




 本文探讨了C++中的多态性,包括编译时和运行时多态,以及如何通过虚函数和抽象类实现多态。多态性允许不同对象对同一消息作出不同响应,如在买票示例中,不同角色有不同的票价。通过虚函数表,C++在运行时实现动态绑定,使得程序可以根据对象的实际类型调用相应的方法。
本文探讨了C++中的多态性,包括编译时和运行时多态,以及如何通过虚函数和抽象类实现多态。多态性允许不同对象对同一消息作出不同响应,如在买票示例中,不同角色有不同的票价。通过虚函数表,C++在运行时实现动态绑定,使得程序可以根据对象的实际类型调用相应的方法。
1.初探多态性
在面向对象方法中,所谓多态性就是不同对象收到相同消息,产生不同的行为。在C++程序设计中,多态性是指用一个名字定义不同的函数,这些函数执行不同但又类似的操作,这样就可以用同一个函数名调用不同内容的函数。换言之,可以用同样的接口访问功能不同的函数,从而实现“一个接口,多种方法”。
事实上,在程序设计中经常会使用到多态性。最简单的例子就是运算符了,例如我们使用运算符+,就可以实现整型数、浮点数、双精度类型之间的加法运算,这三种类型的加法操作其实是互不相同的,是由不同内容的函数实现的。这个例子就是使用了多态的特征。
在C++中,多态性的实现和联编(也称绑定)这一概念有关。一个源程序经过编译、链接,成为可执行文件的过程是把可执行代码联编(或称装配)在一起的过程。其中在运行之前就完成的联编成为静态联编(前期联编);而在程序运行之时才完成的联编叫动态联编(后期联编)。
静态联编支持的多态性称为编译时多态性(静态多态性)。在C++中,编译时多态性是通过函数重载和模板实现的。利用函数重载机制,在调用同名函数时,编译系统会根据实参的具体情况确定索要调用的是哪个函数。
动态联编所支持的多态性称为运行时多态(动态多态)。在C++中,运行时多态性是通过虚函数来实现的。
再举一个通俗易懂的例子:比如买票这个行为,普通人买是全价;学生买是半价票等。
2.多态的定义和实现
2.1 多态定义构成条件
多态是在不同继承关系的类对象,去调用同一函数,产生了不同的行为。比如Student继承了Person.Person买票就是全价,而Student买票就是半价。
那么在继承中要构成多态还需要两个条件:
a. 调用函数的对象必须是指针或者引用。
b. 被调用的函数必须是虚函数,且完成了虚函数的重写。
什么是虚函数?
虚函数:在类的成员函数前加virtual关键字。
class Person
{
public:
virtual void BuyTicket()
{
cout << "买票-全价" << endl;
}
};
什么是虚函数的重写?
虚函数的重写:派生类中有一个跟基类的完全相同的虚函数,我们就称子类的虚函数重写了基类的虚函数。“完全相同”是指:函数名、参数、返回值都相同。另外,虚函数的重写也叫做虚函数的覆盖。
示例代码:
#include <iostream>
#include <stdlib.h>
using namespace std;
class Person
{
public:
virtual void BuyTicket()
{
cout << "买票-全价" << endl;
}
};
class Student : public Person
{
public:
virtual void BuyTicket(){
cout << "买票-半价" << endl;
}
};
void Func(Person& p)
{
p.BuyTicket();
}
int main()
{
Person ps;
Student st;
Func(ps);
Func(st);
system("pause");
return 0;
}
不规范的重写行为
在派生类中重写的成员函数可以不加virtual关键字,也是构成重写,因为继承后基类的虚函数被继承下来,在派生类中依旧保持虚函数的属性,我们只是重写了它。这是非常不规范的,在平时尽量不要这样使用。
注意:若子类中的函数有virtual修饰,而父类中没有,则会构成函数隐藏。
基类中的析构函数如果是虚函数,那么派生类的析构函数就重写了基类的析构函数。这里他们的函数名不相同,看起来违背了重写的规则,其实不然,这里可以理解为编译器对析构函数的名称做了特殊处理,编译后析构函数的名称统一处理成destructor,这也说明基类的析构函数最好写成虚函数。
这里贴一个链接,专门解释了为什么基类的析构函数最好写成虚函数:https://blog.youkuaiyun.com/komtao520/article/details/82424468
接口继承与实现继承
普通函数的继承是一种实现继承,派生类继承了基类函数,可以使用函数,继承的是函数的实现。虚函数的继承是一种接口继承,派生类继承的是基类虚函数的接口,目的是为了重写,达成多态,继承的是接口。所以,如果不实现多态,不要把函数定义成虚函数。
3. 抽象类
在虚函数的后面写上 = 0,则这个函数为纯虚函数。包含纯虚函数的类叫做抽象类(也叫接口类),抽象类不能实例化出对象。派生类继承后也不能实例化出对象。只有重写纯虚函数,派生类才能实例化出对象。纯虚函数规范了派生类必须重写,另外纯虚函数更体现了接口继承。
示例代码:
#include<iostream>
#include <stdlib.h>
using namespace std;
class Car
{
public:
//纯虚函数
virtual void Drive() = 0;
};
class Benz :public Car
{
public:
virtual void Drive(){
cout << "Benz-舒适" << endl;
}
};
class BMW :public Car
{
public:
virtual void Drive(){
cout << "BMW-操控" << endl;
}
};
void Test()
{
Car* pBenz = new Benz;
pBenz->Drive();
Car* pBMW = new BMW;
pBMW->Drive();
}
int main()
{
Test();
system("pause");
return 0;
}
结果: Benz-舒适
BMW-操控
4. 多态的原理
4.1 虚函数表
//计算sizeof(b)为多少???
#include<iostream>
#include <stdlib.h>
using namespace std;
class Base
{
public:
virtual void Fun1(){
cout << "Func1()" << endl;
}
private:
int _b = 1;
};
int main()
{
Base b;
cout << "sizeof(b):" << sizeof(b) << endl;
system("pause");
return 0;
}
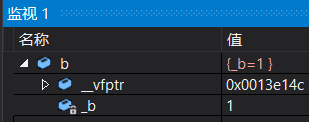
通过测试我们发现sizeof(Base)大小为8字节。除了_b成员,还多了一个_vfptr放在对象的前面(注意有些平台可能会放在对象的后面,这个跟平台有关),对象中的这个指针我们称它为虚函数表指针。一个含有虚函数的类中至少都有一个虚函数表指针,因为虚函数的地址要被放到虚函数表(虚表)中。
示例代码:
//1.增加一个派生类Derive去继承Base
//2.Derive中重写Func1
//3.Base再增加一个虚函数Fun2和一个普通函数Fun3
class Base
{
virtual void Func1()
{
cout << "Base::Func1()" << endl;
}
virtual void Func2(){
cout << "Base::Func2()" << endl;
}
void Func3(){
cout << "Base::Func3()" << endl;
}
private:
int _b = 1;
};
class Derive : public Base
{
public:
virtual void Func1(){
cout << "Derive::Func1()" << endl;
}
private:
int _d = 2;
};
int main()
{
Base b;
Derive d;
system("pause");
return 0;
}
这里我们打开监视窗口,不难发现以下几点问题:


