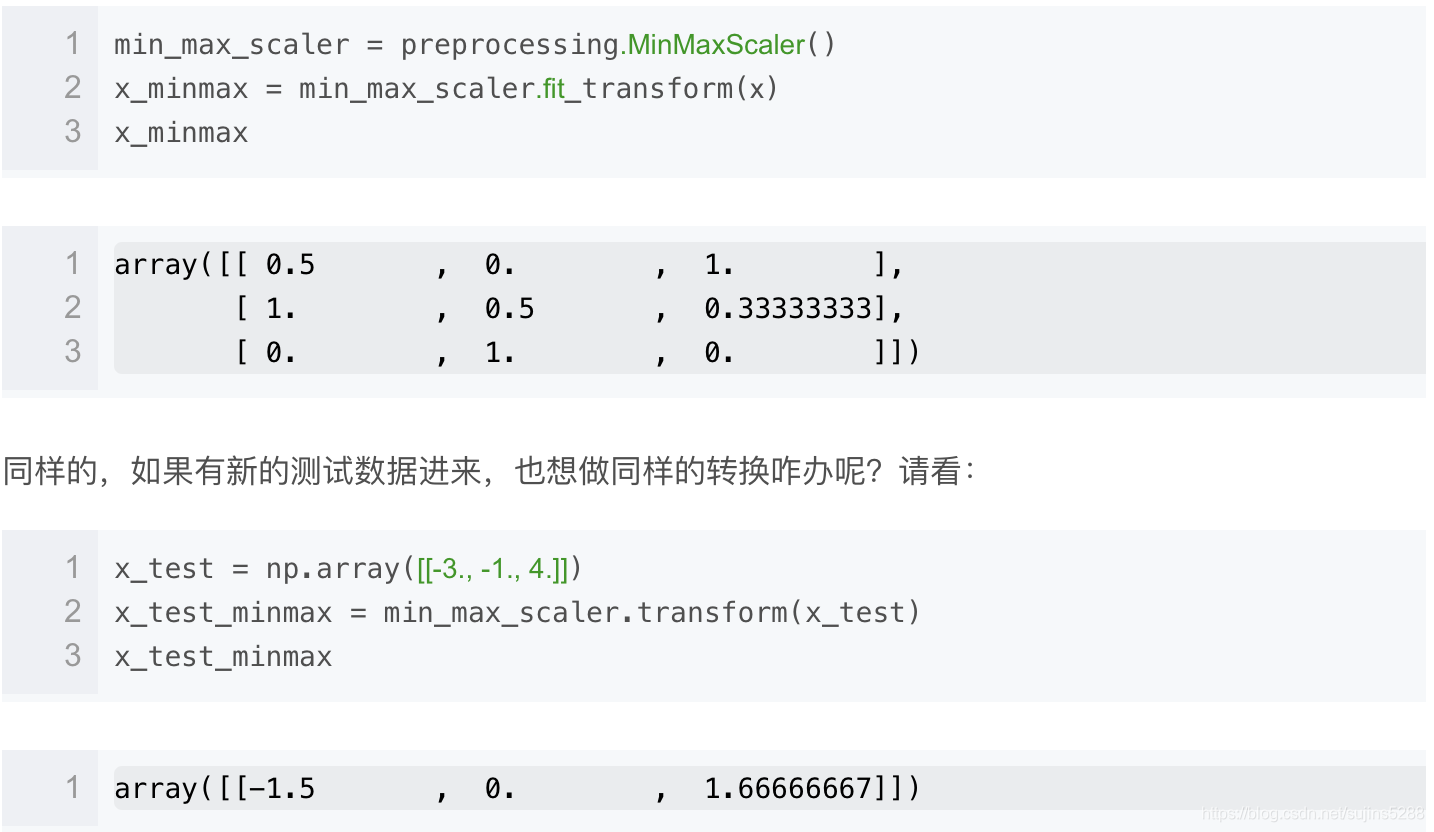
MaxAbsScaler
原理与上面的很像,只是数据会被规模化到[-1,1]之间。也就是特征中,所有数据都会除以最大值。这个方法对那些已经中心化均值维0或者稀疏的数据有意义。
来个小例子感受一下:

1.2 规模化稀疏数据
如果对稀疏数据进行去均值的中心化就会破坏稀疏的数据结构。虽然如此,我们也可以找到方法去对稀疏的输入数据进行转换,特别是那些特征之间的数据规模不一样的数据。
MaxAbsScaler 和 maxabs_scale这两个方法是专门为稀疏数据的规模化所设计的。
1.3 规模化有异常值的数据
如果你的数据有许多异常值,那么使用数据的均值与方差去做标准化就不行了。
在这里,你可以使用robust_scale 和 RobustScaler这两个方法。它会根据中位数或者四分位数去中心化数据。
