






 本文对比了随机森林、GBDT、LightGBM和XGBoost四种机器学习模型在特定数据集上的表现,使用score和AUC两种评估指标进行评分。通过实验发现模型在分类准确率和AUC值上存在显著差异,揭示了类别不平衡对模型性能的影响。同时,利用XGBoost探索了特征的重要性,为后续的特征工程提供了指导。
本文对比了随机森林、GBDT、LightGBM和XGBoost四种机器学习模型在特定数据集上的表现,使用score和AUC两种评估指标进行评分。通过实验发现模型在分类准确率和AUC值上存在显著差异,揭示了类别不平衡对模型性能的影响。同时,利用XGBoost探索了特征的重要性,为后续的特征工程提供了指导。
读取数据集,并对数据集37分
import pandas as pd
data_all=pd.read_csv(r'C:\Users\lxy\Desktop\input\data_all.csv')
from sklearn.model_selection import train_test_split
features=[x for x in data_all.columns if x not in ['status']]
x=data_all[features]
y=data_all['status']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=2018)
随机森林
#score评分
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(oob_score=True, random_state=2018)
rf_model=rf.fit(x_train,y_train)
rf_model.score(x_test,y_test)
0.7708479327259986
#auc评分
rf_pre_test=rf_model.predict(x_test)
rf_auc_auc = roc_auc_score(y_test,rf_pre_test)
rf_auc_auc
0.6028175956934055
GBDT
#score
from sklearn.ensemble import GradientBoostingClassifier
gbdt=GradientBoostingClassifier(random_state=2018)
gbdt_model=gbdt.fit(x_train,y_train)
gbdt_model.score(x_test,y_test)
0.7806587245970568
#auc
gbdt_pre_test=rf_model.predict(x_test)
gbdt_auc_auc = roc_auc_score(y_test,rf_pre_test)
gbdt_auc_auc
0.6028175956934055
lightgbm
import lightgbm as lgb
lgb_model = lgb.LGBMClassifier(boosting_type='gbdt',random_state=2018)
lgb_acc=lgb_model.fit(x_train,y_train)
lgb_acc.score(x_train,y_train)
0.7701471618780659
#auc评分
lgb_pre_test=lgb_acc.predict(x_test)
lgb_auc=roc_auc_score(y_test,lgb_pre_test)
lgb_auc
0.6310118097503468
xgboost
from xgboost.sklearn import XGBClassifier
from sklearn.metrics import precision_score,roc_auc_score
xgbc = XGBClassifier(random_state=2018)
xgbc.fit(x_train,y_train)
xgbc.score(x_test,y_test)
0.7855641205325858
#auc
pre_test = xgbc.predict(x_test)
auc_score = roc_auc_score(y_test,pre_test)
auc_score
0.6431606209508309
利用xgboost对特征初探
from xgboost import plot_importance
import matplotlib.pyplot as plt
fig,ax = plt.subplots(figsize=(15,15))
plot_importance(xgbc,
height=0.5,
ax=ax,
max_num_features=20)
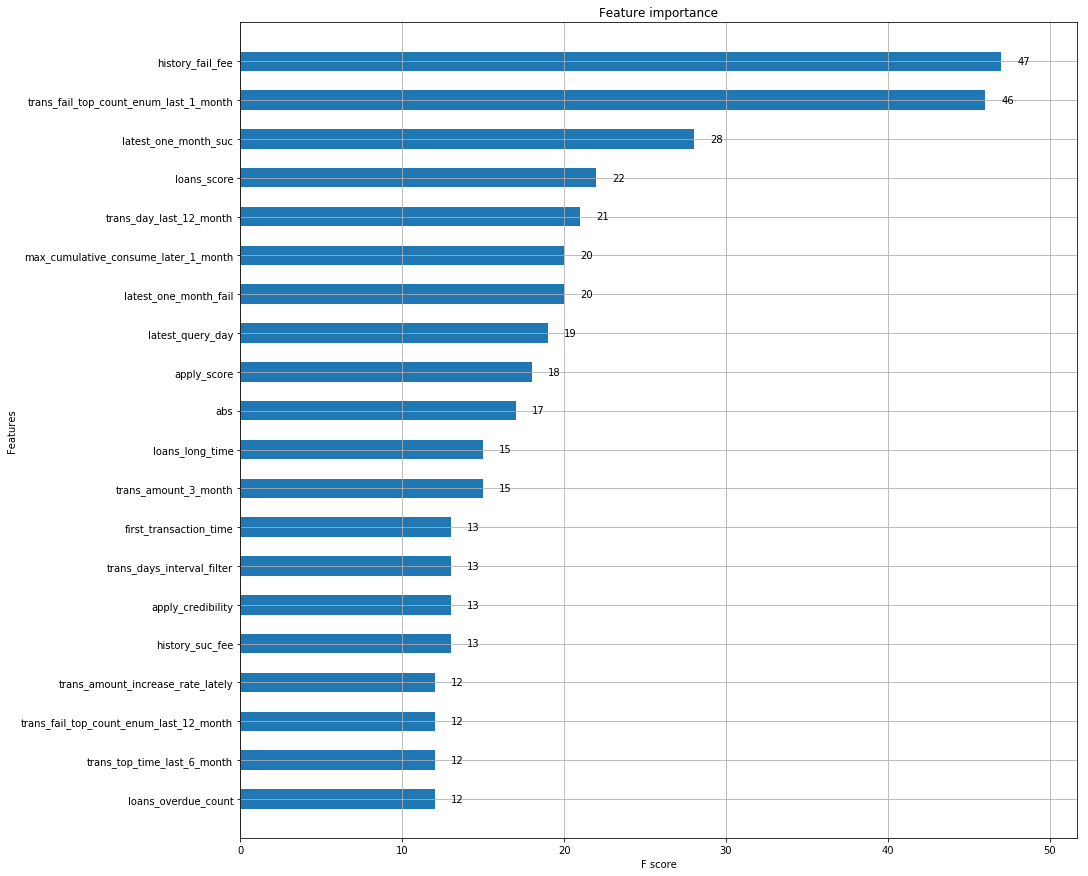
这次我用了两种评分算法,score和auc,发现两者差距蛮大的,此时分类的score算法他的原理是accuracy_score函数。就是分类正确的/分类错误的。而auc的原理在我的一篇博客也写的很清楚,在类别不平衡下他的分更具有参考价值。然后看了一下确实不平衡。最后写了xgboost正好看下特征前20个重要度。为后面特征工程提供一点帮助
random_state控制了每次的随机,保证我们的结果一样方便我们调参

















 2686
2686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









