




Regression:Case Study
应用:Stock Market Forecast(股票市场预测)、Self-driving Car(自动驾驶汽车)、Recommendation(推荐系统)。
拿到一个案例后,分三步骤走:
Step 1:Model
A set of function:y = b+wx
Linear model:y = b+∑ w_i x_i
x is an attribute of input. x feature;w_i is weight;b is bias.
Step 2:Goodness of function
用Loss function检测函数好坏。线性函数的Loss function可写成 L(f) = L(w,b),输入的是一个函数,输出估测的误差。
1. Pick the “best” function
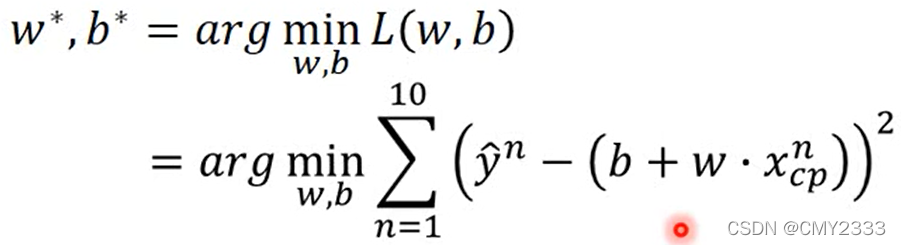
上图解释:arg是argument(参数)缩写,arg min指当目标函数最小时,参数的值。
2. Gradient Descent(梯度下降)
不仅是Linear function,只要函数可微分,就可以用Gradient Descent处理,帮助找到函数中更好的参数值。
Gradient Descent内容:
① 当函数只有一个参数w时:
a) 随便取一个初始值w0
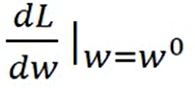
b) 求w0点的切线斜率,若斜率为neg(负数),w0需往增大方向移动若干得到w1,若斜率为pos(正数),则w0往减小方向移动得到w1。
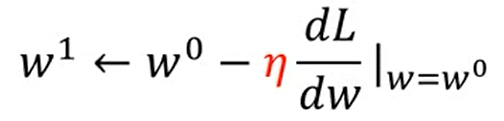
c) 重复迭代以上行为,直到移动到wt的斜率为0为止。
② 当函数有两个参数w、b时:
a) 随机选取初始值w0、b0, 对w0、bo求导并赋值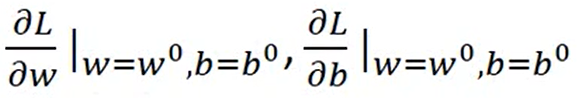
b) 根据求导正负移动w、b的值
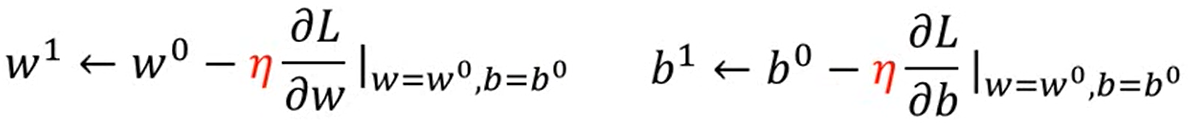
c) 重复迭代以上行为,直到找到使Loss值最小的参数值wt、bt
ps:在Gradient Descent中wt对应的可能是local optimal(局部最优解),而不是global optimal(全局最优解),不过在Linear regression不存在这种问题,因为Loss function 是convex(凸函数),convex意味着没有local optimal,找到的wt都是global optimal。
将Model复杂化:
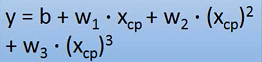
后面还可以加wx四次方,wx五次方,幂次越高,Model越复杂,但效果不一定会更好,还可能会出现overfitting情况。

















 2546
2546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









