



 本文介绍了机器学习领域的核心概念,包括有监督学习和无监督学习的主要算法。有监督学习部分涵盖了数据预处理、简单线性回归、多元线性回归、逻辑回归、K近邻法、支持向量机、决策树和随机森林等。无监督学习则聚焦于K-均值聚类和层次聚类等聚类算法。文章旨在帮助读者理解各种算法的工作原理及其应用场景。
本文介绍了机器学习领域的核心概念,包括有监督学习和无监督学习的主要算法。有监督学习部分涵盖了数据预处理、简单线性回归、多元线性回归、逻辑回归、K近邻法、支持向量机、决策树和随机森林等。无监督学习则聚焦于K-均值聚类和层次聚类等聚类算法。文章旨在帮助读者理解各种算法的工作原理及其应用场景。
有监督学习
数据预处理
大部分模型算法使用两点间的欧式距离表示,但此特征在幅度、单位和范围姿态问题上变化很大。在家距离计算中,高幅度的特征比低幅度特征权重更大。可用特征标准化或Z值归一化解决。
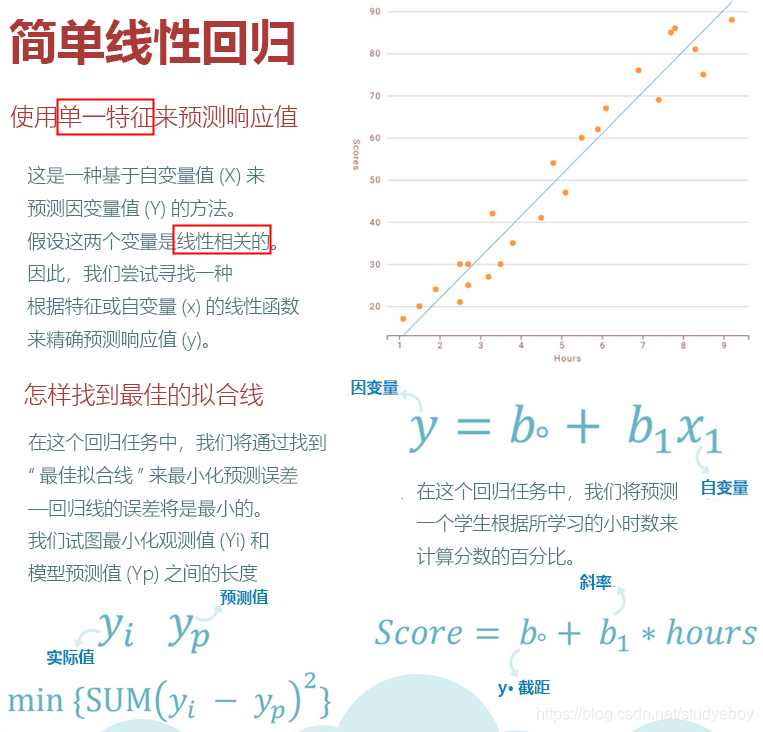
简单线性回归
多元线性回归


