




 本文深入解析遗传算法的原理,将其比喻为优化花朵大小的过程,详细介绍了选择、交叉和变异等步骤。参数编码是关键,通过二进制表示参数并进行交叉遗传和变异操作。提供了一个MATLAB实现的完整框架,包括初始化、选择、交叉、变异和筛选等函数,用于寻找函数最大值的问题。最后展示了代码示例和优化过程的可视化。
本文深入解析遗传算法的原理,将其比喻为优化花朵大小的过程,详细介绍了选择、交叉和变异等步骤。参数编码是关键,通过二进制表示参数并进行交叉遗传和变异操作。提供了一个MATLAB实现的完整框架,包括初始化、选择、交叉、变异和筛选等函数,用于寻找函数最大值的问题。最后展示了代码示例和优化过程的可视化。
目录
1,算法原理以及形象解释
2,参数编码
3,算法框架
4,代码 MATLAB
1,算法原理以及形象解释
遗传算法(Genetic Algorithm, GA)是仿生物智能优化算法,是模拟达尔文生物进化论中自然选择,遗传变异,适者生存实现生物进化的优化模型。进化论解释了生物发展过程中,每一代种群在自然选择,遗传变异中不断朝更适应生存的方向发展,这本身就是优化的过程,遗传算法正是基于这一原理。(巴拉巴拉)
通俗来讲,当我们希望种植花朵很大的玫瑰,希望花朵越大越好(“大”这个特征就是优化目标)。首先种植的第一批玫瑰(1.初始化第一个种群),挑选花朵大的玫瑰(2.选择优秀个体),然后利用这批优秀个体进行杂交得到子代(3.遗传交叉),然后还要考虑变异,因为变异也可能产生更优秀子代(4.变异),最后重复以上过程(for i=1:100;,,,,,)。
以上这个优化过程,是人为控制选择,遗传交叉,变异。而遗传算法就是通过计算机来完成选择,遗传,变异,产生下一代种群,这些步骤。
2,参数编码
代码实现分析
你们肯定会疑惑,遗传算法和参数编码有什么关系,不要慌,我们先回顾一下算法实现的核心:
代码实现的核心:
1.能够进行选择,挑选优秀个体
(这个简单,计算每个个体对应目标值,对目标值设定一个最低标准,确定优秀个体)。
2.能够交叉,变异,得到新的子代。(关键)
所以问题的关键就是如何实现交叉和变异。 这里就要用到参数编码.
先分析生物遗传变异的机理,生物遗传杂交的过程就是染色体配对过程。而参数编码就是将参数转换成类染色体的数据,使之能够进行交叉变异。即二进制数据。比如 “01011101” ,八位二进制就表示八条染色体,每条染色体对应的值只有0和1。
二进制数据实现交叉遗传
二进制数据实现交叉遗传:(代码中的一部分注释)
% 对于下面两个父代,x1,x2。将染色体从中间分为两组,相互交叉遗传得到子代 y1,y2。
% x1=01001 11010 交 y1=01001 00100
% x2=10101 00100 叉 y2=10101 11010
二进制数据实现变异:(代码中的一部分注释)
%子代染色体序列中如果发生变异,将导致染色体 1 变为 0 , 0 变为 1 。例如:
% x1=01001 1 1010,当发生变异,10个染色体随机一个染色体产生变异,当第五条染色体变异,则变异后的x1'=01001 0 1010。
当然,变异是需要给定一定概率,变异率pm一般设置为染色体个数的倒数,rand(1)<pm时,发生变异
将参数进行二进制编码
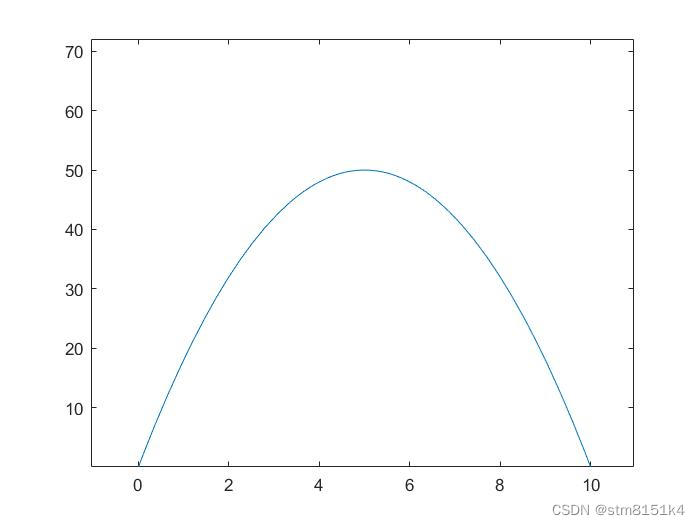
如图所示,为y=-2*x^2+20x,其中x [0,10]。x的值就可以看作我们的方案,y的值就是方案结果。所以参数编码就是对x值进行二进制编码,x的范围是0-10。现在就是思考采用多少个二进制位(根据对精度以及计算量的要求选择),这里选择10个二进制位,,即十个染色体。
若染色体个数为10,则x=0变为p=00000 00000,x=10变为p=11111 11111。
p的值共1024个,0-1023。
对参数进行编码后,就可以进行之后的交叉遗传、变异。
3,算法框架
以搜索最大值为例:
y=7*sin(1*x)+6*cos(4*x)+1.5*x+1 其中 x [0,10]
找到使y最大的x值
① 实现算法之前的准备
1.参数编码:x的范围是0-10,采用10个染色体,这样二进制共1023,精度u=10/1023=0.01。染色体个数用dim表示: dim=10;
2.种群个数:就是一个种群的总个体数: num=20;
3.迭代次数:根据复杂程度选择,这里10次就够了,一般100-200。 gen=10;
