







 本文深入解析了Java集合框架中ArrayList与LinkedList的实现原理,包括它们的底层数据结构、常用操作方法及性能特点,并对比了两者的优缺点。
本文深入解析了Java集合框架中ArrayList与LinkedList的实现原理,包括它们的底层数据结构、常用操作方法及性能特点,并对比了两者的优缺点。
一.Collection的整体架构
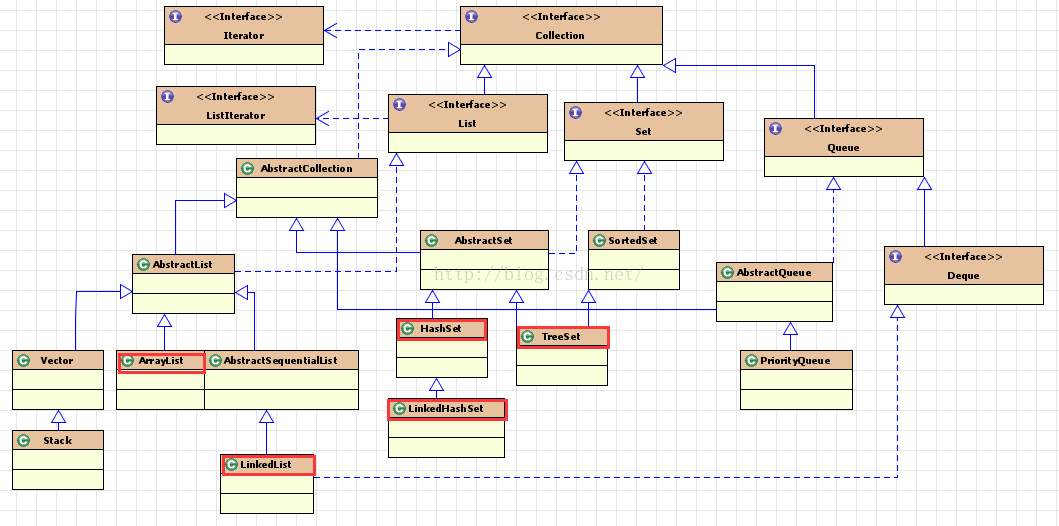
我们主要学习经常使用的集合类,ArrayList,LinkedList,HashSet,TreeSet
1.Collection中的接口和抽象类
可以看到最上面的接口是Iterable
/**
* Returns an iterator over a set of elements of type T.
*
* @return an Iterator.
*/
Iterator<T> iterator();
只有一个方法,就是获得迭代器
boolean hasNext(); //是否有下一个元素
E next(); //获得下一个元素
void remove(); //删除当前元素
Collection
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
}
collection接口中的方法基本组成了数据的增、删、判断等,可以看到有equals和hashCode方法,因为collection没有继承Object,所以在这里增加了这两个方法.
AbstractCollection
public abstract class AbstractCollection<E> implements Collection<E> {
protected AbstractCollection() {
}
public String toString(){
}
}
List
public interface List<E> extends Collection<E> {
E get(int index);
E set(int index, E element);
void add(int index, E element);
E remove(int index);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
ListIterator<E> listIterator(int index);
List<E> subList(int fromIndex, int toIndex);
}
list增加了通过索引来对集合进行查增删改
还有一个ListIterator迭代器
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}
可以看到,相比之前的迭代器,ListIterator增加了获得向前、向后索引,向前遍历、修改和增加元素的方法
另一个是subList方法,该方法返回的子List是原始List的一个视图,所以对子List的修改会导致原始List修改,但是原始List进行修改会如何影响子List是不确定的
AbstractList
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
protected void removeRange(int fromIndex, int toIndex) {
ListIterator<E> it = listIterator(fromIndex);
for (int i=0, n=toIndex-fromIndex; i<n; i++) {
it.next();
it.remove();
}
}
}
这个类增加了一个方法,removeRange,该方法可以移除一个范围内的数据
上面的分析基本上把ArrayList,LinkedList所继承的父类都分析了一遍,下面主要看ArrayList和LinkedList
2.ArrayList
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
ArrayList除了我们之前分析的接口和类之外,还实现了RandomAccess, Cloneable, java.io.Serializable
RandomAccess是Java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号来快速获取元素对象,这就是快速随机访问,其访问速度比迭代访问快
Cloneable使ArrayList可以使用克隆
java.io.Serializable支持序列化,这样,我们可以传输数据
ArrayList是非线程安全的
public static void main(String[] args) {
ArrayList<String> listString = new ArrayList<String>();
for(int i=0;i<5;i++){
listString.add(i+"");
}
listString.get(2);
listString.set(0, "9");
}
首先是创建ArrayList,没有设置创建的大小,它默认创建一个大小为10的list
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
add方法:
public boolean add(E e) {
ensureCapacity(size + 1); // Increments modCount!! //判断是否扩容
elementData[size++] = e; //设置数据
return true;
}
主要执行了下面方法:
public void ensureCapacity(int minCapacity) {
modCount++; //该List被修改的次数
int oldCapacity = elementData.length; //得到原始数组的大小
if (minCapacity > oldCapacity) { //如果要增加元素的位置大于原始数组的大小,则暂存原始数据,并且扩大elementData的容量
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1; //扩展为原来的1.5倍+1
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//复制并扩容
}
}
add(E e) 先对数据进行移动,然后在添加数据,其时间复杂度是线性的
add(int index, E element)
addAll(Collection<? extends E> c)
addAll(int index, Collection<? extends E> c)
同类的三个方法都是其先扩容,然后在复制
set(int index, E element)
public E set(int index, E element) {
RangeCheck(index);//下标越界检测
E oldValue = (E) elementData[index];
elementData[index] = element;//对象复制到指定位置,
return oldValue;
}
get(int index)
public E get(int index) {
RangeCheck(index);//检测下标越界
return (E) elementData[index];//得到元素并且进行类型转换
}
remove(Object o)
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);//快速移除,原理是把index到size-1的元素向前移动1
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
remove(int index)
public E remove(int index) {
RangeCheck(index);
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work 让Gc垃圾回收
return oldValue;
}
前面我们说到,ArrayList实现了序列化接口,可以进行序列化和反序列化,但是,我们又看到ArrayList实际存储数据的是数组elementData,而它的修饰符是transient,表明,那么它是不会被串行化的,ArrayList是怎么串行化的了,实际上是下面两个方法来实现
private void writeObject(java.io.ObjectOutputStream s){ //输出流
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {//输入流
}
3.LinkedList
LinkedList底层使用双向链表来实现,每一个数据就等于一个节点,LinkedList使用一个内部类来维护节点
private static class Node<E> {
E item; //元素值
Node<E> next; //下一个节点
Node<E> prev; //当前节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList以下面两个变量来维护链表
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
同样以下面代码来分析
public static void main(String[] args) {
LinkedList<String> listString = new LinkedList<String>();
for(int i=0;i<5;i++){
listString.add(i+"");
}
listString.get(2);
listString.set(0, "9");
}
首先,是创建LinkedList
/**
* Constructs an empty list.
*/
public LinkedList() {
}
可以看到,只是创建了一个空的对象,那么其维护链表的first,last也是空的
add(E)
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)//last为空,说明集合中没有元素,这时候first和last都被设置指向了第一个节点
first = newNode;
else
l.next = newNode;//不为空,就把这个元素插入到last的下一个节点
size++;
modCount++;
}
如下图所示:

