




 本文深入解析MySQL查询语句的使用,涵盖选择、筛选、分组和排序语句,以及函数、注释和代码规范等内容,通过实例帮助读者掌握查询技巧。
本文深入解析MySQL查询语句的使用,涵盖选择、筛选、分组和排序语句,以及函数、注释和代码规范等内容,通过实例帮助读者掌握查询技巧。
MySQL 基础 (一)- 查询语句
0.引言
上一篇文章中介绍了mysql的安装和数据库的基础知识,描述了SQL语言和MySQL语言的基本背景,而本文介绍MySQL基础知识中的查询语句和相关语句。
1.导入数据库
创建数据库yourdb并导入yourdb.sql中的数据库:
mysql> CREATE DATABASE IF NOT EXISTS yourdb DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
mysql> use yourdb;
mysql>source C:/desktop/yourdb.sql;
2.查询语句
查询语句是MySQL中的保留字,是不区分大小写的,但一般查询语句使用大写字母,便于区分,有些软件给保留字加上颜色,以作区分。
2.1 选择语句
SELECT FROM语句
用于从一个或多个表中检索信息:
检索出的数据未排序,此时数据的顺序一般是底层表中的顺序,没有意义。
SELECT column FROM table:从table表检索列column;
SELECT column1,column2 FROM table :从table表检索列column1,column2;
SELECT * FROM table:从table表检索所有列;
DINSTINCT子句
用于去除重复信息:
DINSTINCT放在被检索的列之前,且作用于之后的所有列。
SELECT DINSTINCT column FROM table:从table表中检索column列中不同的值,重复值只出现一次;
SELECT DINSTINCT column1,column2 FROM table:从table表中检索column1,2两列中不同的值,column1,2两列都相同的值只出现一次;
LIMIT子句
用于限制返回语句的数量:
LIMIT子句放在最后,OFFSET默认为0,LIMIT n 返回前n个记录。
SELECT column FROM table LIMIT 1 OFFSET 0:检索column中的第一行信息;
SELECT column FROM table LIMIT n OFFSET 0:检索column中的前n行信息;
SELECT column FROM table LIMIT n OFFSET m:检索column中从m-1行开始的前n行信息;
SELECT column FROM table LIMIT m,n:检索column中从m-1行开始的前n行信息;
CASE END子句
用于条件判断:
判断table中的column列的值value,给出不同的返回值output。
SELECT CASE column
WHEN value1 THEN output1
WHEN value2 THEN output2
ELSE output3
END FROM table:
或
SELECT CASE
WHEN column = value1 THEN output1
WHEN column = value2 THEN output2
ELSE output3
END FROM table:
2.2 筛选语句
WHERE子句
用于指定条件进行数据的筛选和过滤:
WHERE子句放在表名table的后面,后面跟着条件语句。
SELECT column, column2,...columnN FROM table1, table2...tableM
[WHERE condition1 [AND [OR]] condition2.....
从M个表中选择使WHERE后条件语句返回值为true的N列
条件语句使用了一些运算符、操作符和通配符:
算术运算符
“+”:加法;
“-”:减法;
“*”:乘法;
“/”或“DIV”:除法;
“%”或“MOD”:取余。
比较运算符
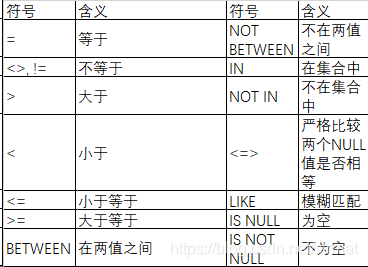
逻辑操作符
AND:逻辑与;
OR:逻辑或;
NOT或!:逻辑非;
XOR:逻辑异或;
IN:IN (value1,value2)等同 = value1 OR value2.
