






读写分离架构
什么是读写分离结构
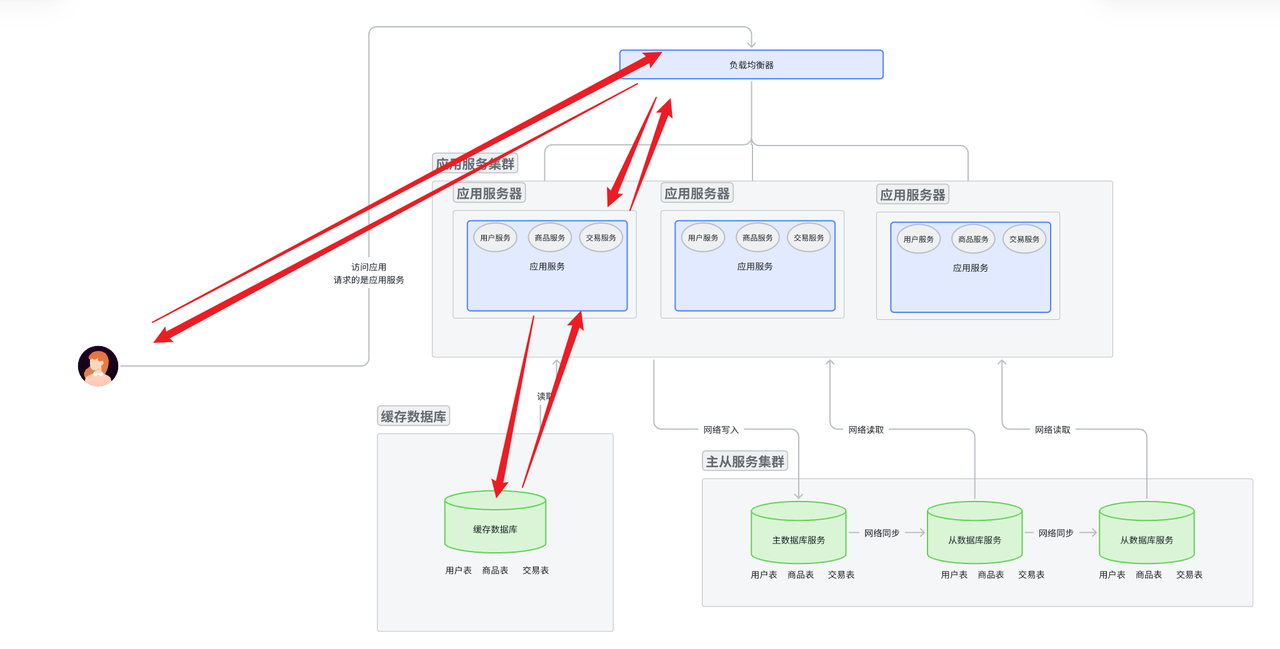
读写分离架构针对于数据库。数据库原本负责读写两个功能。 读写分离架构就是添加多台数据库服务器, 其中主数据库一般负责写, 从数据库一般负责读。
读写分离架构也叫做主从分离架构, 一台数据库服务器作为主服务器, 然后为这台主服务器添加冗余(从服务器)。 这样做的好处有很多, 下面优缺点提到。
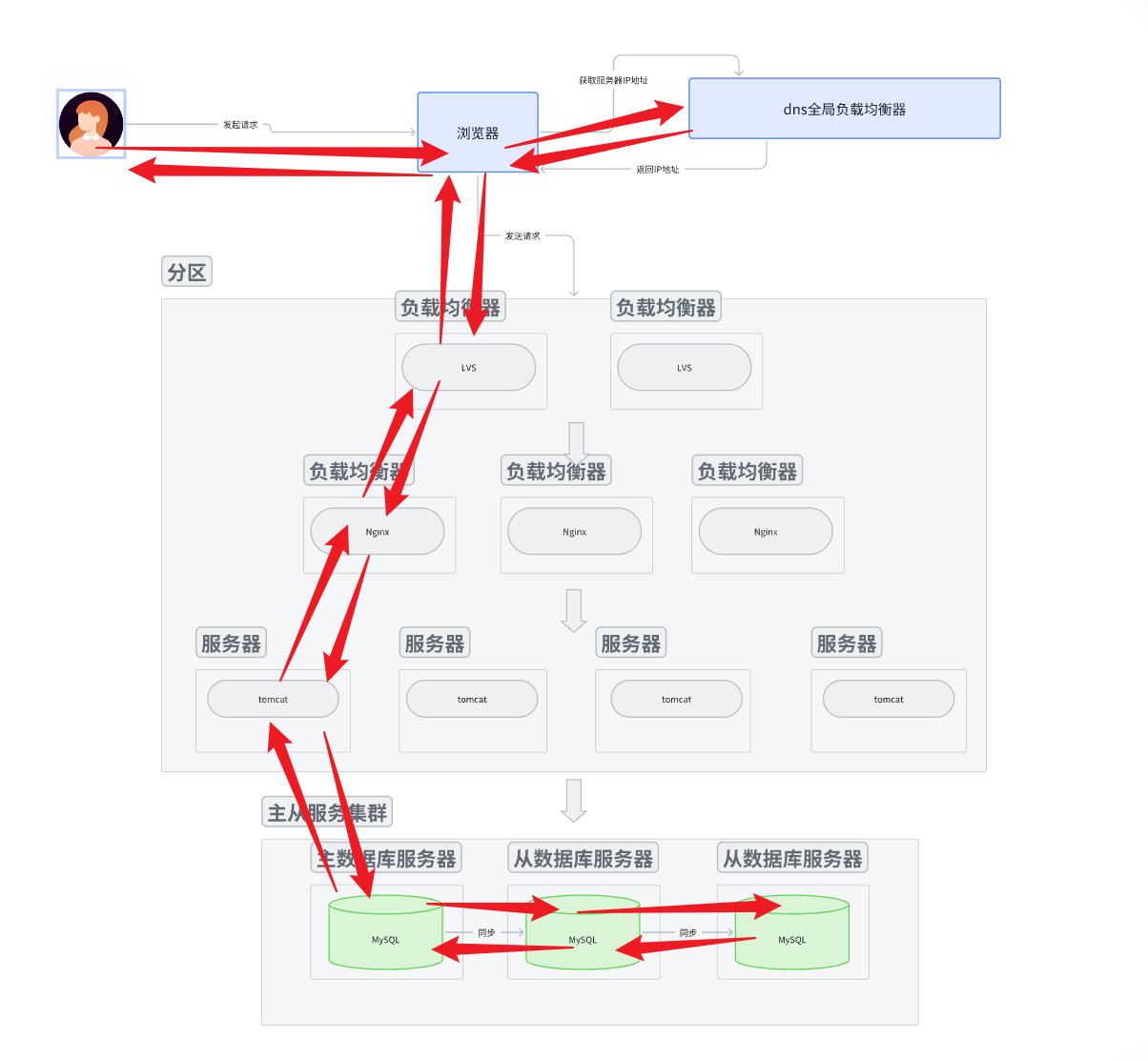
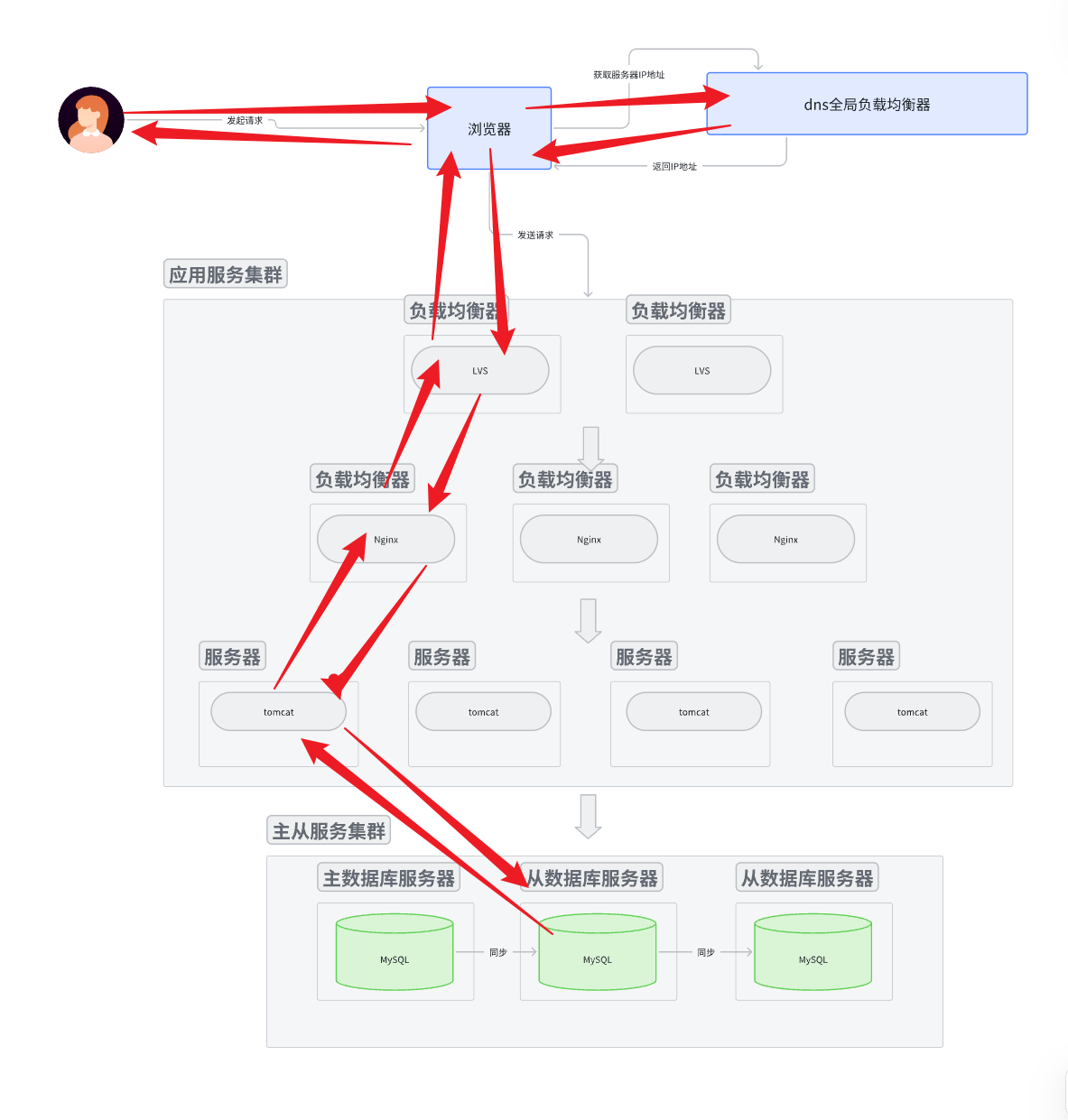