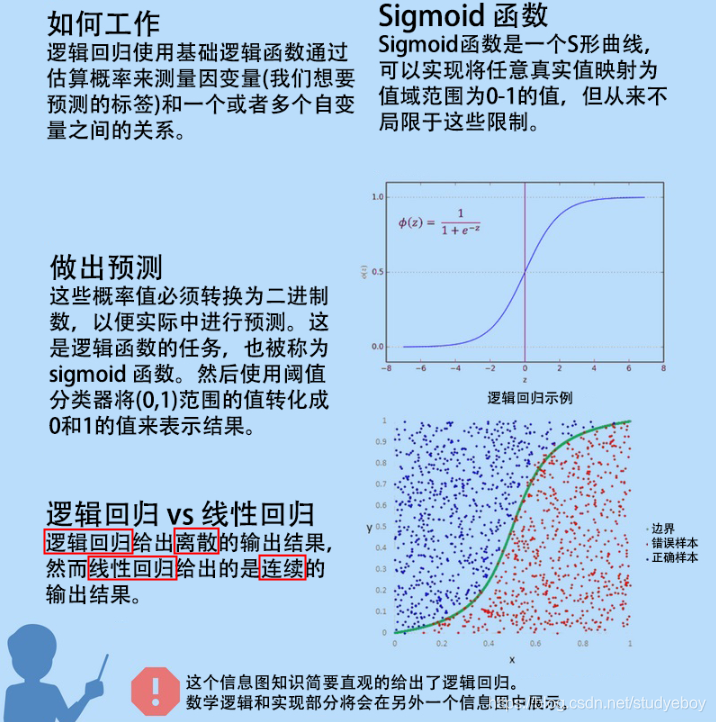
逻辑回归
逻辑回顾被用来处理不同的分类问题,这里的目的是预测当前被观察的对象属于哪一个组。它会给你提供一个离散的二进制输出结果。
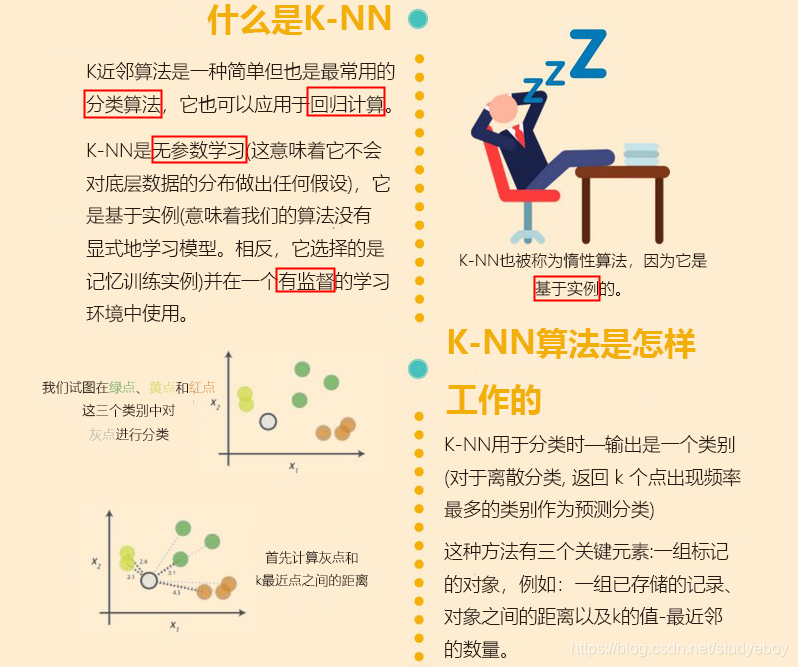
K近邻法(k-NN)

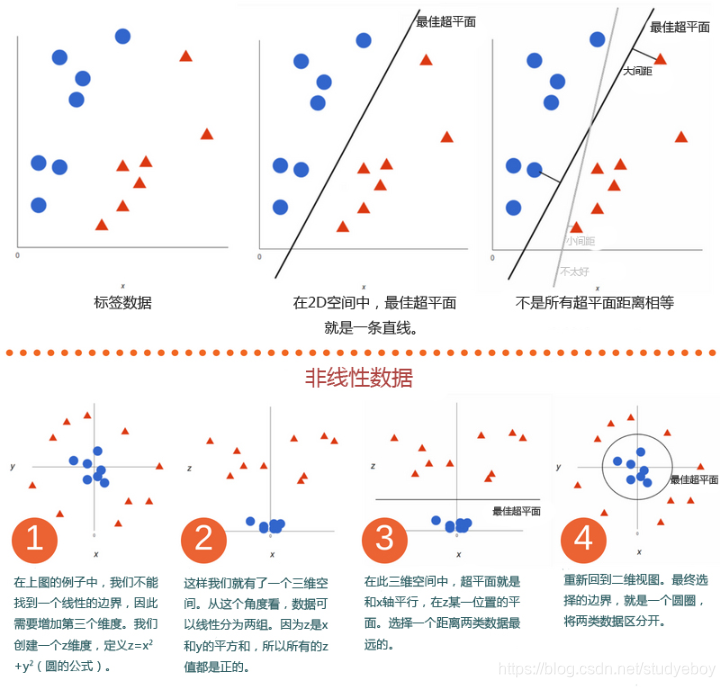
支持向量机(SVM)