通配符
通配符是用来匹配值的一类特殊字符,用于模糊搜索符合一类搜索模式的值,在WHERE子句中使用通配符,需要添加LIKE操作符。
常见通配符:
“%”:表示任意字符出现任意次数;
“_”:下划线,表示单个的任意字符;
SELECT column FROM table WHERE column LIKE "%":匹配任意值;
SELECT column FROM table WHERE column LIKE "a%":匹配以a开头的任意值;
SELECT column FROM table WHERE column LIKE "_":匹配单个字符任意值;
SELECT column FROM table WHERE column LIKE "a_":匹配以a开头的两字符的任意值;
2.3 分组语句
GROUP BY语句
用于数据记录的分组
- GROUP BY可以使用任意列;
- 使用的列是检索列或有效的表达式,不能是聚集函数或SELECT中的alias;
- NULL值会被分为一组;
- 聚集函数将会按分组后的组来分别计算。
聚集函数
用于汇总数据信息而不返回实际表数据的函数,如确定表中行数,某些行的和,某一列的平均数,总数,最大值,最小值。
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
HAVING子句
用于筛选分组
- WHERE后能用的条件语句,HAVING都能用;
- WHERE子句筛选指定的是行,而HAVING指定的是分组;
- HAVING需要和GROUP BY一起使用。
2.4 排序语句
ORDER BY 子句
用于对查询返回的记录进行排序:
-
可以使用任意列和多个列进行排序;
-
可以在列名前加上“ASC”和“DESC”指定为升序和降序排列,默认是升序;
-
对多个列降序排列,每个列前面都要加“DESC”。
SELECT column FROM table ORDER BY DESC column 按column列的字母顺序降序排列
3.函数
函数为数据的转换和处理提供了方便,但不同的DBMS上的用法可能不同,不利于代码的移植。MySQL支持多种函数,在官方给出的用户手册中有详细的记录。
MySQL官方手册函数部分
3.1 时间函数
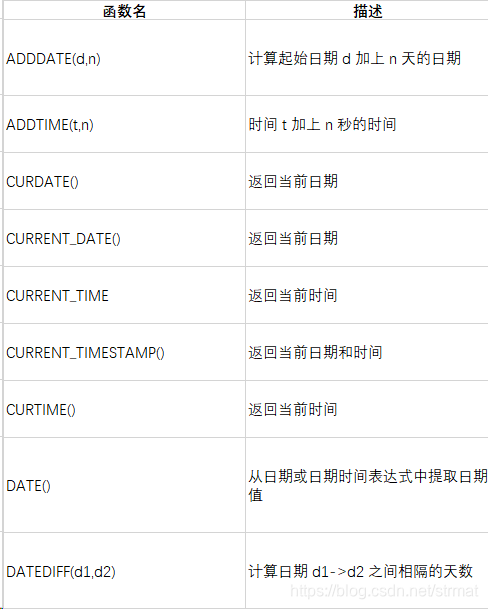
3.2 数值函数
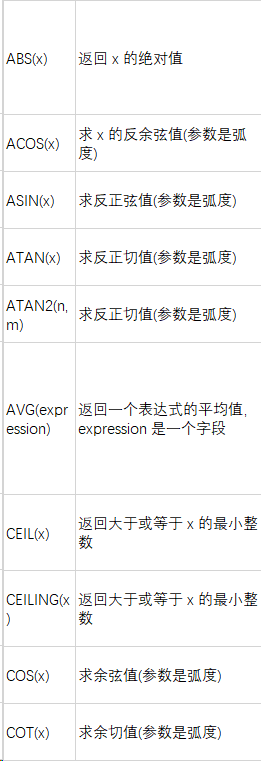
3.3 字符串函数
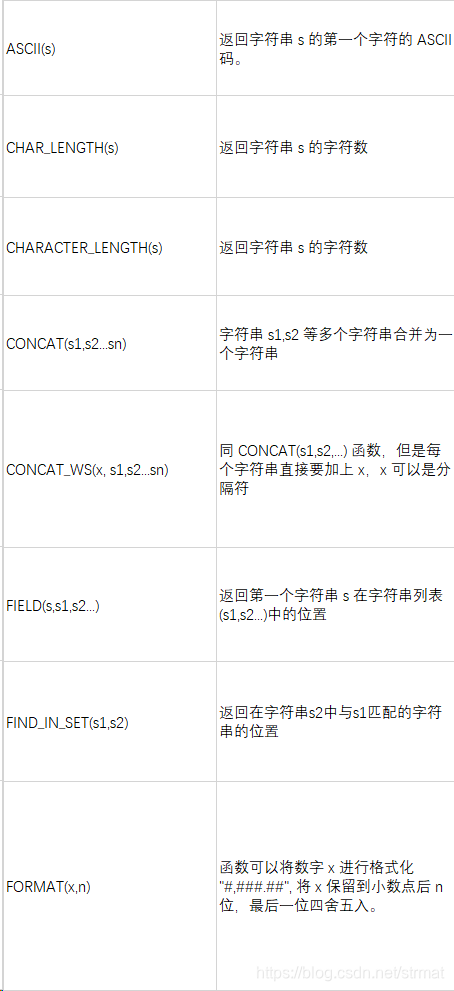
4.MySQL注释
注释用途
- 描述性的注释,便于自己今后参考,或者供项目后续参与人员参考;
- SQL文件开始加上程序员的联系方式、程序描述以及一些说明;
- 测试时注释掉暂时不用的那部分代码。
注释方法
- 在一行的开始出使用“#”号,这一行都是注释;
- 在一行的中间使用“–”(两个连字符),这一行“–”之后的文字都是注释;
- 从/开始,到/结束,/和/之间的任何内容都是注释。
5.MySQL代码规范
参考
《Joe Celko’s SQL Programming Style》
SQL样式指南–Simon Holywell
建议
使用一致的、叙述性的名称。
灵活使用空格和缩进来增强可读性。
存储符合ISO-8601标准的日期格式(YYYY-MM-DD HH:MM:SS.SSSSS)。
最好使用标准SQL函数而不是特定供应商的函数以提高可移植性。
保证代码简洁明了并消除多余的SQL——比如非必要的引号或括号,或者可以推导出的多余WHERE语句。
必要时在SQL代码中加入注释。优先使用C语言式的以/*开始以*/结束的块注释,或使用以--开始的行注释。
避免
驼峰命名法——它不适合快速扫描。
描述性的前缀或匈牙利命名法比如sp_或tbl。
复数形式——尽量使用更自然的集合术语。比如,用“staff”替代“employees”,或用“people”替代“individuals”。
需要引用号的标识符——如果你必须使用这样的标识符,最好坚持用SQL92的双引号来提高可移植性。
面向对象编程的原则不该应用到结构化查询语言或数据库结构上。
命名
保证名字独一无二且不是保留字。
保证名字长度不超过30个字节。
名字要以字母开头,不能以下划线结尾。
只在名字中使用字母、数字和下划线。
不要在名字中出现连续下划线——这样很难辨认。
在名字中需要空格的地方用下划线代替。
尽量避免使用缩写词。使用时一定确定这个缩写简明易懂。