4.变异率:一般设置为1/dim。 pm=0.1;
5.交叉率:这里设置的是0.6,60%概率交叉,可以自行尝试。 pc=0.6;
②算法框架
初始化种群 p=init();
迭代开始
for i=a:gen
1.选择优秀个体 p_fit=fittest(p);
2,对原种群进行遗传交叉 son1=crossover(p,pc);,
3。遗传交叉后,进行变异处理 son=mutation(son1,pm);
4.合并子代和父代: son=[p_fit;son];
之前没有讲解这里,其实就是进一步的筛选,将优秀父代和产生的子代合并,挑选出优秀的下一代种群。
5.这里的挑选采用的是锦标赛。就是对合并后的所以个体,随机抽搐两个或多个,选最优个体进入新种群。根据种群个数num=20,进行多轮锦标赛,得到新的种群p。
p=select(son);
end
迭代结束
即可算出最优解。如图所示

4,代码 MATLAB
my_ga.m(主函数)
init.m(初始化函数)
fittest.m(选择优秀父代个体)
crossover.m (交叉遗传)
mutation.m (变异)
select.m (筛选出下一代种群,锦标赛选择法)
plot_ga.m (画图,显示优化过程)
best.m (迭代完成后,显示最优解以及最优方案)
my_ga.m(主函数)
clear
clc
dim=10; % 表示染色体的长度(即维数,二值数的长度),根据编码的长度决定
num=20; % 表示群体的大小,根据问题的复杂程度确定。
gen=10; % 迭代次数 该问题简单,这里只采用10次迭代,根据问题的复杂程度确定。
pm=0.1; % 变异概率,一般 1/dim
pc=0.6; % 交叉概率
p=init(num,dim); % 初始化种群
for i=1:gen
p_fit=fittest(p); % 在种群中选择优秀个体 p_fit
son1=crossover(p,pc); % 在种群中进行遗传交叉得到子代 半成品
son=mutation(son1,pm); % 半成品子代还需进行编译才能成为真正子代 son
son=[p_fit;son]; % 将优秀父代和子代合并 ,进行选择
p=select(son); % 采用锦标赛的选择算子,进行适者生存,才生新种群
plot_ga(p) % 画出新种群
end
[p_best,value]=best(p) % 迭代后最终的最优个体
init.m(初始化函数)
%init
% init.m是进行群体的初始化,产生初始种群,num表示群体的大小,dim表示染色体的长度(即维数,二值数的长度),
function pop=init(num,dim)
pop=round(rand(num,dim));
fittest.m(选择优秀父代个体)
% fittest.m
% 1,计算目标值,2.计算对应适应值
% 设定优秀阈值h,小于h不能直接进入下一代种群选择,大于h适应值为目标值,和子代一起进入选择。
% 1,计算目标值,
function p_fit=fittest(p)
x1=zeros([1,20]);
for i=1:20
for j=1:10
x1(i)=x1(i)+2^(10-j)*p(i,j);
end
end
x=x1*10/1023; %2^10-1=1023
p1=7*sin(1*x)+6*cos(4*x)+1.5*x+1; %计算目标值
% 2.计算对应适应值,以及确定优秀个体
h=3;
j=1;
for i=1:20
if p1(i)>h
p_fit(j,:)=p(i,:);
j=j+1;
end
end
crossover.m (交叉遗传)
% 交叉
% 对于下面两个父代,x1,x2。染色体被分为两组,相互交叉得到子代 y1,y2。
% x1=01001 11010 交 y1=01001 00100
% x2=10101 00100 叉 y2=10101 11010
function son=crossover(p,pc)
s=size(p);
son=zeros(size(p));
for i=1:round(s(1)/2-0.5)
if(rand(1)<pc)
cross=round(rand(1)*s(2));
son((i-1)*2+1,:)=[p((i-1)*2+1,1:cross),p(i*2,cross+1:s(2))];
son(i*2,:)=[p(i*2,1:cross),p((i-1)*2+1,cross+1:s(2))];