2 正则化Normalization
正则化是将样本在向量空间模型上的一个转换,经常被使用在分类与聚类中。
函数normalize 提供了一个快速有简单的方式在一个单向量上来实现这正则化的功能。正则化有l1,l2等,这些都可以用上: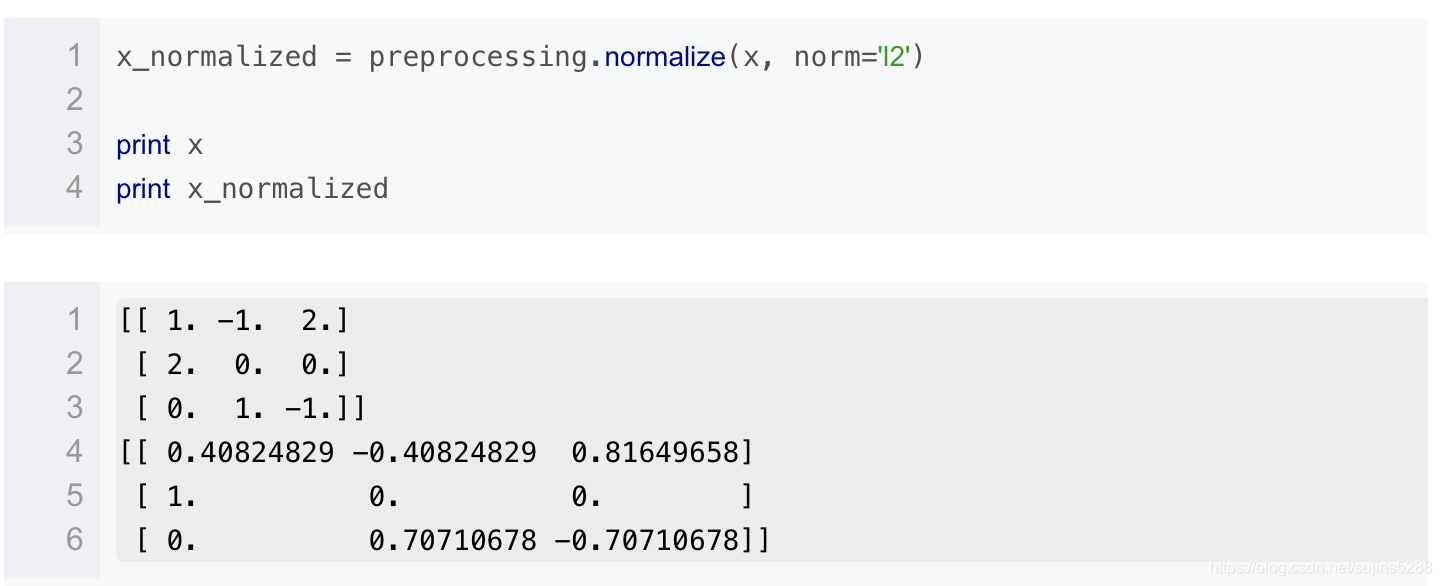
preprocessing这个模块还提供了一个实用类Normalizer,实用transform方法同样也可以对新的数据进行同样的转换
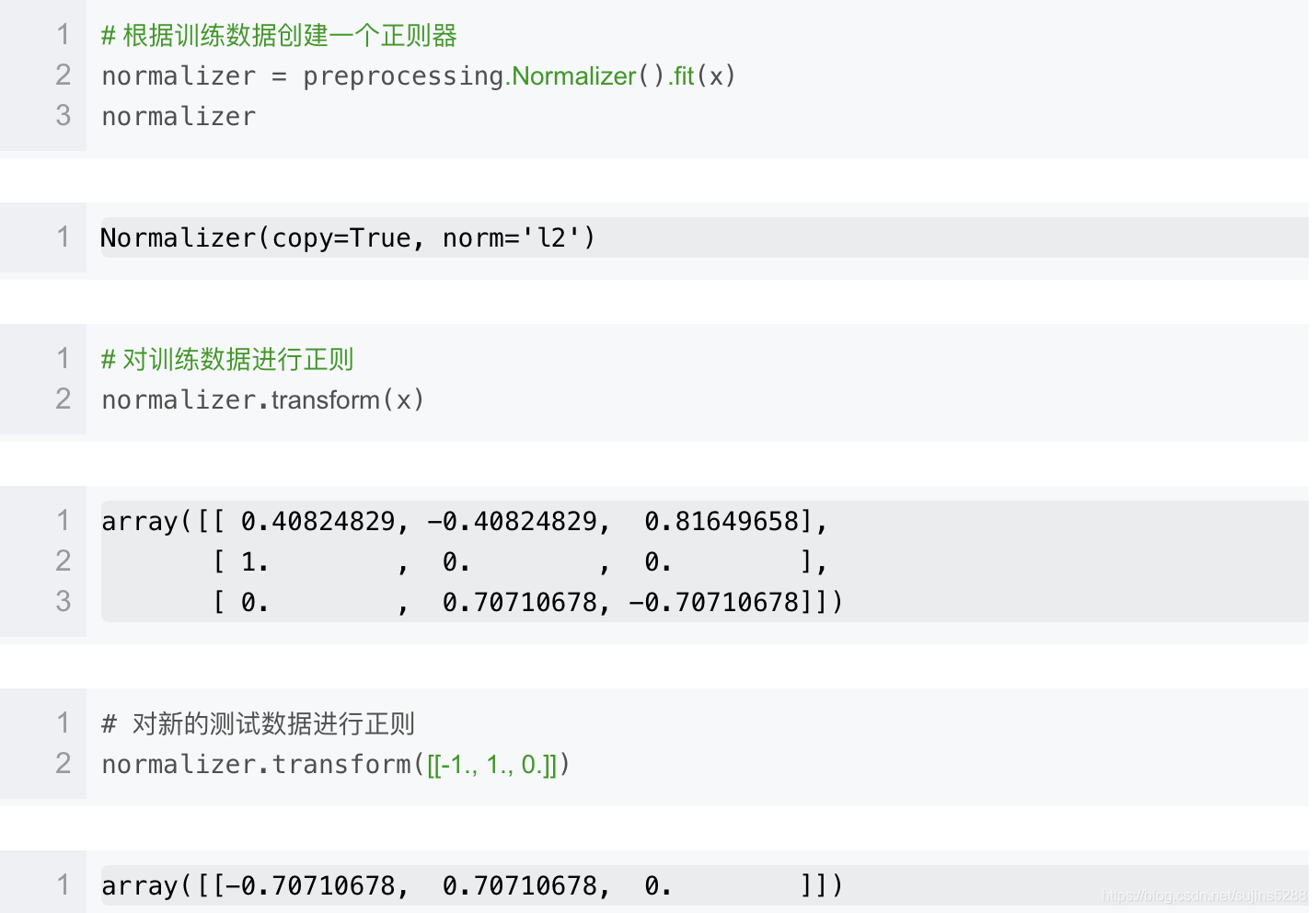
normalize和Normalizer都既可以用在密集数组也可以用在稀疏矩阵(scipy.sparse)中
对于稀疏的输入数据,它会被转变成维亚索的稀疏行表征(具体请见scipy.sparse.csr_matrix)
