




 本文提出O-VITON,一种新型的基于图像的虚拟试穿方法,无需配对数据,仅需单张训练图像,支持多服装组合。通过在线优化提升细节处理,对复杂服装和姿势变化有更高精度。实验在大规模服装数据集上对比现有方法,显示优越性能。
本文提出O-VITON,一种新型的基于图像的虚拟试穿方法,无需配对数据,仅需单张训练图像,支持多服装组合。通过在线优化提升细节处理,对复杂服装和姿势变化有更高精度。实验在大规模服装数据集上对比现有方法,显示优越性能。
Image Based Virtual Try-on Network from Unpaired Data
Image-Based-Virtual-Try-on-Network-from-Unpaired-Data

摘要
本文提出了一种新的基于图像的虚拟试穿方法(Outfit-VITON),该方法可帮助可视化从各种参考图像中选择的衣物组成如何在查询图像中的人身上形成凝聚力的衣服。我们的算法具有两个独特的属性。首先,它不昂贵,因为它只需要一大套穿着各种服装的人的(独立的)(真实的和分类的)图像(没有真实的3D信息)。训练阶段只需要单个图像,而无需手动创建图像对,其中一个图像显示穿着特定服装的人,另一个图像仅显示相同类别的服装。其次,它可以合成构成一个连贯服装的多件服装的图像。 它可以控制最终服装中所呈现服装的类型。经过训练后,我们的方法便可以从穿着衣服的人体模型的多个图像中合成出具有凝聚力的服装,同时使服装适合查询人员的身体形状和姿势。在线优化步骤负责处理精细的细节,例如复杂的纹理和徽标。 与现有的最新方法相比,对包含较大形状和样式变化的图像数据集进行定量和定性评估显示出更高的准确性,尤其是在处理高度详细的服装时。
介绍
在美国,在线服装销售在服装和配饰销售总额中所占的份额以比其他任何电子商务部门更快的速度增长。在线服装购物可让您在家中舒适自在地购物,提供多种选择的商品以及使用最新产品,从而为购物提供了便利。但是,在线购物无法进行物理试穿,从而限制了客户对服装实际外观的理解。这一关键局限性促进了虚拟试衣间的发展,在虚拟试衣间中,将综合生成穿着所选服装的顾客的图像,以帮助比较和选择最理想的外观。
3D方法
用于合成穿着者的逼真的图像的常规方法依赖于从深度相机或多个2D图像构建的详细3D模型。3D模型可以在几何和物理约束下实现逼真的服装模拟,并可以精确控制观看方向,照明,姿势和纹理。然而,它们在数据捕获、注释、计算以及在某些情况下对专用设备(如3D传感器)的需要方面产生了巨大的成本。这些巨大的成本阻碍了向数百万客户和成衣的扩展。
条件图像生成方法
最近,更经济的解决方案建议将虚拟试戴问题公式化为有条件的图像生成问题。这些方法从两个输入图像中生成人们穿着所选服装的逼真的图像:一个显示人物,另一个被称为店内服装,仅显示服装。根据使用的训练数据,这些方法可以分为两个主要类别:(1)配对数据,单服装方法,该方法使用一组训练成对的图像对来描述多幅图像中的同一件衣服。例如,有和没有人穿衣服的图像对(例如[10、30]),或以相同的人体模型在两个不同姿势下呈现特定服装的图像对。(2)将训练数据中的整个服装(由多件服装组成)视为一个实体的单数据,多服装方法(例如[25])。两种方法都有两个主要局限性:首先,它们不允许客户选择多种服装(例如衬衫,裙子,夹克和帽子),然后将它们组合在一起以适合客户的身体。其次,他们接受了几乎难以大规模收集的数据培训。在成对数据,单件服装图像的情况下,很难为每种可能的服装收集几对。对于单数据,多服装图像,很难收集到足以覆盖所有可能服装组合的实例。
