




 本文介绍了一个基于LightGBM的租金预测模型。通过分析数据集中的缺失值、特征相关性和分布情况,进行了数据预处理和特征工程,最终实现了五折交叉验证下的良好预测效果。
本文介绍了一个基于LightGBM的租金预测模型。通过分析数据集中的缺失值、特征相关性和分布情况,进行了数据预处理和特征工程,最终实现了五折交叉验证下的良好预测效果。
读取文件
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import KFold
from sklearn.metrics import r2_score
train=pd.read_csv(r'C:\Users\lxc\Desktop\featurecup\train_data.csv')
test=pd.read_csv(r'C:\Users\lxc\Desktop\featurecup\test_a.csv')
data = pd.concat((train,test))
一.缺失值分析
train.isnull().sum().sort_values(ascending=False)
print(list(data['rentType']).count("未知方式"))
print(list(data['houseToward']).count("暂无数据"))
print(list(data['houseDecoration']).count("其他"))
print(list(data['buildYear']).count("暂无信息"))
32944
2136
31021
2936
缺失值分析,很多缺失值是以暂无信息存在的,租的方式,房屋朝向缺失值都很多,pv和uv有少量缺失,其中rentType感觉会对租金影响较大,应该可以根据租金和房价来进行填补,housetoward,housedecoration,buildyear相对难根据已知信息进行填补
二.特征相关性
pd.set_option('max_colwidth',200)
pd.set_option('display.width',200)
pd.set_option('display.max_columns',500)
pd.set_option('display.max_rows',1000)
train.corr()
三.特征nunique分布
1.单一字段变量
单一字段只有city,可以将其去除
x=[]
for col in data.columns:
leght=len(data[col].unique())
if leght==1:
x.append(col)
x
['city']
2.community的不同分布
测试集只有训练集一半的小区名
print(train['communityName'].unique().shape[0])
print(test['communityName'].unique().shape[0])
4236
2469
3.特征值大于100的category变量
i.训练集里面有100个以上不同特征的值
for cols in train.columns:
if train[cols].unique().shape[0]>100 & train[cols].dtype='category'
print(cols)
ID
area
houseType
communityName
totalTradeMoney
totalTradeArea
tradeMeanPrice
tradeSecNum
totalNewTradeMoney
totalNewTradeArea
tradeNewMeanPrice
tradeNewNum
remainNewNum
supplyNewNum
newWorkers
pv
uv
tradeTime
tradeMoney
ii.测试集