3 二值化–特征的二值化
特征的二值化是指将数值型的特征数据转换成布尔类型的值。可以使用实用类Binarizer。
from sklearn import preprocessing
import numpy as np
# 创建一组特征数据,每一行表示一个样本,每一列表示一个特征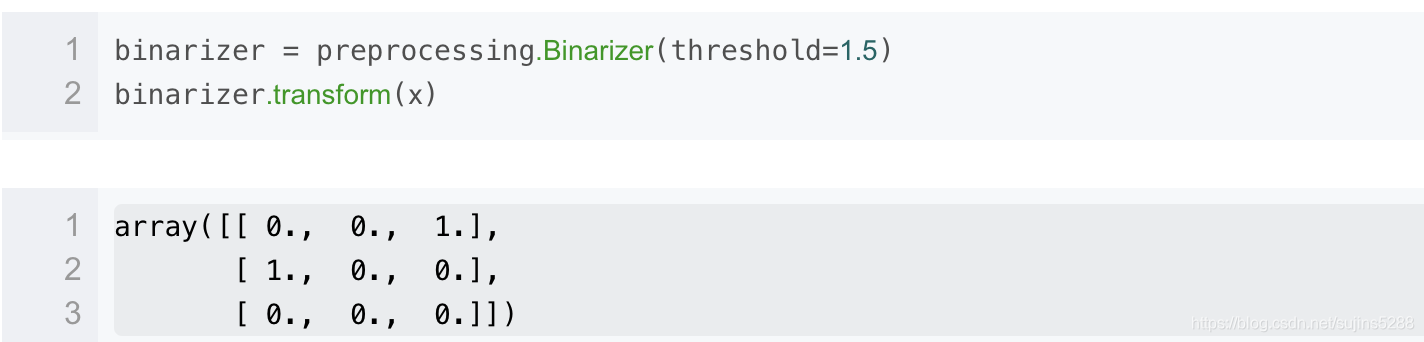
binarize and Binarizer都可以用在密集向量和稀疏矩阵上。
4 为类别特征编码
我们知道特征可能是连续型的也可能是类别型的变量,比如说:
[“male”, “female”], [“from Europe”, “from US”, “from Asia”], [“uses Firefox”, “uses Chrome”, “uses Safari”, “uses Internet Explorer”].
