



一、Python基础入门
1、语句分隔符
①如Java语言一样,Python也有同样的语句分隔符号“;”。用于分隔不同的语句。但以上写法不推崇,并不符合编码的实际规范。举个栗子如下:
print("Welcome to Python!");print("Hello World!");其输出结果为:
Welcome to Python!
Hello World!这里就有小朋友问了,为什么这里用的是print并不是println为什么也会进行换行呢?这里如下到转义符的“end”这里有解释,源码是在后面默认带了"\n"。
②在Python中,通常采取换行来分隔语句。通常Python语法中采用此种模式。举个栗子如下:
print("Welcome to Python!")
print("Hello World!")其输出结果也为:
Welcome to Python!
Hello World!2、语句注释
①、单行注释,在Python中,单行注释以#号开头,用空格分隔一个字符。
# 导入一个random模块,获取随机数
import random
# 获取1-100随机数
print(random.randint(1, 100))②、多行注释,在Python中,多行注释以"""内容"""分隔多行注释内容。
# 导入时间模块
import datetime
"""
这是一个多行注释
"""
print(datetime.date.today())注释并不会输出,只是用于解释,方便我们对该语句进行注释,便于后续的理解。
3、输入输出函数
# 输出函数
print("Hello World!")
# 输入函数
name = input()
age = input()
print(f"姓名:{name} 年龄:{age} ")输出默认情况下会直接打印在控制台中,因此在输出结果中会优先从上到下输出内容。到输入时即input()会停止等待用户进行输入。待用户输入完成之后便会进行下一步的操作。假设,我们在这输入的name值为“zhangsan”,age值为25,那么其输出结果为:
Hello World!
zhangsan
25
姓名:zhangsan 年龄:25 4、变量
①在 Python 中,无需声明变量的类型,直接给变量名赋值就完成了变量的定义。其基本语法格式如下:
# 这里定义了一个变量x,一个y,并对它们分别进行赋值
x = 1
y = 2
print(x + y)
# 这里重新将变量x赋予新值
x = 2
print(x)其输出结果为:
3
2②变量类型有很多,常见的变量类型有 :
| 整数(int) | 用于表示整数,如 age = 25。 |
| 浮点数(float) | 用于表示小数,如 height = 1.75。 |
| 字符串(string) | 用于表示文本,如 name = "Alice"。 |
| 布尔值(bool) | 只有两个值,True 或 False,如 is_student = True。 |
| 列表(list) | 用于存储多个元素,元素可以是不同类型,如 numbers = [1, 2, 3]。 |
| 元组(tuple) | 类似于列表,但元素不可修改,如 point = (1, 2)。 |
| 字典(dict) | 用于存储键值对,如 person = {"name": "Alice", "age": 25}。 |
5、转义符
在Python中和众多语言如Java中的转义符一样,是用"\"(反斜杠)。其作用是将某些普通符号给予特殊的功能或将一些特殊功能的符号普通化。
# \'用于表示单引号,输出结果应该是'I am Tristan'
print("\'I am Tristan\'")
# \"用于表示双引号,输出结果应该是"I am Tristan"
print("\"I am Tristan\"")
# \\用于表示反斜杠,输出结果应该是\I am Tristan\
print("\\I am Tristan\\")
"""
\n用于表示换行的操作,输出的结果应该是
I am Tristan
I am a Test Engineer
"""
print("I am Tristan\nI am a Test Engineer")
# \t表示制表符
print("姓名\t年龄\t城市")
print("张三\t25\t上海")
# \r用于表示回车的操作,输出的结果应该是I am a Test Engineer
print("I am Tristan\rI am a Test Engineer")其输出结果为:
'I am Tristan'
"I am Tristan"
\I am Tristan\
I am Tristan
I am a Test Engineer
姓名 年龄 城市
张三 25 上海
I am a Test Engineer 在上述会发现一个很有意思的现象,我们在使用/r的时候会发现,后面那句话把前面的语句给覆盖了。这是由于 \r 这个转义字符的特性导致的。在 Python 里,\r 代表回车符,其作用是把光标移到当前行的起始位置。
