






本文参考自聚集索引与非聚集索引的总结 以及 姜承尧的《MySQL技术内幕–InnoDB存存储引擎》
MySQL 索引详解
在开始介绍前,我们先整理一下 MySQL 的索引:
聚集索引、非聚集索引(普通索引,组合索引,唯一索引)、倒排索引(用于全文检索,也称全文索引)、哈希索引
其中,聚集索引和非聚集索引的存储结构都是 B+ 树结构,全文检索的倒排索引则主要是一张辅助表。
需要注意的是:B+ 树索引不能找到一个给定键值的具体行,只能找到被查找数据行所在的页,然后数据库通过把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
我们通过看图来理解:
数据表:
| NO | NAME | AGE |
|---|---|---|
| 1 | AA | 24 |
| 2 | AB | 19 |
| 3 | AC | 27 |
| 4 | BB | 36 |
| 5 | BA | 44 |
| 6 | BC | 24 |
| 7 | CC | 19 |
| 8 | CB | 27 |
| 9 | CA | 36 |
| 10 | DD | 19 |
| 11 | DA | 27 |
| 12 | DB | 36 |
聚集索引
聚集索引其实就是主键索引,创建表时指定了主键,就会默认创建一个聚集索引;如果没有指定主键,就会自动创建一个隐藏的列作为表的聚集索引。
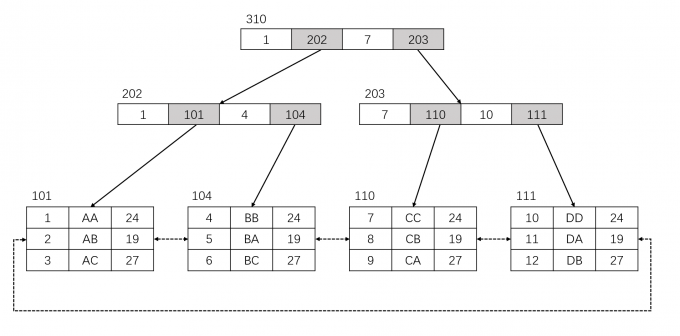
非叶子节点中,有一个 key 和一个指向下一级节点的页地址,其中 key 一般就是主键。叶子节点中,则是一页完整的数据行,相邻叶子之间会有一个指针使之相连。
非聚集索引
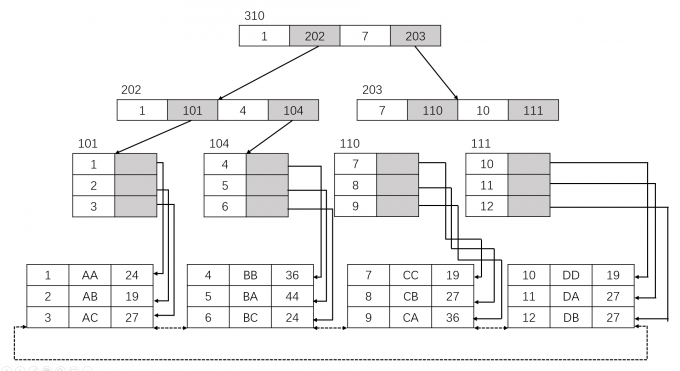
非聚集索引的叶子节点,不会存储整行数据,只会存储一个 key 和一个指向该 key 对应的整行数据。
也就是说,非聚集索引对数据的物理存储结构没有影响。(最下面的数据存放不一定是这个顺序)
非聚集索引分类:
- 普通索引:就是非聚集索引,可以在任意一列上建立。
- 唯一索引:跟普通索引相似,但要求该列的值不重复。
- 组合索引:在多个数据列上建立索引,下面是一个组合索引的示意图,在a,b列上建立了组合索引:
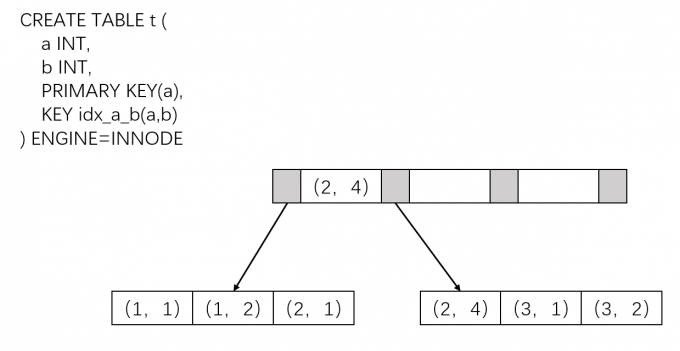
注:以上图为例,进行数据查找时,对 ab 同时选择,或只对 a 进行选择时,会用到上面这个索引,但如果只对 b 进行选择,则不会使用这个组合索引。因为索引中只对 a,ab 进行了排序,没有对 b 进行排序,因此只对 b 进行筛选时无法使用上面的组合索引。(也称为最左前缀)
覆盖索引:从非聚集索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。非聚集索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的 IO 操作。
全文索引
现在我们有如下的数据表 document,并在 Text 列上建立全文索引
CREATE FULLTEXT INDEX idx_text ON document(Text)
数据表:
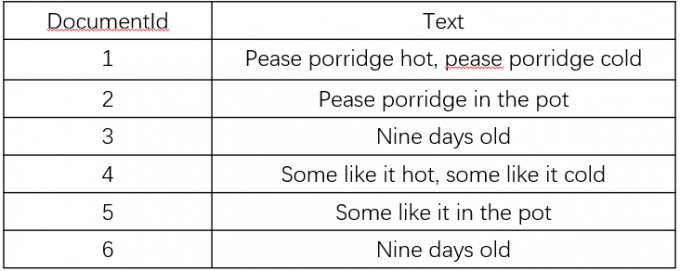
接下来数据库会隐式的建立如下的辅助表,该辅助表存放在磁盘中:
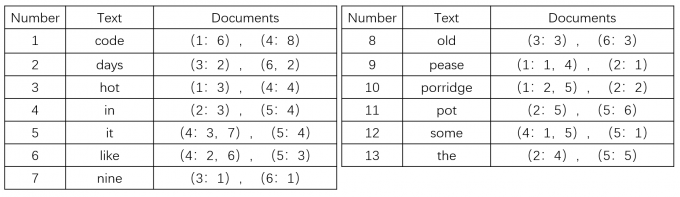
第三列存的是该单词出现的位置,第一个数字是 DocumentId,第二个数字是它在 Text 的第几个单词。
在 InnoDB 存储引擎的全文索引中,还有一个重要概念,即 FTS Index Cache(全文检索索引缓存),它能提高全文检索的速度。
它是一个红黑树结构,其根据(word,ilist)进行排序,ilist就是(DocumentId,Position),即辅助表中的 Documents 的数据对。
哈希索引
哈希索引的相关结构和算法就不详细展开,其中哈希冲突的解决方法是链地址法。由于哈希算法的特性,我们可以知道,对于字典类型的查找使用哈希索引会非常快速,但对于范围查找它就无能为力了。
哈希索引是数据库自身创建并使用的,我们无法对其进行干预,只能通过参数 innodb_adaptive_hash_index 来禁用或者启动开启,默认为开启。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