新奇
在本文中,我们提出了一种新的基于图像的虚拟试戴法,该方法是:1)提供廉价的数据收集和训练过程,其中包括仅使用单个2D训练图像,该图像比成对的训练图像或3D数据更容易进行大规模收集 。2)通过合成构成一个整体的服装的多件服装的图像,提供高级的虚拟试穿体验(图2),并使用户能够控制最终服装中渲染的服装的类型。3)引入了用于虚拟试穿的在线优化功能,该功能可以准确地综合精细的服装功能,例如纹理,徽标和刺绣。我们对包含较大形状和样式变化的图像集评估提出的方法。 定量和定性结果均表明我们的方法比以前的方法取得了更好的结果。
相关工作
生成对抗网络
生成对抗网络(GAN)[7,27]是生成模型,经过训练可以合成与原始训练数据没有区别的真实样本。GAN在图像生成[24,17]和操纵[16]中已显示出令人鼓舞的结果。但是,最初的GAN公式缺乏控制输出的有效机制。
有条件的GAN(cGAN)[21]试图通过在生成的示例上添加约束来解决此问题。GAN中使用的约束可以采用类别标签[1],文本[36],姿势[19]和属性[29]的形式(例如,张开/闭合,胡须/无胡须,眼镜/无眼镜,性别)。Isola等 [13]提出了一种称为pix2pix的图像到图像转换网络,该网络将图像从一个域映射到另一个域(例如,草图到照片,分割到照片)。这种跨域关系已在图像生成中显示出令人鼓舞的结果。Wang等人的pix2pixHD [31]从单个分割图生成多个高清输出。它通过添加自动编码器来实现,该编码器学习可限制GAN并支持更高级别的本地控制的特征图。最近,[23]建议使用空间自适应的归一化层,该层在图像级别而不是局部地对纹理进行编码。另外,已经使用GAN证明了图像的组成[18,35],其中使用几何变换将前景图像的内容传输到背景图像,从而生成具有自然外观的图像。最近已经证明在测试阶段可以对GAN进行微调[34],用于面部重现。
虚拟试穿
深度神经网络的最新进展激发了仅使用2D图像而不使用任何3D信息的方法。例如,VITON [10]方法使用形状上下文[2]来确定如何通过构图阶段然后进行几何变形来使服装图像变形以适合查询人的几何形状。CP-VITON [30]使用卷积几何匹配器[26]确定几何变形函数。WUTON [14]是这项工作的扩展,它使用对抗性损失进行更自然,更详细的合成,而无需合成阶段。PIVTONS [4]扩展了[10]用于姿势不变的服装,而MG-VTON [5]扩展了用于多姿势虚拟试穿。原始VITON [10]的所有不同变体都需要一组成对的训练图像,即在有或没有人体模型的情况下都可以捕获每件服装。因为获得这样的配对图像非常费力,所以这限制了可以收集训练数据的规模。同样,在测试过程中,只能将服装的目录(店内)图像传输到用户的查询图像中。在[32]中,GAN用于将参考服装变形到查询人的图像上。不需要目录服装图像,但是仍然需要在多个姿势下穿着相同服装的同一个人的相应对。上述工作仅涉及上身服装的转换(除[4]外,仅适用于鞋子)。Sangwoo等人[22]应用分段蒙版,以控制生成的形状,例如将裤子转换为裙子。然而,在这种情况下,仅控制平移衣服的形状。此外,每个形状转换任务都需要其自己的专用网络。[33]的最新工作生成了穿着多件衣服的人的图像。但是,生成的人体模型仅由姿势控制,而不是由身体形状或外观控制。另外,该算法需要一套完整的成对图像的训练集,这尤其难以大规模获得。[25](SwapNet)的工作使用GAN在两个查询图像之间交换整个服装。它有两个主要阶段。 最初,它会生成查询人对参考服装的翘曲分割,然后覆盖服装纹理。此方法使用自我监督来学习形状和纹理转移,并且不需要成对的训练集。但是,它在装配级别而不是服装级别运行,因此缺乏可组合性。[9,12]的最新著作还通过形状和纹理生成的两个阶段来生成时尚图像。