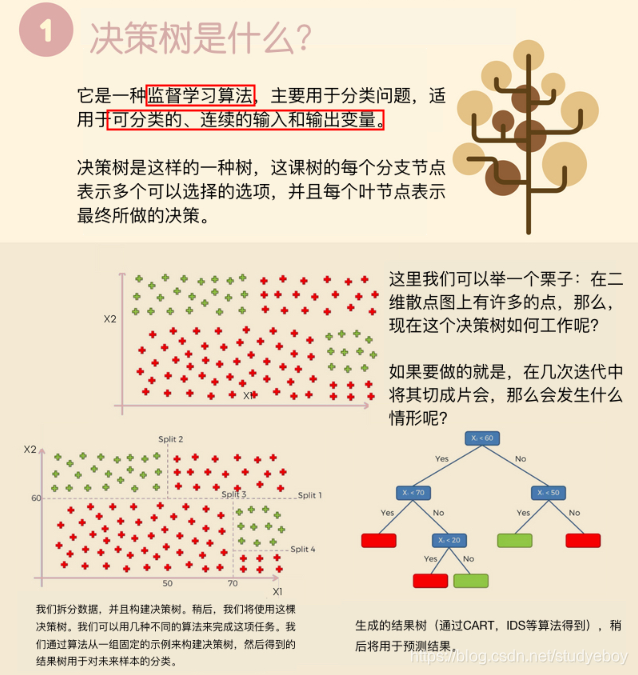
决策树

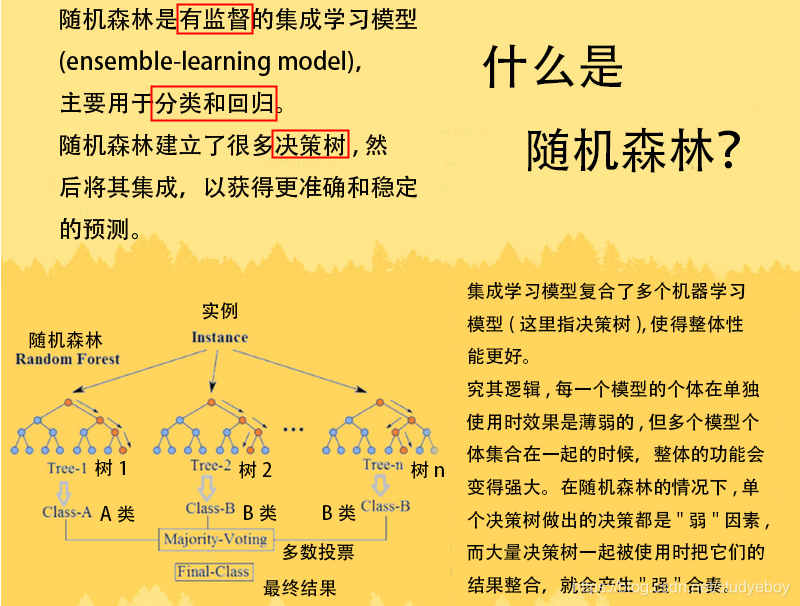
随机森林


无监督学习
无监督学习允许在对结果无法预知时接近问题。无监督算法只基于输入数据找到模式。当无法确定寻找内容时,这个技术很有用。
聚类算法用于把族群或数据点分隔成一系列的组,使得相同簇中的数据点比其他的组更相似。基本上,目的是分隔具有相似形状的组,并且分配到簇中。
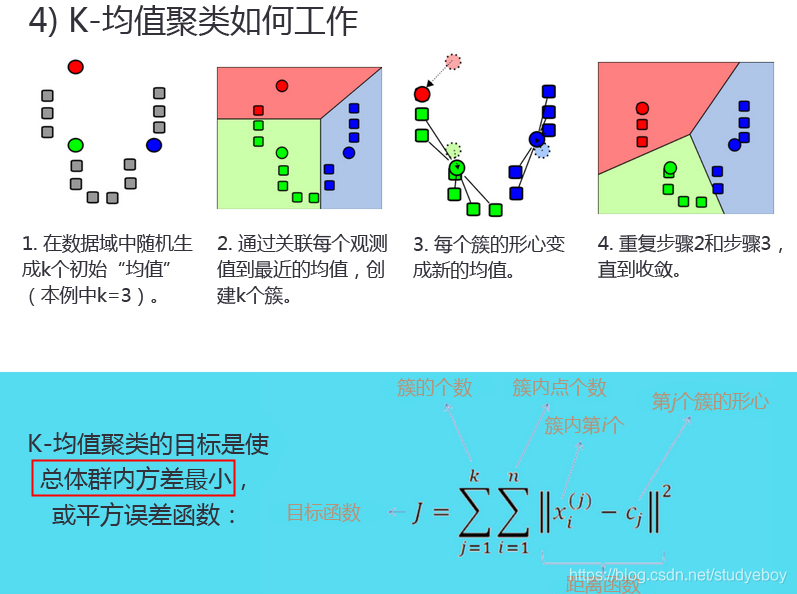
K-均值聚类