如果需要详细看“/r”的功能情况,我们可以这样操作首先输出 "I am Tristan",然后使用 time.sleep(2) 暂停2秒,让你有时间看到初始输出内容。之后输出 \r 回车符将光标移到行首,再输出 "I am a Test Engineer" 覆盖之前的内容。
import time
print("I am Tristan", end="", flush=True)
time.sleep(2)
print("\rI am a Test Engineer")这里的end=""含义如下:在 Python 里,
\n,也就是每次调用end参数的作用是指定在输出内容末尾添加的字符串,当你将end参数设置为空字符串""时,就表示在输出内容末尾不添加换行符。
flush=True的含义和作用:在 Python 中,
flush参数用于控制是否立即将缓冲区中的内容刷新到屏幕上。当flush=True时,会强制将缓冲区中的内容立即输出。
②转义类型有很多,常见的转义类型有 :
| \' | 表示单引号 |
| \" | 表示双引号 |
| \\ | 表示反斜杠 |
| \n | 表示换行符 |
| \t | 表示制表符 |
| \r | 表示回车符 |
6、格式化输出
①字符串的格式化输出有两种方式,一种为利用占位符的方式,类似于C++。举个栗子如下:
name = "Tristan"
age = 24
height = 169
# 通过站位方式来格式化输出字符串
print("My name is %s, My age is %d, My height is %d." % (name, age, height))②第二种方式为通过format来格式化输出字符串。举个栗子如下:
name = "Tristan"
age = 24
height = 169
# 通过format来格式化输出字符串
print(f"My name is {name}, My age is {age}, My height is {height}.")它们的输出结果都为:
My name is Tristan, My age is 24, My height is 169.7、字符串序列操作
①字符串索引操作,对字符串进行查询字符的操作。众所周知,下标是从0开始的,也就是第一位下标为0。但是!Python中有特有的索引机制,即-1下标代表着最后一位。举个栗子如下:
s = "Welcome to Python!"
# 1、索引操作,查询字符
# 查询第一位
print(s[0])
print(s[1])
print(s[4])
print(s[7])
# 查询最后一位(手动数的)
print(s[17])
# 查询最后一位(通过-1下标)
print(s[-1])
# 查询倒数第二位
print(s[-2])其输出的结果为:
W
e
o
!
!
n②字符串切片操作,通过开始索引和结束索引。其和Golang语言的切片很像,都是左包含右不包含。就比如[0,2]就代表下标第零位置到下标第一位。举个栗子如下:
s = "Welcome to Python!"
# 2、通过切片操作索引
# 取第一位到第七位
print(s[0:7])
# 取第一位到倒数第二位(倒数第一位不包含)
print(s[0:-1])其输出的结果为:
Welcome
Welcome to Python这里我们就发现一个问题了,“!”哪里去了!!!哦对了,因为之前提到了左包含又不包含。既然左包含右不包含,那-1下标不就没用了么?此时我们可以不填如下标,如下:
s = "Welcome to Python!"
# 2、通过切片操作索引
# 取第一位到最后一位
print(s[0:])其输出的结果为:
Welcome to Python!还有一种索引方式,"s[0,7,2]"代表的是从第一位到第七位,隔一个取一次,举个栗子如下:
s = "Welcome to Python!"
# 2、通过切片操作索引
# 取第一位到第七位,隔一位取一个
print(s[0:7:2])其输出的结果为:
Wloe除此之外,还存在着逆序输出的操作,举个栗子如下:
s = "Welcome to Python!"
# 2、通过切片操作索引
# 逆序输出内容
print(s[::-1])其输出的结果为:
!nohtyP ot emocleW8、字符串的操作方法
通常,不同的数据类型都有不同的一些内置的操作方法。如字符串就存在以下这些操作方法。这里举例一些常见的栗子来说明。
①计算字符串长度,用于表示字符的长度
s = "Hello World!"
print(len(s))其输出的结果为:
12②判断某个成员是否存在
s1 = "There are too many students"
print("student" in s1)
print("students" in s1)其输出的结果为:
True
True③大小写的转换
s = "Hello World!"
# 大小写的转换
print(s.upper())
print(s.lower())其输出的结果为:
HELLO WORLD!
hello world!④判断字符串的开头或结尾
s = "Hello World!"