架构模型
优缺点
优点
- 可以应对更高的并发量, 读写分离,从数据库分担了主数据库的读请求。
- 高可用性, 增加了系统的冗余, 当主数据库崩溃时, 从数据快速顶替主数据库,不影响用户体验。
- 从数据库可以进行横向扩展,使数据库对于读具有扩展性。读请求理论上不再称为瓶颈。
- 主数据和从数据库通过网络实现数据同步一致。
缺点
- 硬件资源的成本增加, 运维成本增加
- 单点写瓶颈, 写并发极高时主数据称为瓶颈
- 数据不一致性, 数据网络同步需要时间, 用户写入后想要立即读取,可能读取不到最新更新信息。
- 主数据库同步时崩溃会导致数据丢失。
技术案例
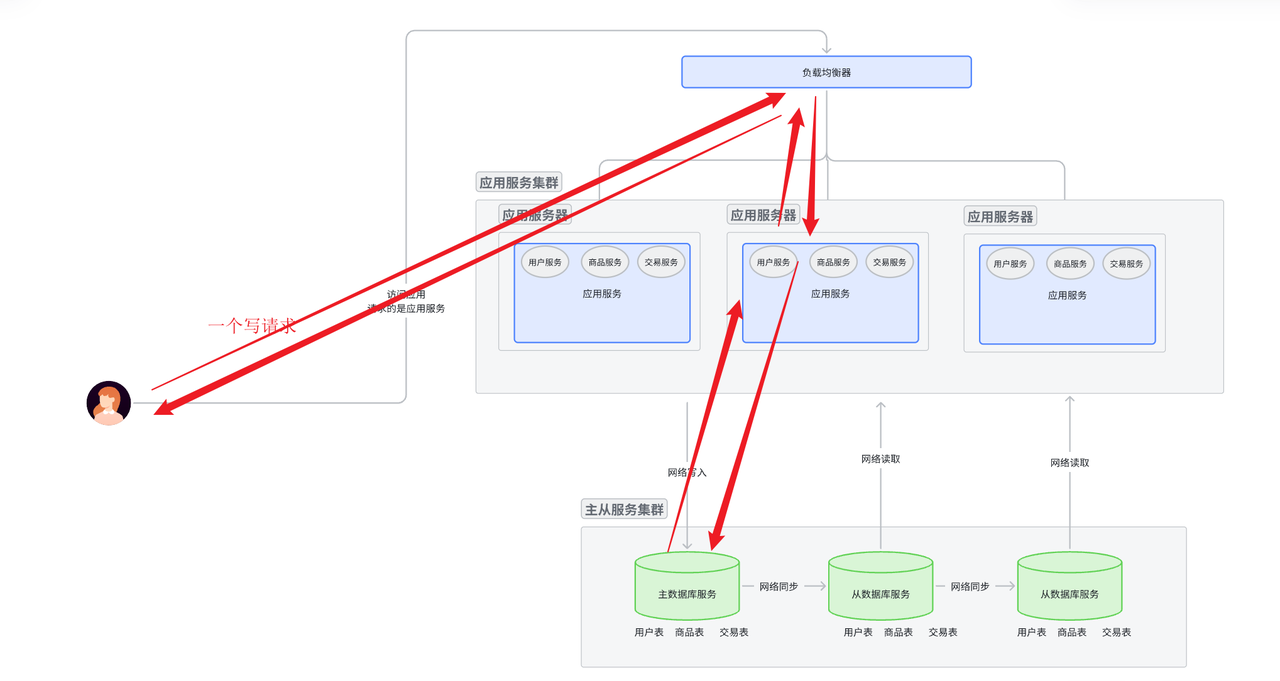
写情况
- 用户使用域名访问服务器,先访问dns, dns返回一个IP地址。
- 用IP地址进行路由访问应用服务器。访问哪一个? 先到达最外层的负载均衡服务器, 由最外层的负载均衡服务器将这个请求分发下层自己管理的某个服务器。
- 这个服务器接收到请求, 如果这个服务器还是一个负载均衡服务器, 就重复刚刚类似的操作。
- 如果这个服务器是一个应用服务器, 那么应用服务器对请求进行解析。