else
son((i-1)*2+1,:)=p((i-1)*2+1,:);
son(i*2,:)=p(i*2,:);
end
end
mutation.m (变异)
% mu1tation--变异
%子代染色体序列中,可能变异导致 1 变为 0 、 0 变为 1 。
function son=mutation(son1,pm)
s=size(son1);
son=zeros(s);
for i=1:s(1)
son(i,:)=son1(i,:);
if(rand(1)<pm)
multa=round(rand(1)*s(2)+0.5); %产生的变异点在1-10之间
if son(i,multa)==0
son(i,multa)=1;
else
son(i,multa)=0;
end
end
end
end
select.m (筛选出下一代种群,锦标赛选择法)
function p=select(son)
p=zeros([20,10]);
s=size(son);
x1=zeros([1,s(1)]);
for i=1:s(1)
for j=1:10
x1(i)=x1(i)+2^(10-j)*son(i,j);
end
end
x=x1*10/1023; %2^10-1=1023
p_obj1=7*sin(1*x)+6*cos(4*x)+1.5*x+1; %计算目标函数值
p_obj1=p_obj1';
%第一赛季
randidx=randperm(s(1)); %打乱顺序进行锦标赛
son_s1=son(randidx,:); %第一赛季数据
p_s1=p_obj1(randidx,:);
p_obj2=[];
son2=[];
for i=1:round(s(1)/2-0.5)
if p_s1(2*i)>p_s1(2*i-1)
p(i,:)=son_s1(2*i,:);
p_obj2=[p_obj2;p_s1(2*i-1)];
son2=[son2;son_s1(2*i-1,:)];
else
p(i,:)=son_s1(2*i-1,:);
p_obj2=[p_obj2;p_s1(2*i)];
son2=[son2;son_s1(2*i,:)];
end
end
num_x=20-round(s(1)/2-0.5);
s_s2=size(son2);
randidx_s2=randperm(s_s2(1)); %打乱顺序进行锦标赛
son_s2=son2(randidx_s2,:); %第一赛季数据
p_s2=p_obj2(randidx_s2,:);
if num_x>0
d=round(s_s2(1)/num_x-0.5);
for i=1:num_x
[s2_max,s2_x]=max(p_obj2(d*(i-1)+1:d*i));
p(round(s(1)/2-0.5)+i,:)=son_s2(d*(i-1)+s2_x,:);
end
end
plot_ga.m (画图,显示优化过程)
function plot_ga(p)
clf(figure(1))
figure(1)
fplot(@(x)7.*sin(1.*x)+6.*cos(4.*x)+1.5.*x+1,[0 10])
x1=zeros([1,20]);
for i=1:20
for j=1:10
x1(i)=x1(i)+2^(10-j)*p(i,j);
end
end
x=x1*10/1023; %2^10-1=1023
p1=7*sin(1*x)+6*cos(4*x)+1.5*x+1; %计算目标值
hold on
plot(x,p1,'r*')
pause(0.5)
% delete(plot(x,p1,'r*'))
best.m (迭代完成后,显示最优解以及最优方案)
function [p_best,value]=best(p)
x1=zeros([1,20]);
for i=1:20
for j=1:10
x1(i)=x1(i)+2^(10-j)*p(i,j);
end
end
x=x1*10/1023; %2^10-1=1023
p1=7*sin(1*x)+6*cos(4*x)+1.5*x+1; %计算目标值
[value,b]=max(p1);
p_best=p(b,:);

















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