a. 派生类对象也有一个虚表指针,d对象由两部分构成,一部分是父类继承下来的成员,另一部分是自己的成员。
b.基类b对象和派生类d对象虚表是不一样的,这里我们发现Func1完成了重写,所以d的虚表中存的是重写的Derive::Func1,所以虚函数的重写也叫覆盖。
c.另外Func2继承下来后是虚函数,所以放进了虚表,Func3也继承下来了,但不是虚函数,所以不放在虚表中。
d.虚函数表本质是一个存虚函数指针的指针数组,这个数组最后面放了一个nullptr。
总结:派生类的虚表生成:
(1)先将基类中的虚表内容拷贝一份到派生类虚表中;
(2)如果派生类重写了基类中的某个虚函数,用派生类自己的虚函数覆盖虚表中基类的虚函数;
(3)派生类自己新增加的虚函数按其在派生类中的声明次序增加到派生类的虚表的最后。
多态实现的原理:
分析了这么多,我们依旧拿上边“买票”为例,Func函数传Person调用的Person::BuyTicket,传Student调用的是Student::BuyTicket.
class Person
{
public:
virtual void BuyTicket()
{
cout << "买票-全价" << endl;
}
};
class Student : public Person
{
public:
virtual void BuyTicket(){
cout << "买票-半价" << endl;
}
};
void Func(Person& p)
{
p.BuyTicket();
}
int main()
{
Person Mike;
Func(Mike);
Student John;
Func(John);
system("pause");
return 0;
}
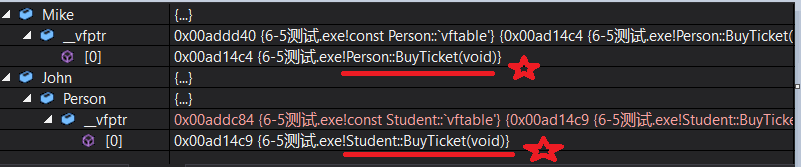
这样就实现了不同对象去完成同一行为时,展现出不同的形态。
动态绑定与静态绑定:
a. 静态绑定又称为前期绑定(早绑定),在程序编译期间确定了程序的行为,也称为静态多态 ,例如:函数重载。
b. 动态绑定又称为后期绑定(晚绑定),是在程序运行期间,根据具体拿到的类型确定程序的具体行为,调用具体的函数,也称为动态多态。
下边给大家贴了一个链接,这个博文更好地讲解了多态,希望对大家有所帮助。
https://blog.youkuaiyun.com/u012630961/article/details/81226351

















 538
538









 到【灌水乐园】发言
到【灌水乐园】发言