这些类别特征无法直接进入模型,它们需要被转换成整数来表征,比如:
[“male”, “from US”, “uses Internet Explorer”] could be expressed as [0, 1, 3] while [“female”, “from Asia”, “uses Chrome”] would be [1, 2, 1].
然而上面这种表征的方式仍然不能直接为scikit-learn的模型所用,因为模型会把它们当成序列型的连续变量。
要想使得类别型的变量能最终被模型直接使用,可以使用one-of-k编码或者one-hot编码。这些都可以通过OneHotEncoder实现,它可以将有n种值的一个特征变成n个二元的特征。
特征1中有(0,1)两个值,特征2中有(0,1,2)3个值,特征3中有(0,1,2,3)4个值,所以编码之后总共有9个二元特征。
但是呢,也会存在这样的情况,某些特征中可能对一些值有缺失,比如明明有男女两个性别,样本数据中都是男性,这样就会默认被判别为我只有一类值。这个时候我们可以向OneHotEncoder传如参数n_values,用来指明每个特征中的值的总个数。如下:

5 弥补缺失数据
在scikit-learn的模型中都是假设输入的数据是数值型的,并且都是有意义的,如果有缺失数据是通过NAN,或者空值表示的话,就无法识别与计算了。
要弥补缺失值,可以使用均值,中位数,众数等等。Imputer这个类可以实现。请看:
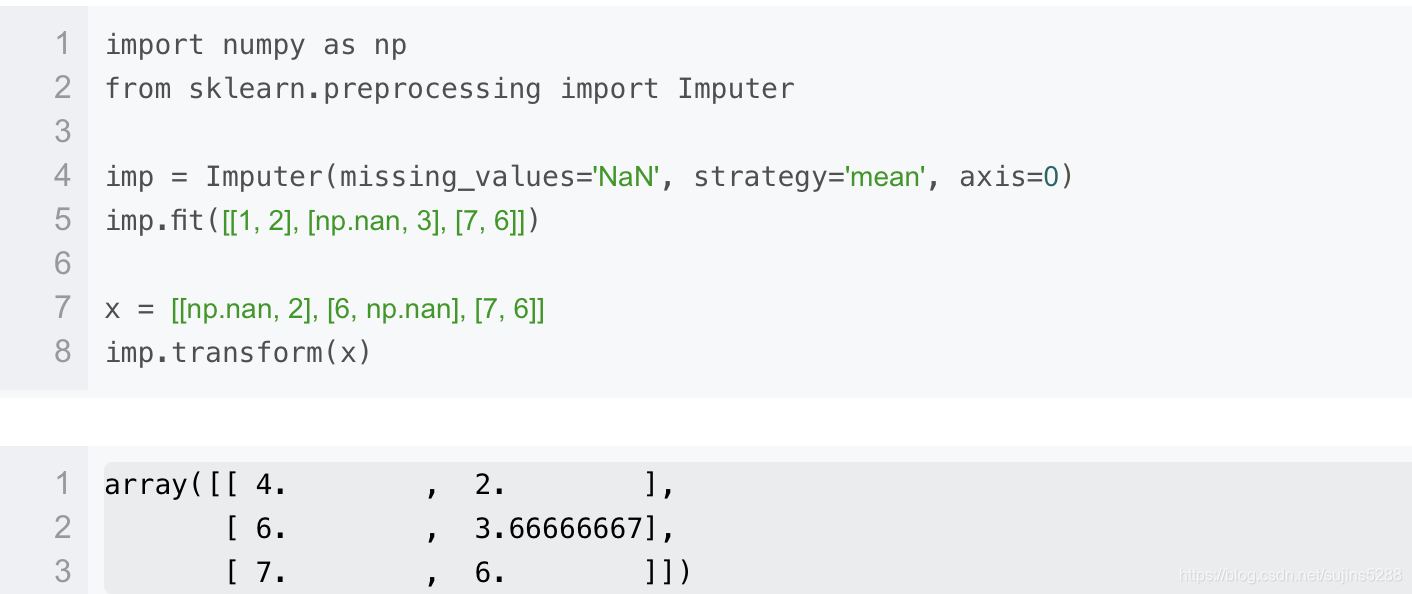
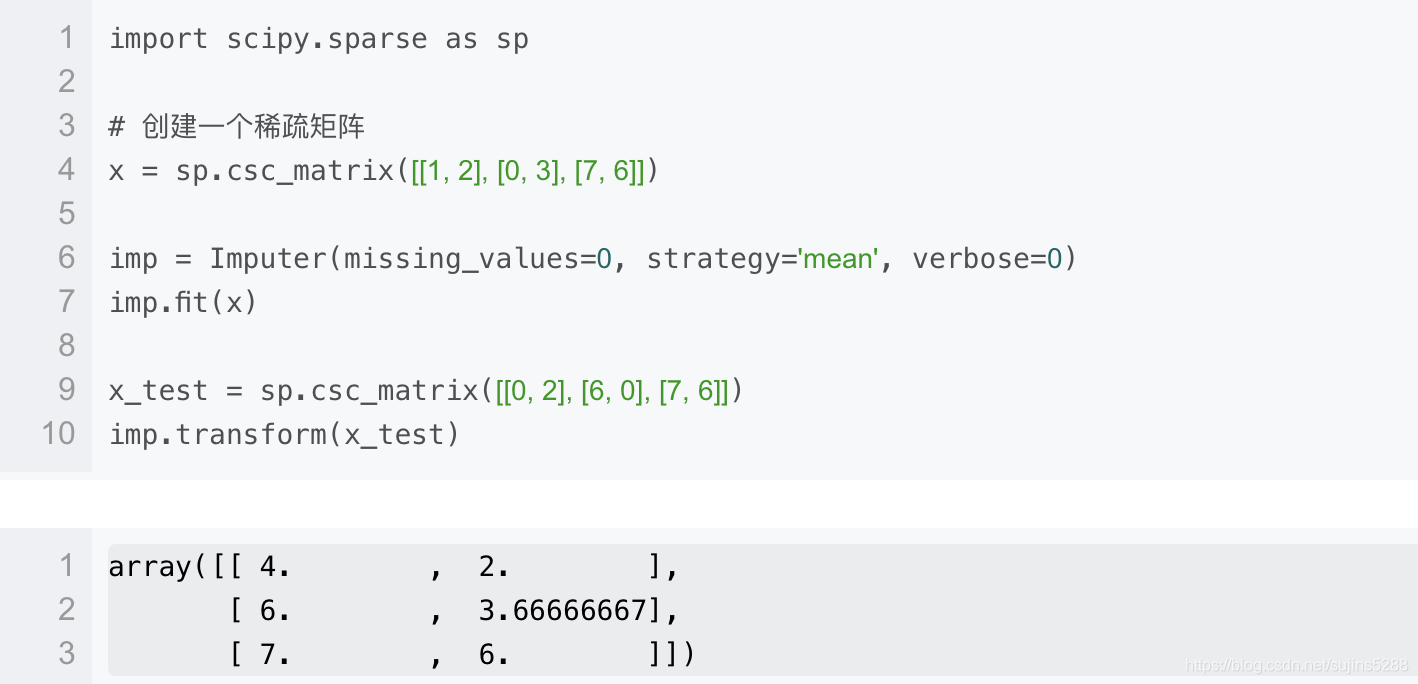
Imputer类同样也可以支持稀疏矩阵,以下例子将0作为了缺失值,为其补上均值
6 创建多项式特征
有的时候线性的特征并不能做出美的模型,于是我们会去尝试非线性。非线性是建立在将特征进行多项式地展开上的。
比如将两个特征 (X_1, X_2),它的平方展开式便转换成5个特征(1, X_1, X_2, X_1^2, X_1X_2, X_2^2). 代码案例如下:
看,变成了3*6的特征矩阵,里面有5个特征,加上第一列的是Bias.
