






 文章讲述了在数据库查询中如何使用ROW_NUMBER()函数结合PARTITIONBY子句来实现数据的排序和分区,特别是在处理如产品编码表这样的业务场景中,如何按子编码的使用频率进行排序和编号。通过举例说明了如何对学生按课程成绩进行分区排序,展示了这两个函数的实用性和效果。
文章讲述了在数据库查询中如何使用ROW_NUMBER()函数结合PARTITIONBY子句来实现数据的排序和分区,特别是在处理如产品编码表这样的业务场景中,如何按子编码的使用频率进行排序和编号。通过举例说明了如何对学生按课程成绩进行分区排序,展示了这两个函数的实用性和效果。
业务场景:经常会出现需要做个排名列,这个列是非源表列,目前为了得到相应的顺序。比如,业务有个产品编码表,其中有父编码列,子编码列,一个父编码会对应多个子编码,比如父编码为 a1, 组成的子编码有多个为 suba1,suba2.. 对应多条数据,而且这里也会存在不同的父编码,其包含相同的子编码,也就是说不同的产品用了相同的子模块,那么我们想看看每个子模块,分别都被多少个父编码使用,并且按相应顺序显示,这么就可以利用排名函数,对子模块进行分区,这样就可以得到,如果一个子编码有对应多个父编码的记录,那么就是会有相应的展示其记录并且有编号按序展示
ROW_NUMBER()函数将针对SELECT语句返回的每一行,从1开始编号,赋予其连续的编号。在查询时应用了一个排序标准后,只有通过编号才能够保证其顺序是一致的,当使用ROW_NUMBER函数时,也需要专门一列用于预先排序以便于进行编号
partition by关键字是分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,分区函数一般与排名函数一起使用。
下面举个例子,比如有学生,课程 , 分数
s_id 表是学生编号,c_id表是课程编号,s_score 表是学生对应的课程分数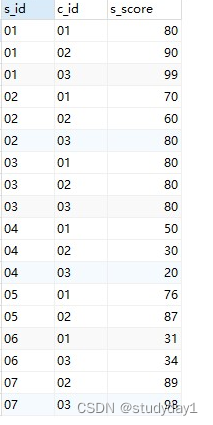
1.要求:得出每门课程的学生成绩排序(升序)
----因为是每门课程的结果,并且要排序,所以用row_number
select * ,row_number() over (partition by c_id order by s_score) as rankNum from score;
结果如下:这里后续的没有继续列出,但是也很清楚的看到 按cid分区后,区内按分数score升序排序
| sid | cid | sscore | rankNum |
| 06 | 01 | 31 | 1 |
| 04 | 01 | 50 | 2 |
| 02 | 01 | 70 | 3 |
| 05 | 01 | 76 | 4 |
| 01 | 01 | 80 | 5 |
| 03 | 01 | 80 | 6 |
| 04 | 02 | 30 | 1 |
| 02 | 02 | 60 | 2 |
| 03 | 02 | 80 | 3 |


















 6676
6676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