# 判断字符串的开头或结尾
print(s.startswith("Hello"))
print(s.endswith("!"))其输出的结果为:
True
True⑤替换对应字符串,需要注意的是,替换并不会将原有的字符串“s”发生相应的更改。底层其实是复制了一个“s”字符串并将其中的值进行赋值更改。
s = "Hello World!"
# 替换相应字符串
print(s.replace("World", "Python"))其输出的结果为:
Hello Python!⑥统计指定字符串出现的次数,这里我们以字母“l”为栗
s = "Hello World!"
# 统计指定字符串出现的次数
print(s.count("l"))其输出的结果为:
3⑦用某字符进行字符串的分隔,默认按空格进行分隔。其会将分隔出来的字符串存入List集合中。
s1 = "上海-北京-深圳"
# 用某字符进行字符串的分隔,默认按空格进行分隔
print(s1.split("-"))其输出的结果为:
['上海', '北京', '深圳']⑧将多个字符串拼接在一起,和上述操作是相反的。
s2 = ["北京", "上海", "深圳"]
# 用某字符进行字符串的分隔,默认按空格进行分隔
print("-".join(s2))其返回的结果为:
上海-北京-深圳⑨用于寻找指定的字符串,如果没有结果就会返回-1
s = "Hello World!"
# 用于寻找指定的字符串,如果没有结果就会返回-1
print(s.find("Hello"))
print(s.find("hello"))其返回的结果为:
0
-1⑩用于寻找指定字符串的下标位置,没有找到就会报错。注意!这里是从0开始计算的。
s = "Hello World!"
# 用于寻找指定字符串的下标位置,没有就会报错
print(s.index("Hello"))其返回的结果为:
0⑩①判断是否为全数字
s = "Hello World!"
# 判断是否为全数字
print(s.isdigit())其返回的结果为:
False⑩②去两边空格
s3 = " 前面有三个空格,后面有两个空格 "
print(s3.strip())其输出的结果为:
前面有三个空格,后面有两个空格以上就是常用的字符串的一些内置方法,其并不是特别完善。因此,如还有需要可以查询相应的官方文档。
9、运算符
①计算运算符,包含加、减、乘、除、取余
# 计算运算符
# 加法运算符+
a = 1 + 2
# 减法运算符-
b = 2 - 1
# 乘法运算符*
c = 2 * 2
# 除法运算符/
d = 4 / 2
# 取余运算符%
e = 5 % 2
print(a, b, c, d, e)其输出的结果为:
3 1 4 2.0 1②比较运算符,包含大于、小于、大于或等于、小于或等于、相等、不相等
# 比较运算符
# 大于运算符
a1 = 2 > 1
# 小于运算符
b1 = 2 < 1
# 大于或等于运算符
c1 = 2 >= 1
# 小于或等于运算符
d1 = 2 <= 1
# 等于运算符
e1 = 1 == 1
# 不等于运算符
f1 = 2 != 1
print(a1, b1, c1, d1, e1, f1)其输出的结果为:
True False True False True True③赋值运算符,包含等于、赋值加、赋值减、赋值乘、赋值除、赋值取余
# 赋值运算符
# 等于
a2 = 2
print(a2)
# 赋值加
a2 += 2
print(a2)
# 赋值减
a2 -= 1
print(a2)
# 赋值乘
a2 *= 2
print(a2)
# 赋值除
a2 /= 1
print(a2)
# 赋值取余
a2 %= 2
print(a2)其输出的结果为:
2
4
3
6
6.0
0.0④逻辑运算符,包含and、or、not
# 逻辑运算符
a3 = 2
# and和
if a3 > 1 and a3 == 2:
print("true")
# and或
if a3 < 1 or a3 == 2:
print("true")
# not取反
if not (a3 < 1):
print("true")
其输出的结果为:
true
true
true⑤成员运算符
# 成员运算符
a4 = 2
# 存在
if a4 in [1, 2, 3]:
print("true")其输出的结果为:
true二、Python逻辑语句
1、分支语句
①双分支语句,存在着两条分支。根据条件进行判断走不同的分支。这边就以一个成年判断的简单代码举个栗子说明:
age = int(input("请输入您的年龄:"))
# 双分支语句
if age >= 18:
print("恭喜您,您现在是baby一个!")
else:
print("恭喜您,您还是小登一个~")这里就可以根据不同的结果来判断走的哪条分支了。例如这里输入一个年龄为22的,其输出结果为:
请输入您的年龄:22
恭喜您,您变成老baby了!