for cols in test.columns:
if test[cols].unique().shape[0]>100:
print(cols)
ID
area
communityName
totalTradeMoney
totalTradeArea
tradeMeanPrice
tradeSecNum
totalNewTradeMoney
totalNewTradeArea
tradeNewMeanPrice
tradeNewNum
remainNewNum
newWorkers
pv
uv
tradeTime
其中communityName和housetype为category变量
四.lable分布
#总体分布查看
train.hist(figsize=(50, 15), bins=100, grid=False)
plt.show()
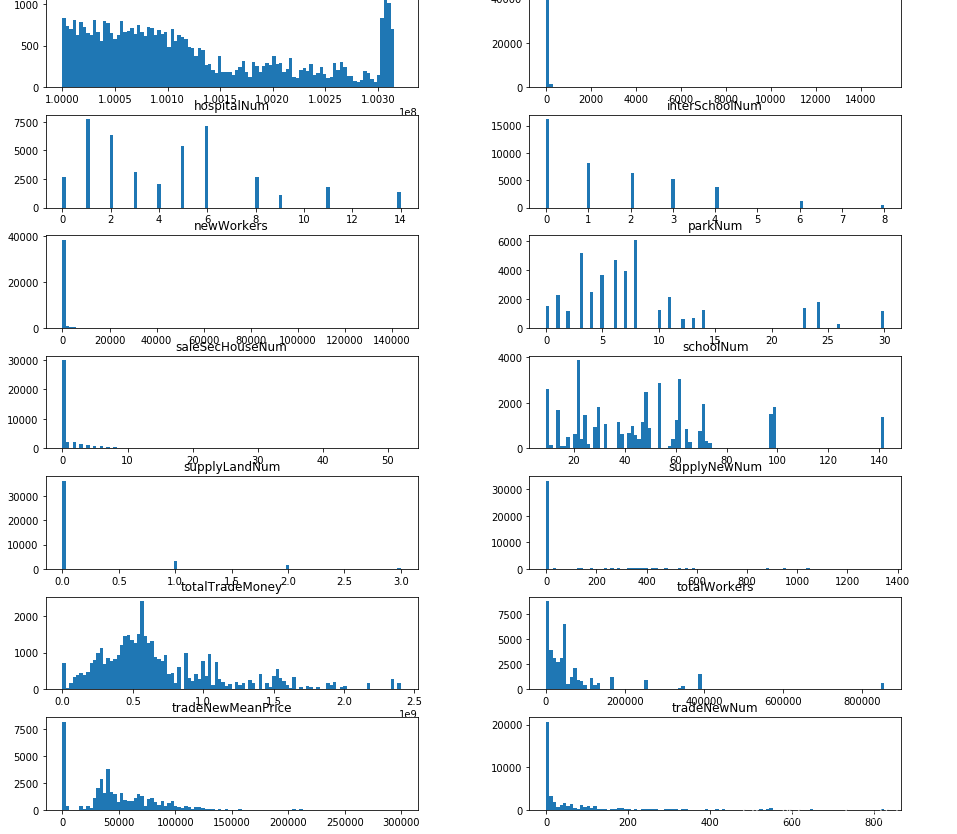
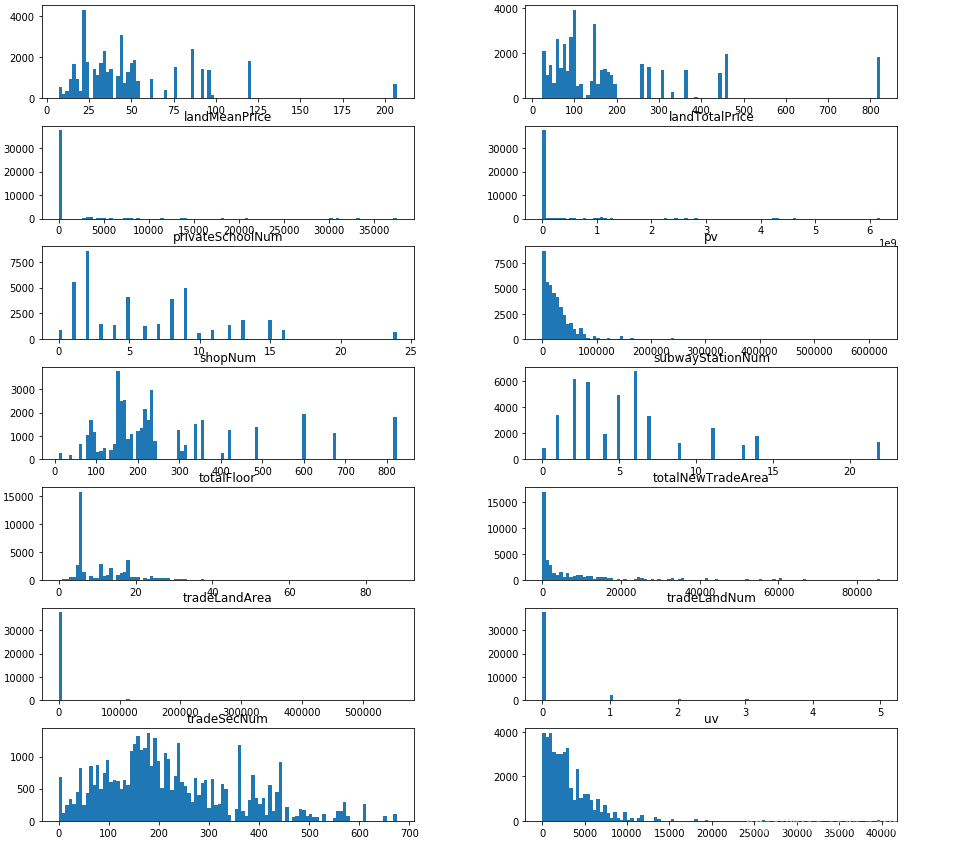
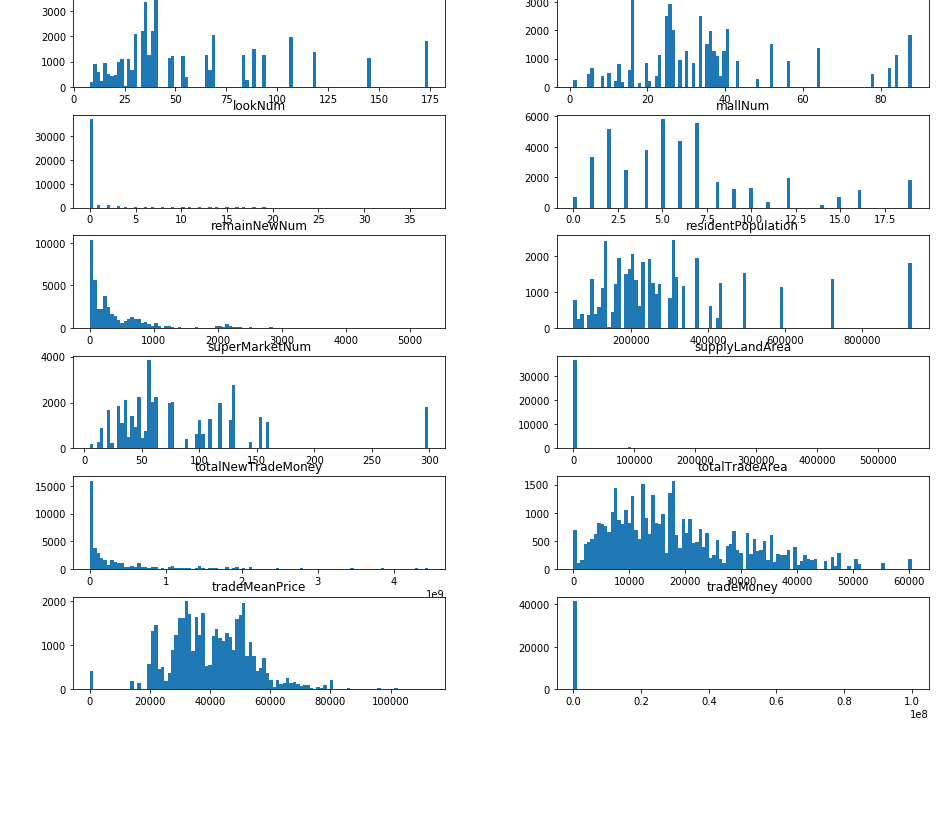
画出比较关键的area和trademoney的关系图
#以area为横轴,trademoney以y轴比对发现了两者均有异常值
sns.regplot(x=train['area'],y=train['tradeMoney'])
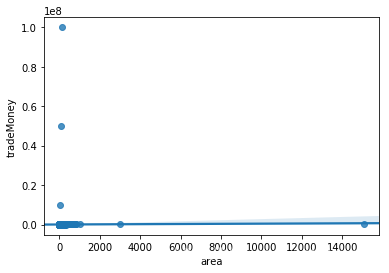
tradeMoney和area均有异常值
去除异常值的价格分布服从正态分布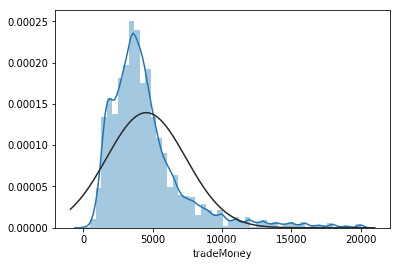
baseline
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import KFold
from sklearn.metrics import r2_score
def parseData(df):
"""
预处理数据
"""
def fix(x):
if x==1:
return "别墅"
elif x>6:
return "高楼"
else:
return "步行房"
df['totalFloor']=df['totalFloor'].map(fix)
df['rentType'][df['rentType']=='--'] = '未知方式'
# 转换object类型数据
columns = ['rentType', 'houseFloor', 'houseToward', 'houseDecoration', 'communityName','region', 'plate','totalFloor']
for col in columns:
df[col] = df[col].astype('category')
# 将buildYear列转换为整型数据
'''
tmp = df['buildYear'].copy()
tmp2 = tmp[tmp!='暂无信息'].astype('int')
tmp[tmp=='暂无信息'] = tmp2.mode().iloc[0]
df['buildYear'] = tmp
df['buildYear'] = df['buildYear'].astype('int')
'''
# 处理pv和uv的空值
df['pv'].fillna(df['pv'].mean(),inplace=True)
df['uv'].fillna(df['uv'].mean(),inplace=True)
df['pv'] = df['pv'].astype('int')
df['uv'] = df['uv'].astype('int')
df.drop(['supplyLandNum','supplyLandArea','tradeLandNum','tradeLandArea','landTotalPrice','landMeanPrice'],axis=1,inplace=True)