装备虚拟试穿(O-VITON)
我们的系统使用形状和样式各异的穿着衣服的人的多个参考图像。用户可以在这些参考图像中选择服装,以接收算法生成的服装输出,该输出显示了穿着这些选定服装的个人图像(查询)的真实图像。
pix2pixHD方法[31]成功地完成了图像到图像的翻译任务,启发了我们解决这一难题的方法。类似于此方法,我们的生成器G以语义分割图和编码器E生成的外观图为条件。自动编码器为分割图中的每个语义区域分配一个代表区域外观的低维特征向量。这些基于外观的功能使您可以控制输出图像的外观,并解决不使用不使用它们的条件GAN经常出现的多样性不足的问题。
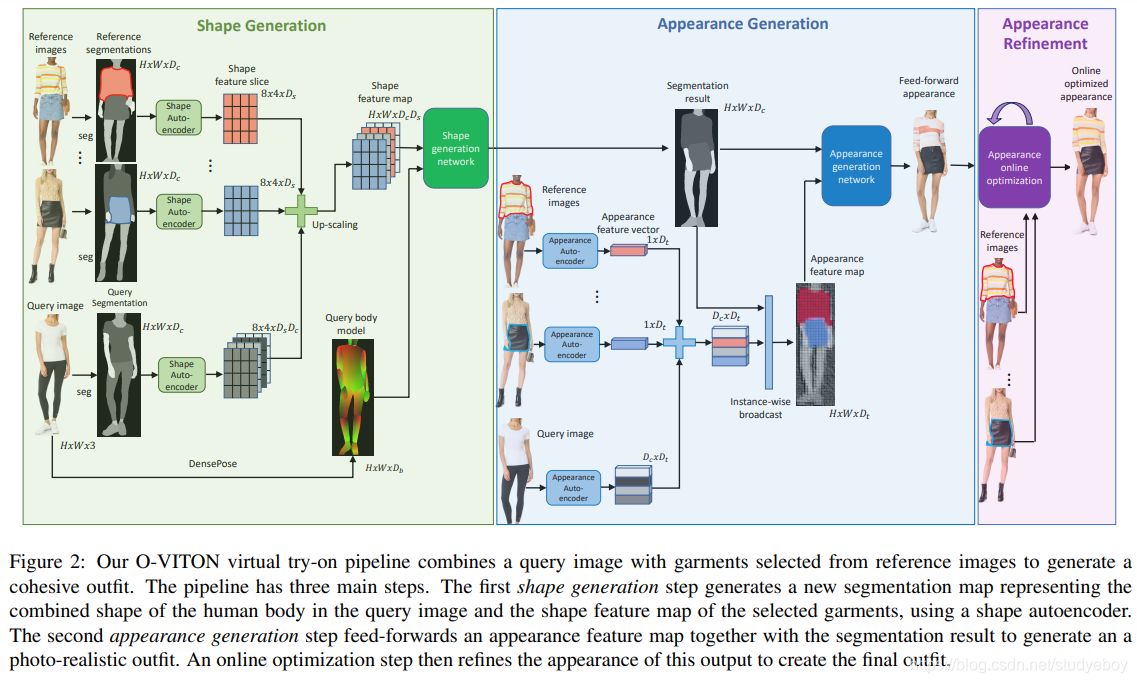
我们的虚拟试穿合成过程(图2)包括三个主要步骤:(1)生成分割图,该图始终将所选参考服装的轮廓(形状)与查询图像的分割图结合在一起。(2)生成在查询图像中显示该人穿着从参考图像中选择的服装的人的真实感图像。(3)在线优化以优化最终输出图像的外观。
我们将更详细地描述我们的系统:第3.1节描述了前馈综合管道及其输入,组件和输出。第3.2节描述了形状和外观网络的训练过程,第3.3节描述了用于微调输出图像的在线优化。
前馈生成
系统输入
我们系统的输入包括一个H×W RGB查询图像 x 0 x^0 x0,该图像有一个希望试穿各种服装的人。这些服装由一组M个附加参考RGB图像 ( x 1 , x 2 , . . . , x M ) (x^1,x^2,...,x^M) (x1,x2,...,xM)表示,其中包含分辨率与查询图像 x 0 x^0 x0相同的各种服装。请注意,这些图像可以是穿着不同衣服的人的自然图像,也可以是显示单个衣物的目录图像。另外,参考服装M的数量可以变化。为了获得时尚图像的分割图,我们训练了一个PSP [37]语义分割网络S,该网络输出大小为H×W×Dc的 s m = S ( x m ) s^m = S(x^m) sm=S(xm),其中 x m x^m xmxm中的每个像素都使用一热编码标记为Dc类之一。换句话说,s(i,j,c)= 1表示像素(i,j)被标记为c类。类别可以是身体部位,例如面部/右臂,也可以是服装类型,例如上衣,裤子,夹克或背景。我们使用分割网络S来计算查询图像的分割图 s 0 s^0 s0和参考图像(1≤m≤M,)的 s m s^m sm个分割图。类似地,捕获人的姿势和身体形状的DensePose网络[8]用于估计大小为H×W×Db的身体模型 b = B ( x 0 ) b = B(x^0) b=B(x0)。
形状生成网络组件
形状生成网络负责上述第一步:它将查询图像 x 0 x^0 x0中人的身体模型b与 { s m } m = 1 M \{s^m\}^M_{m = 1} { sm}m=1M表示的所选服装的形状结合起来(图2绿色 盒子)。如第3.1.1节所述,语义分割图 s m s^m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