2、多分支语句,存在多条分支。根据条件进行判断走不同的分支。这里继续拿if条件语句举例,只不过就是多了不同条件执行不同的分支而已。这里继续举个栗子:
age = int(input("请输入您的年龄:"))
# 双分支语句
if age >= 18:
print("恭喜您,您现在是baby一个!")
print("您现在可以游玩18+游戏了!")
elif 13 < age < 18:
print("恭喜您,您还是小登一个~")
print("但是你可以玩13+的游戏了~")
elif 8 < age < 13:
print("恭喜您,您还是小小登一个~")
print("但是你只可以玩8+的游戏...")
else:
print("小屁孩要好好学习,不许玩游戏!")这里同样也可以根据不同的结果来判断走的哪条分支了。例如这里输入一个年龄为17的,其输出结果为:
恭喜您,您还是小登一个~
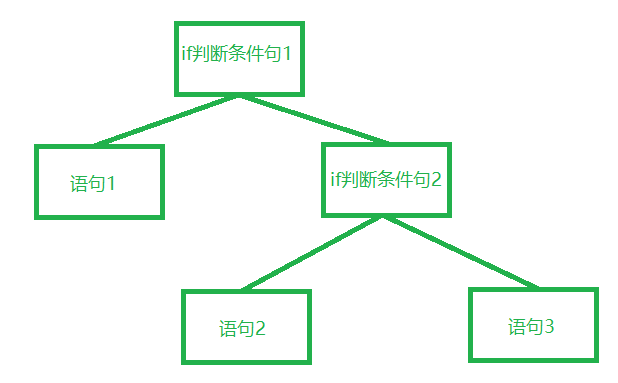
但是你可以玩13+的游戏了~③分支嵌套语句,也就是在分支里面又嵌套了一个分支进行再次判断。这里就不再举例子赘述了。画一个图便于大家理解。但需要注意的是,一定要注意缩进!!!Python对于缩进是十分敏感的!否则就会报错!
2、循环语句
循环语句分为很多种,例如常用到的while循环,for循环等。Java或者C#中甚至还有独特的如增强for循环用于遍历对象等。Python这里只介绍while循环以及for循环。
①while循环,用于利用条件里的布尔值进行循环执行,只要里面是True,循环体就会持续运行。这里同样举几个栗子来形象说明~
classNum = 8
# 进行判断条件来循环内容,注意while中是判断的布尔值
while classNum != 0:
print(f"还有{classNum}节课!")这里运行之后,因为classNum一直是8,在while语句中判断的结果一直是True(即classNum一直不是0),因此一直循环其中的循环体。
这里我们加上一个条件来看看,当结果为False之后会不会停止。这里利用运算符中的内容自减来举个栗子:
classNum = 8
# 进行判断条件来循环内容,注意while中是判断的布尔值
while classNum != 0:
print(f"还有{classNum}节课!")
classNum -= 1其输出的结果为:
还有8节课!
还有7节课!
还有6节课!
还有5节课!
还有4节课!
还有3节课!
还有2节课!