# 去掉部分特征
df.drop('city',axis=1,inplace=True)
#df=df.join(pd.get_dummies(df['region']))
#df=df.join(pd.get_dummies(df['totalFloor']))
#df.drop('region',axis=1,inplace=True)
#df.drop('totalFloor',axis=1,inplace=True)
#data=data.join(pd.get_dummies(data['region']))
return df
def washData(df_train, df_test):
"""
清洗数据
"""
df_train = df_train[(df_train['area']<=700)&(df_train['area']>6)]
df_train = df_train[df_train['tradeMoney']<=100000]
df_train.drop('ID', axis=1, inplace=True)
df_test.drop('ID', axis=1,inplace=True)
return df_train, df_test
def feature(df):
"""
特征
"""
# 将houseType转化为‘房间数’,‘厅数’,‘卫生间数’
df['room']=df['houseType'].apply(lambda x: int(x[0:1]))
df['kr']=df['houseType'].apply(lambda x: int(x[2:3]))
df['wc']=df['houseType'].apply(lambda x: int(x[4:5]))
#df['total_num']=df['room']+df['kr']+df['wc']#
#df['room_ration']=df['room']/df['total_num']
#df['kr_ration']=df['kr']/df['total_num']
#df['wc_ration']=df['wc']/df['total_num']
df['交易月份'] = df['tradeTime'].apply(lambda x: int(x.split('/')[1]))
# df['pv/uv'] = df['pv'] / df['uv']
# df['房间总数'] = df['室'] + df['厅'] + df['卫']
df.drop('houseType', axis=1, inplace=True)
df.drop('tradeTime', axis=1, inplace=True)
#df.drop('total_num',axis=1,inplace=True)
categorical_feats = ['rentType', 'houseFloor', 'houseToward', 'houseDecoration', 'plate','region','totalFloor']
return df, categorical_feats
def getData(feature):
"""
获取数据
"""
train=pd.read_csv(r'C:\Users\lxc\Desktop\featurecup\train_data.csv')
test=pd.read_csv(r'C:\Users\lxc\Desktop\featurecup\test_a.csv')
train = parseData(train)
test = parseData(test)
train, test = washData(train, test)