- 如果是写请求, 就去主数据库中写入数据,将数据通过网络发送给主数据库服务器。 然后就返回写入情况, 是写入成功还是失败。对于应用服务集群来说, 应用服务器集群一层一层向上返回请求处理情况; 对于主从数据库集群来说, 主数据库要将刚刚写入的数据同步给从数据库。
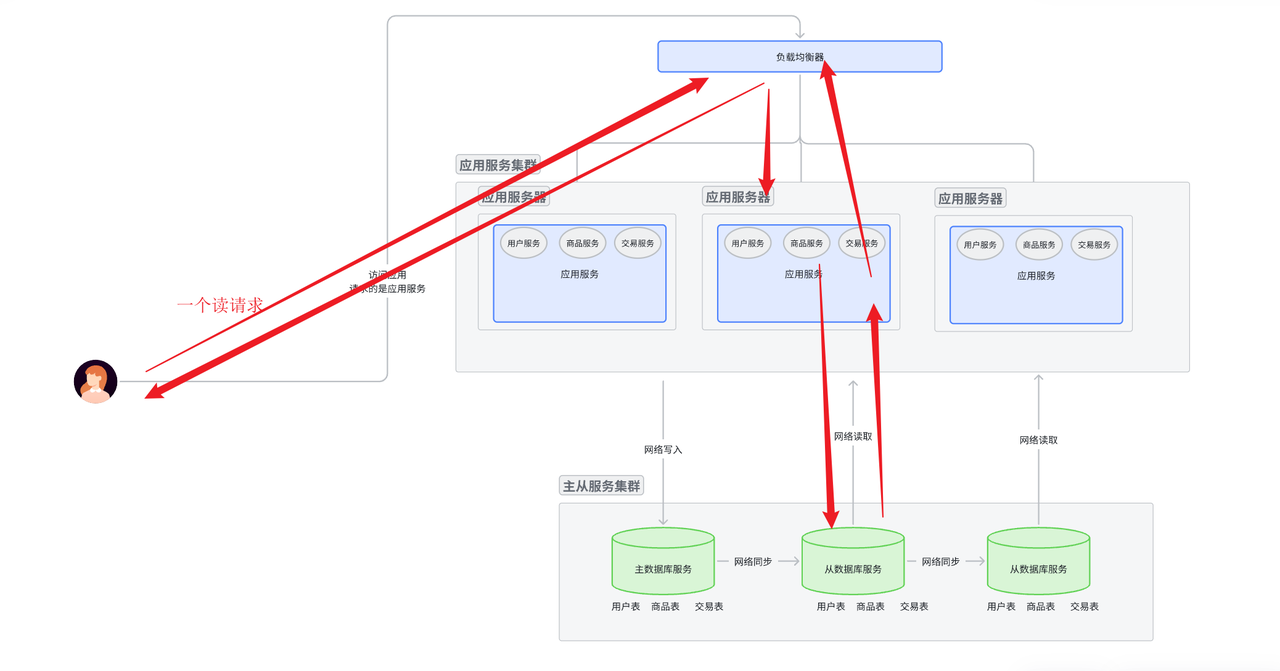
读情况
- 用户拿着 域名 访问应用服务器, 然后域名交给dns进行解析, 返回IP地址。
- 浏览器用IP地址路由到对应的服务集群中。 具体访问哪一个应用服务节点, 由上层的负载均衡服务器一层
一层向下分发决定。