6.实例
6.1.查找重复的电子邮箱
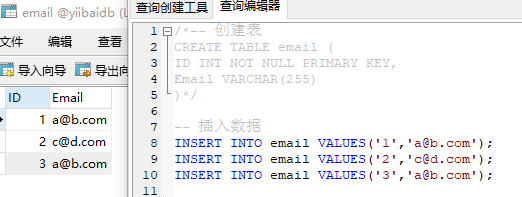
要求1:创建 email表,并插入如下三行数据
| ID | |
|---|---|
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
代码:
-- 创建表
CREATE TABLE email (
ID INT NOT NULL PRIMARY KEY,
Email VARCHAR(255)
)
-- 插入数据
INSERT INTO email VALUES('1','a@b.com');
INSERT INTO email VALUES('2','c@d.com');
INSERT INTO email VALUES('3','a@b.com');
运行结果:
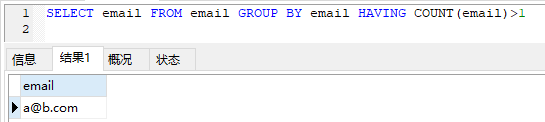
要求2: 编写一个 SQL 查询,查找 email 表中所有重复的电子邮箱。 根据以上输入,你的查询应返回以下结果:
| a@b.com |
说明:所有电子邮箱都是小写字母。
代码:
SELECT email FROM email GROUP BY email HAVING COUNT(email)>1
运行结果:
6.2 查找大国
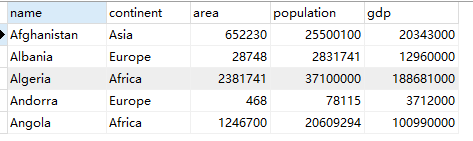
要求1:创建如下 World 表
| name | continent | area | population | gdp |
|---|---|---|---|---|
| Afghanistan | Asia | 652230 | 25500100 | 20343000 |
| Albania | Europe | 28748 | 2831741 | 12960000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000 |
| Andorra | Europe | 468 | 78115 | 3712000 |
| Angola | Africa | 1246700 | 20609294 | 100990000 |
代码:
-- 创建表
CREATE TABLE World (
name VARCHAR(50) NOT NULL,
continent VARCHAR(50) NOT NULL,
area INT NOT NULL,
population INT NOT NULL,
gdp INT NOT NULL
);
-- 插入数据
INSERT INTO World VALUES( 'Afghanistan', 'Asia',652230,25500100,20343000);
INSERT INTO World VALUES( 'Albania', 'Europe' ,28748,2831741,12960000);
INSERT INTO World VALUES( 'Algeria', 'Africa' ,2381741,37100000,188681000);
INSERT INTO World VALUES( 'Andorra' , 'Europe' ,468,78115,3712000);
INSERT INTO World VALUES( 'Angola' , 'Africa' ,1246700,20609294,100990000);
运行结果:
要求2:如果一个国家的面积超过300万平方公里,或者(人口超过2500万并且gdp超过2000万),那么这个国家就是大国家。 编写一个SQL查询,输出表中所有大国家的名称、人口和面积。 例如,根据上表,我们应该输出:
| name | population | area |
|---|---|---|
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
代码:
SELECT NAME, population, area FROM world
WHERE area > 3000000 OR population > 25000000 AND gdp > 2000;
运行结果:
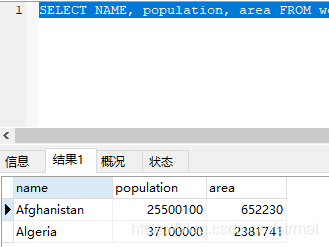

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