train, col = feature(train)
test, col = feature(test)
target = train.pop('tradeMoney')
features = train.columns
categorical_feats = col
return train, test, target, features, categorical_feats
train, test, target, features, categorical_feats = getData(feature)
params = {
'num_leaves': 31,
'min_data_in_leaf': 20,
'min_child_samples':20,
'objective': 'regression',
'learning_rate': 0.01,
"boosting": "gbdt",
"feature_fraction": 0.8,
"bagging_freq": 1,
"bagging_fraction": 0.85,
"bagging_seed": 23,
"metric": 'rmse',
"lambda_l1": 0.2,
"nthread": 4,
}
folds = KFold(n_splits=5, shuffle=True, random_state=2333)
oof_lgb = np.zeros(len(train))
predictions_lgb = np.zeros(len(test))
feature_importance_df = pd.DataFrame()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train.values, target.values)):
print("fold {}".format(fold_))
trn_data = lgb.Dataset(train.iloc[trn_idx], label=target.iloc[trn_idx], categorical_feature=categorical_feats)
val_data = lgb.Dataset(train.iloc[val_idx], label=target.iloc[val_idx], categorical_feature=categorical_feats)
num_round = 10000
clf = lgb.train(params, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=500, early_stopping_rounds = 300)
oof_lgb[val_idx] = clf.predict(train.iloc[val_idx], num_iteration=clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["feature"] = features
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = fold_ + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
predictions_lgb += clf.predict(test, num_iteration=clf.best_iteration) / folds.n_splits
print("CV Score: {:<8.5f}".format(r2_score(target, oof_lgb)))
CV Score: 0.85629

















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