- 应用服务节点拿到请求后, 对请求进行解析。 解析成功认为是读请求, 那么就直接去主从数据库集群里面的从数据库节点读取数据。 然后返回读取结果。
冷热分离架构
什么是冷热分离架构?
冷热分离是将数据分为冷数据和热数据。 热数据存放在内存缓存中。 冷数据放在磁盘中。 一个数据库服务器或者集群作为缓存数据库服务器, 存储热数据。 然后另一个数据库集群用来存储冷数据。
架构模型
优缺点
优点
- 分担了读取的压力, 减少了从库的数量, 优化成本。
- 利用内存存储数据, 内存的读取速度远高于磁盘IO。 提高了数据查询的效率, 优化效率。
缺点
- 增加系统的复杂性, 增加运维成本。
- 数据同步过程中如果数据库崩溃, 造成数据丢失和数据不一致问题。
- 写的高并发仍然可能是系统的瓶颈。
技术案例
读数据
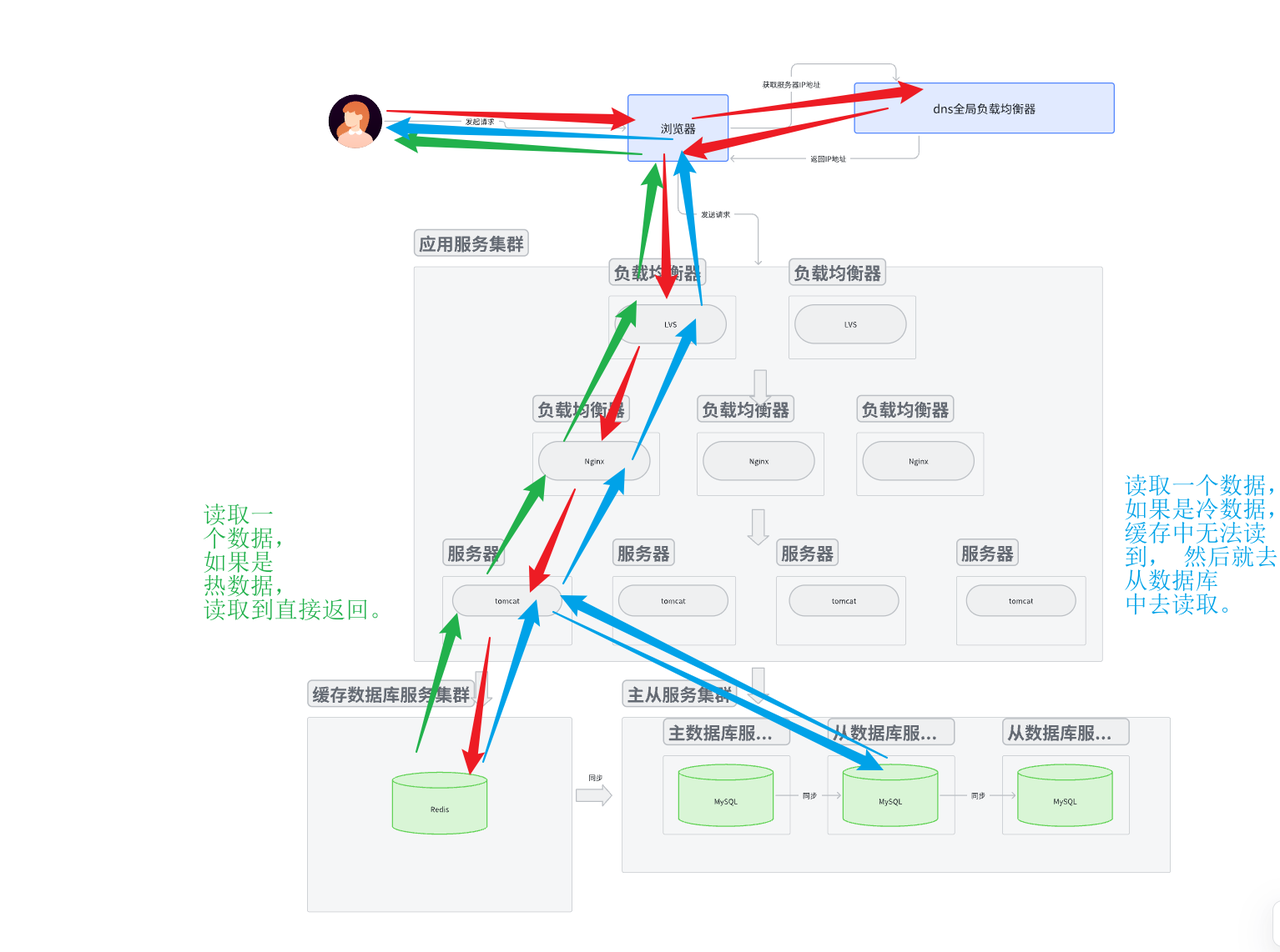
- 发送请求, dns返回IP地址, 然后路由到应用服务集群, 应用服务集群再一系列分发处理将请求送到应用服务器。
- 当解析后, 如果是读数据, 那么就看一下缓存服务器中是否有这个数据, 如果有直接返回。
- 如果没有找到对应的数据, 就要去主从数据库集群中去读取数据。