还有1节课!②for循环,for循环更适合对可迭代对象进行遍历的场景。在实际编程中,要依据具体需求来选择合适的循环结构。
# for循环,range10代表循环十次,每次循环的值都会赋予给i
for i in range(10):
print(i)其输出的结果为:
0
1
2
3
4
5
6
7
8
9
注意,上面是从0开始的,for i in range(10)可以理解为Java中的for(int i = 0; i < 10; i++),如果有其他语言的基础就不难理解了。
在这几种循环中难道我们一定要等到开始设定的条件满足后才会停止循环吗?答案肯定是否定的。这里我们有两种退出机制,一种是break,一种是continue。下面我们来具体介绍一下这两种机制的使用方法。
③break退出整个循环,什么意思呢,顾名思义就是当遇到break语句,系统就退出当前的整个循环,不再循环当前的循环体。下面举个具体的栗子来说明一下。
# for循环,range10代表循环十次,每次循环的值都会赋予给i
for i in range(10):
if i == 5:
break
else
print(i)我们设定一个条件在此循环中,当 i 自增到等于 5 的时候,我们使用break结束整个循环。可以看到其输出的结果为:
0
1
2
3
4④continue退出当前循环,这下我们就不难理解了,结合上述的栗子那不就是当 i = 5 的时候跳过当前循环不输出吗?下面我们来看下具体输出的结果:
0
1
2
3
4
6
7
8
9我们可以看到确实跳过了条件规定的循环,但是循环还是会保持到满足条件位置。这便是两个不同退出循环机制的使用场景,大家可以灵活使用。
三、Python操作文件
1、操作文件
文本模式下,Python的文件打开模式有三种分别为:r-只读模式;w-创建模式,若文件已存在,则覆盖旧文件;a-追加模式,新数据会写到文件末尾。
其使用方法大致如下:
f = open(filename) # 打开文件
f.write("I am Tristan") # 写操作
f.read() # 读操作
f.close() # 保存并关闭
不过有一点跟我们平常操作word文档不同,就是word文档只要打开了,就既可以读、又可以修改。其状态只能以读、创建、追加3种模式中的任意一种打开文件,不能即写又读。
下面我们着重介绍几个常用的模式:
假设我们当前目录下存在了一个文件,我们将其命名为"name_list"。
f = open("name_list.txt", mode="w")
f.write("张三\n")
f.write("李四\n")
f.write("王五\n")
f.write("赵六\n")
f.close()这样我们就把这些内容写进了name_list的文件之中。那么我们该如何读呢?因为Python的读写机制我们只能再单独创建一个读的文件
f = open("name_list.txt", mode="r")
print(f.read())这样我们一运行,就可以看到输出结果存在我们刚刚写进去的数据了:
张三
李四
王五
赵六
如果我们需要追加的话同样需要新建一个新的文件,将模式改为 ”a“ 就可以对文件进行追加了。需注意!如果模式还是w的话,写的文件会进行覆盖!
对文件的操作还要很多这里大致介绍一下功能,详细就不赘述了。有需要可以查阅其他人的资料具体看看相应的操作~
# 返回文件·打开的模式
def mode(self)-> str:
# 返回文件名
def name(self)-> str:
# 返回文件句柄在内核中的索引值,以后做IO多路复用时可以用到
def fileno(self,*args,**kwargs):
# 把文件从内存buffer里强制刷新到硬盘
def flush(self, *args, **kwargs):
# 判断是否可读
def readable(self, *args, **kwargs):
# 只读一行,遇到\r or \n为止
def readline(self, *args, **kwargs):
# 把操作文件的光标移到指定位置
# *注意seek的长度是按字节算的,字符编码存每个字符所占的字节长度不一样
def seek(self, *args, **kwargs):
# 判断文件是否可进行seek操作def seekable(self, *args, **kwargs):
# 返回当前文件操作光标位置def tell(self, *args, **kwargs):
# 按指定长度截断文件
# *指定长度的话,就从文件开头开始截断指定长度,不指定长度的话,就从当前位置到文件尾部的内容全去掉
def truncate(self, *args, **kwargs):
# 判断文件是否可写
def writable(self, *args, **kwargs):
2、修改文件
这里拿上述功能做一个实例解释。例如我们要对文件中的一些内容进行替换那怎么操作呢?