也可以自定义选择只要保留特征相乘的项。
即将 (X_1, X_2, X_3) 转换成 (1, X_1, X_2, X_3, X_1X_2, X_1X_3, X_2X_3, X_1X_2X_3).

7 自定义特征的转换函数
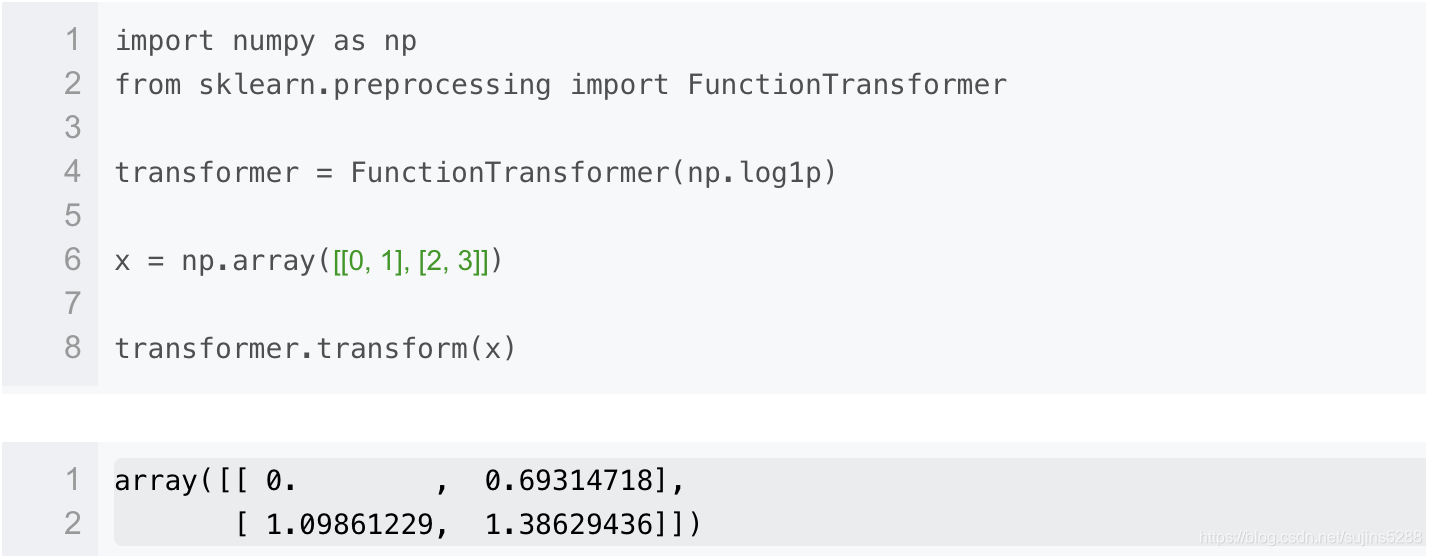
通俗的讲,就是把原始的特征放进一个函数中做转换,这个函数出来的值作为新的特征。
比如说将特征数据做log转换,做倒数转换等等。
FunctionTransformer 可以实现这个功能
将上面讲到的7个预处理的方法综合起来。
当我们拿到一批原始的数据
首先要明确有多少特征,哪些是连续的,哪些是类别的。
检查有没有缺失值,对确实的特征选择恰当方式进行弥补,使数据完整。
对连续的数值型特征进行标准化,使得均值为0,方差为1。
对类别型的特征进行one-hot编码。
将需要转换成类别型数据的连续型数据进行二值化。
为防止过拟合或者其他原因,选择是否要将数据进行正则化。
在对数据进行初探之后发现效果不佳,可以尝试使用多项式方法,寻找非线性的关系。
根据实际问题分析是否需要对特征进行相应的函数转换。
恩,准备好美美的数据将为我们寻找美美的模型如虎添翼。
官方文档链接http://scikit-learn.org/stable/modules/preprocessing.html#preprocessing
--------------------------------------------------------------------------------------
原文地址:原文:https://blog.youkuaiyun.com/sinat_33761963/article/details/53433799

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