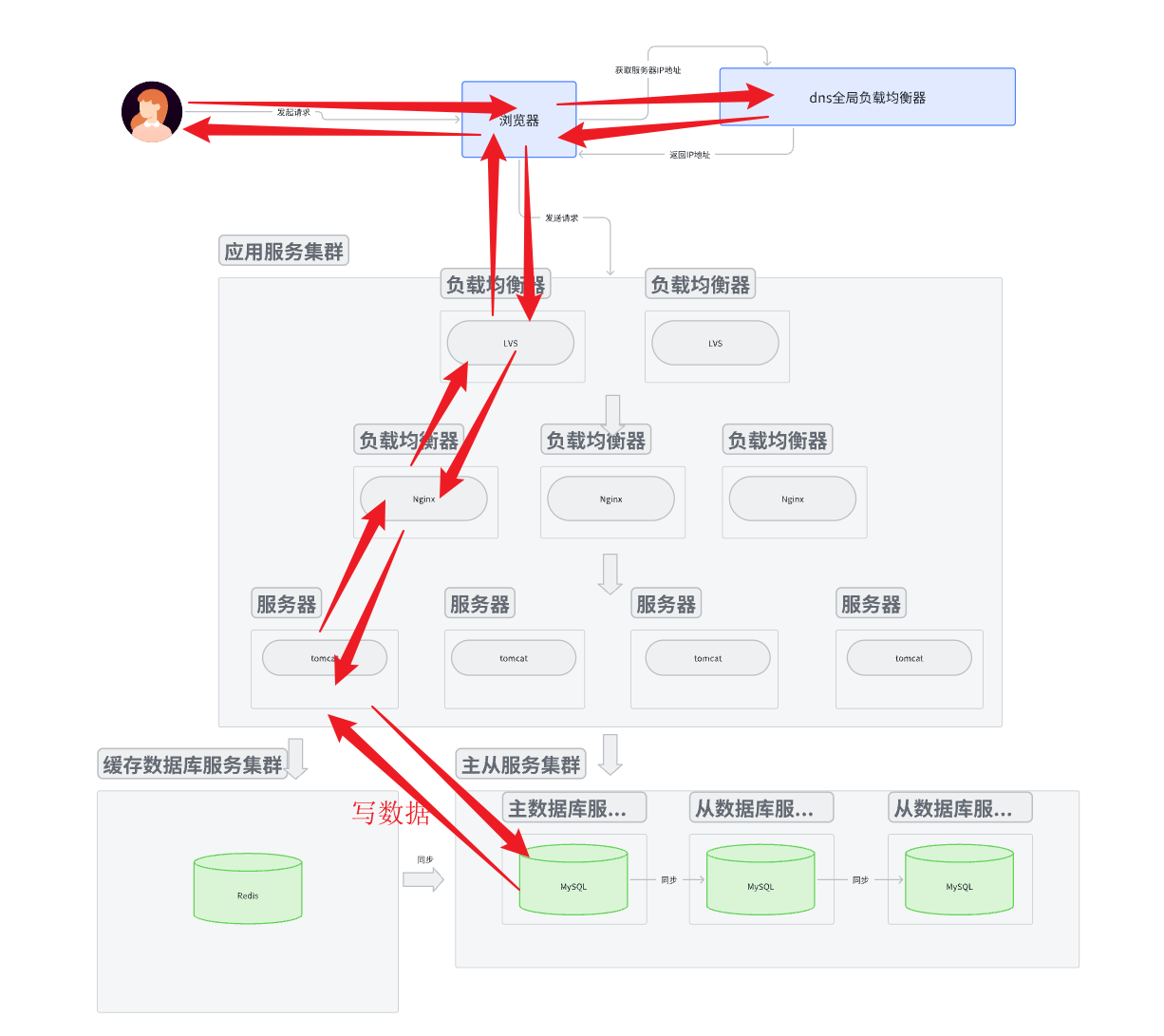
写数据
- 写入数据时是否写入到缓存数据中还是写入到主数据库中根据业务场景决定, 一般情况下直接写入到主数据库。
- 写入到主数据库后, 主数据库有两种策略: 一种是直接同步到缓存数据库, 一种是给缓存数据库发送一个数据失效标记。 第一种的优点是高一致性, 但是高延迟。 第二种的优点是低延迟, 但是最终一致性(允许数据短暂不一致)

















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