思路上我们是应该先打开一个文件然后在将mode设置为"r+",也就是mode="r+"。然后我们再将其加载到内存之中,进行一些相应的操作如替换等操作。然后我们再利用.seek方法将光标移动到开始的位置再进行.truncate方法截断的操作将数据清空。最好我们再把新内容重新写回硬盘进行关闭保存就行。以下就是代码的示例说明:
# 打开文件student_list,模式为r+
f = open("student_list", mode="r+")
# 加载到内存中
data = f.read()
# 进行替换的操作并将值重新赋值给new_data
new_data = data.replace("张三","王二麻子")
# 利用seek方法将光标移动到开始
f.seek(0)
# 利用截断方法清空表
f.truncate()
# 将内存中的内容重新写回硬盘中
f.write(new_data)
# 关闭流
f.close()其余修改的操作也可以参照如上方法进行,这是一个常用的方法。
3、文件的循环
我们怎么样对文件里的内容去循环遍历呢?我们在Python中也可以使用for循环去循环遍历文件中的内容,操作方法也有很多。有点类似于Java中的增强for循环。这里我们拿之前那个文件做个演示说明一下:
# -*- coding: gbk -*-
# 打开文件,设置为读模式
f = open("name_list.txt", mode="r")
# 使用for循环遍历文件
for line in f:
print(line, end="")这里需要解释几个地方:
第一个解释开头的编码格式说明。因为我这边的 “name_list.txt” 文件是GBK编码格式的,因此在读的时候可能会报错,需要声明为GBK格式。那么如果我需要处理图片、视频格式的文件呢?我们可以采二进制模式打开文件。只需要在open括号中加入相应的编码格式encoding="rb/wb/ab"就行。分别代表只读、创建、追加模式。
用第二个解释结尾加上了end=""是因为如果不加,系统会默认换行出现两行直接空了一行的问题。综上代码就可以成功遍历该文件了,不过是以“行”为单位进行遍历。其输出的结果如下:
张三
李四
王五
赵六我们还有个常见的操作就是通过split分隔函数来对我们遍历读取的行,进行存入为集合的操作。假设我们有这样一张表,数据按空格进行分隔
1 张三 江西省萍乡市 175cm 80kg 15979462258 2 李四 江西省九江市 168cm 56kg 19101542237 3 王五 上海市 180cm 96kg 13705672207
那么我们进行如下操作就可以将他分隔成集合:
# -*- coding: gbk -*-
# 打开文件,设置为读模式
f = open("student_list.txt", mode="r")
# 使用for循环遍历文件
for line in f:
line = line.split()
print(line)神奇的事情发生了,其输出的结果为:
['1', '张三', '江西省萍乡市', '175cm', '80kg', '15979462258']
['2', '李四', '江西省九江市', '168cm', '56kg', '19101542237']
['3', '王五', '上海市', '180cm', '96kg', '13705672207']这就是对文件进行遍历时,比较常见的操作之一。
四、函数编程
函数是一种应用在各个语言里面都经常涉及到的内容。函数能够让你把一段经常使用的代码封装起来,之后在程序的不同位置多次调用,避免了重复编写相同代码的麻烦。
1、函数的定义
①函数的定义,这里我们举一个示例代码
# 定义一个名称为add_Numbers的函数,用途是两数之间的累加
def add_numbers(x, y):
return x + y
# 简单的测试
a = 3
b = 5
result = add_numbers(a, b)
if result == 8:
print("测试通过")
else:
print("测试失败")
其输出的结果为:
测试通过这里面有几个知识点,这里简单介绍一下:
第一个介绍在PEP 8规范中明确指出,在类或者函数定义之后,应当有 2 个空行,因此可见代码里发现了 2 个空行。
第二个就是函数里面的参数,包含形参、实参、默认参数,下面介绍一下这几种参数
2、什么是形参、实参以及默认参数
那么什么是形参、什么是实参以及什么是默认参数呢?继续拿上面的这个代码举例,实参就是实际我们要传入的参数。例如 result = add_numbers(a, b)这里的 a 和 b 就是实参。也就是分别是 3 和 5 。而 def add_numbers(x, y) 这里的 x 和 y 就是形参,也就是形式上表示的参数,要求我们按这种参数的类型或者格式去传入参数调用这个函数方法。
那什么又是默认参数?其实很简单。就是在我们未对函数传入相应的实参的时候,我们给予的一个默认的参数。我们给予一个形象一点的栗子说明一下,避免有小笨蛋还是不懂是什么意思。
# 这里定义一个函数名称为student_register的函数名,形参名称有name, age, course以及country
def student_register(name, age, course, country="CN"):
print("------学生信息------")
print("姓名:", name)
print("年龄:", age)
print("课程:", course)
print("国籍:", country)
student_register("喜羊羊", 22, "Python")
student_register("美羊羊", 19, "Java", country="RS")
student_register("懒羊羊", 27, "Golang")这里我们分别没给 “喜羊羊” 和 “懒羊羊” 赋于国籍的值,而是利用形参中赋予默认值的形式来给予值。因此在不传入相应参数时,如果存在默认值,则会自动赋值相应的默认值。而如果实参传入了相应的参数,如 “美羊羊” ,则会用我们传入的实参给予赋值。因此输出的结果为:
------学生信息------
姓名: 喜羊羊
年龄: 22
课程: Python
国籍: CN
------学生信息------
姓名: 美羊羊
年龄: 19
课程: Java
国籍: RS
------学生信息------
姓名: 懒羊羊
年龄: 27
课程: Golang
国籍: CN但是!有一点需要注意的是,为了避免歧义,我们规定给予了默认值形参要放在括号里的最后面!