add(int index, E element)
public void add(int index, E element) {
checkPositionIndex(index);//检测索引是否合法
if (index == size)//如果添加的位置和集合的元素个数相同,则直接添加在末尾
linkLast(element);
else
linkBefore(element, node(index));
}
当不同的时候,调用 linkBefore(element, node(index))
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev; //要插入位置元素的前一个元素
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;//设置插入位置元素的前一个元素为插入元素
if (pred == null)//如果要插入位置元素的前一个元素为空,那么表示要插入到第一个位置,付给first
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
remove(Object o)
public boolean remove(Object o) {
if (o == null) {//
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
可以看到都是遍历这个链表,来判断,使用unlink(x)
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {//删除的是第一个元素
first = next;
} else {
prev.next = next;//改变链接指向
x.prev = null;
}
if (next == null) {//删除的是最后一个元素
last = prev;
} else {
next.prev = prev;//改变链接指向
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
remove(int index)
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
可以看到,它调用的是同一个方法unlink()
E get(int index)
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
node(int index)
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {//判断索引在中间的前后
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
set(int index, E element)
public E set(int index, E element) {
checkElementIndex(index);//检测是否越界
Node<E> x = node(index);//查找此值
E oldVal = x.item;
x.item = element;
return oldVal;
}
4.ArrayList和LinkedList的区别和联系
相同点
两个都是非线程安全的
区别:
1.ArrayList是基于动态数组来实现的,LinkedList是基于链表结构来实现
2.对于随机访问get,set ArrayList要优于LinkedList,因为LinkedList要基于指针移动去查找节点
3.对于add和remove方法,谁快谁慢不一定,因为ArrayList花费的时间主要在System.arrayCopy复制数组上,LinkedList主要在查找节点上,有人做了测试,结果是当插入的数据量很小时,两者区别不太大,当插入的数据量大时,大约在容量的1/10之前,LinkedList会优于ArrayList,在其后就劣与ArrayList,且越靠近后面越差。
既然上面两个是非线程安全的,又没线程安全的List子类了,当然有,就是Vector,Vector也是一个动态数组来实现,不过Vector增量是原来的两倍。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
从上面可以看到,其Vector是线程安全的

















 2529
2529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