在K-均值聚类算法中,把所有项分成k个簇,使得相同簇中的所有项彼此尽量相似,而不同簇的项尽量不同。
距离测量(类似欧式距离)用于计算数据点的相似度和相异度。每个簇有一个形心,形心可理解为最能代表簇的点。
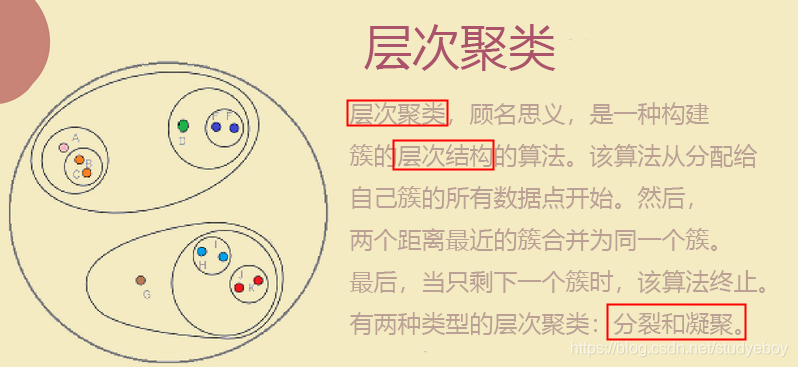
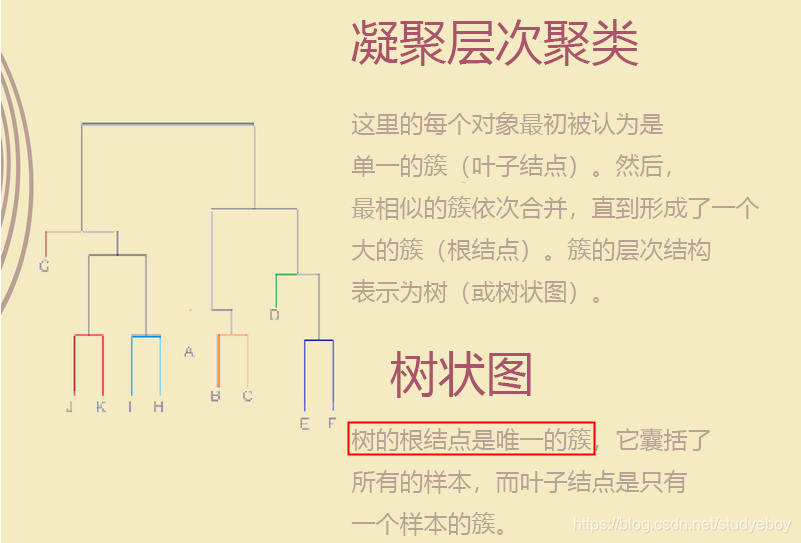
层次聚类

参考资料
100-Days-Of-ML-Code

















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