3、关键参数与非固定参数
关键参数指的就是赋予了变量名称的参数,也可以理解为指定的参数。拿上面那段代码来理解的话就比如 “student_register("喜羊羊", 22, course="Python")” 其中的course="Python"就属于关键参数。
那什么是非固定参数呢?非固定参数一般就是不确定参数有多少,我们在定义函数方法的时候不将其给写死。从而后续可以进行更为灵活的调用等操作。这边同样举个栗子说明,如在定义函数方法的时候我们这样写 "def student_register(name, age, *args, **kwargs):" 这段代码中的 "*args" 表示的是会把多传入的参数变成一个元组形式,而这里的 "**kwargs" 表示的是会把多传入的参数编程一个字典的形式。这里用代码来给看不懂文字说明的小伙伴一点解释:
# 定义一个方法,含有非固定参数
def student_register(name, age, *args, **kwargs):
print(name, age, args, kwargs)
student_register("张三", 20, "Boy", "15979220000", addr="上海市浦东新区", hometown="江西萍乡")这里输出的结果为:
张三 20 ('Boy', '15979220000') {'addr': '上海市浦东新区', 'hometown': '江西萍乡'}这下是比较常用的一种方式,所以这个一定需要熟知!
4、函数返回值的作用
函数返回值可以将函数内获取的一些值返回给函数外部去使用,这时候我们就要用到关键字 “return” 。这个类似于其他很多语言如Java等。
这里同样举一段代码的栗子来简单说明一下 “return” 的使用
def student_register(name, age, course, country="CN"):
print("------学生信息------")
print("姓名:", name)
print("年龄:", age)
print("课程:", course)
print("国籍:", country)
if age > 18 and country=="CN":
return True
else:
return False
status = student_register("张三", 19, "Python", "CN")
if status:
print("可以学习Python!")
else:
print("不建议学习Python!")其输出的结果为:
------学生信息------
姓名: 张三
年龄: 19
课程: Python
国籍: CN
可以学习Python!这里通过分析代码我们可以得知,我们传入的参数 “age” 是大于 “18” 的同时 “country” 等于"CN"。因此会通过 “return” 返回一个 “True” 。然后我们在外部通过 “status” 接收到这个值并进行一系列的操作。通过这个栗子,我们就了解到了函数返回值的作用了。
5、局部变量与全局变量
那么除了通过 “return” 方式返回值让我们去在外部调用就没有其他方式了吗?答案肯定是否定的,参数调用的方式有很多,我们还可以通过不同变量所在的允许范围在不同地方进行调用。这里我们简述局部变量和全局变量的概念和示例。
name = "我叫张三"
print(name)
# 定义change_name方法
def change_name():
name = "不,在我这里你叫李四!"
print(name)
# 调用change_name()方法
change_name()
# 再次打印name
print(name)其输出的结果为:
我叫张三
不,在我这里你叫李四!
我叫张三这里我们可以发现在外部和 “change_name()” 方法中都含有 “name” 变量,但是我们发现,即便我们在方法中重新对 “name” 变量进行了赋值,仍不影响外部 “name” 变量的值。因此我们发现有内部变量会优先调用内部变量,没有内部变量则调用外部变量~
那有没有办法在内部变量去修改外部变量的值呢?答案肯定是有的。就是需要我们在局部中声明一个全局变量!下面我们来修改上述代码更改一下~
name = "我叫张三"
print(name)
# 定义change_name方法
def change_name():
# 声明一个全局变量
global name
name = "不,在我这里你叫李四!"
print(name)
# 调用change_name()方法
change_name()
# 再次打印name
print(name)其输出的结果为:
我叫张三
不,在我这里你叫李四!
不,在我这里你叫李四!因此我们可以发现,在内部声明一个全局变量,会修改外部变量的值。一般这种情况用的比较少,因为不便于变量的维护,可以在适当场景下进行使用~

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









