




目录
1.激活函数
激活函数的想法来自对人脑中神经元工作机理的分析。神经元在某个阈值(也称活化电位)之上会被激活。大多数情况下,激活函数还意在将输出限制在一个小的范围内。
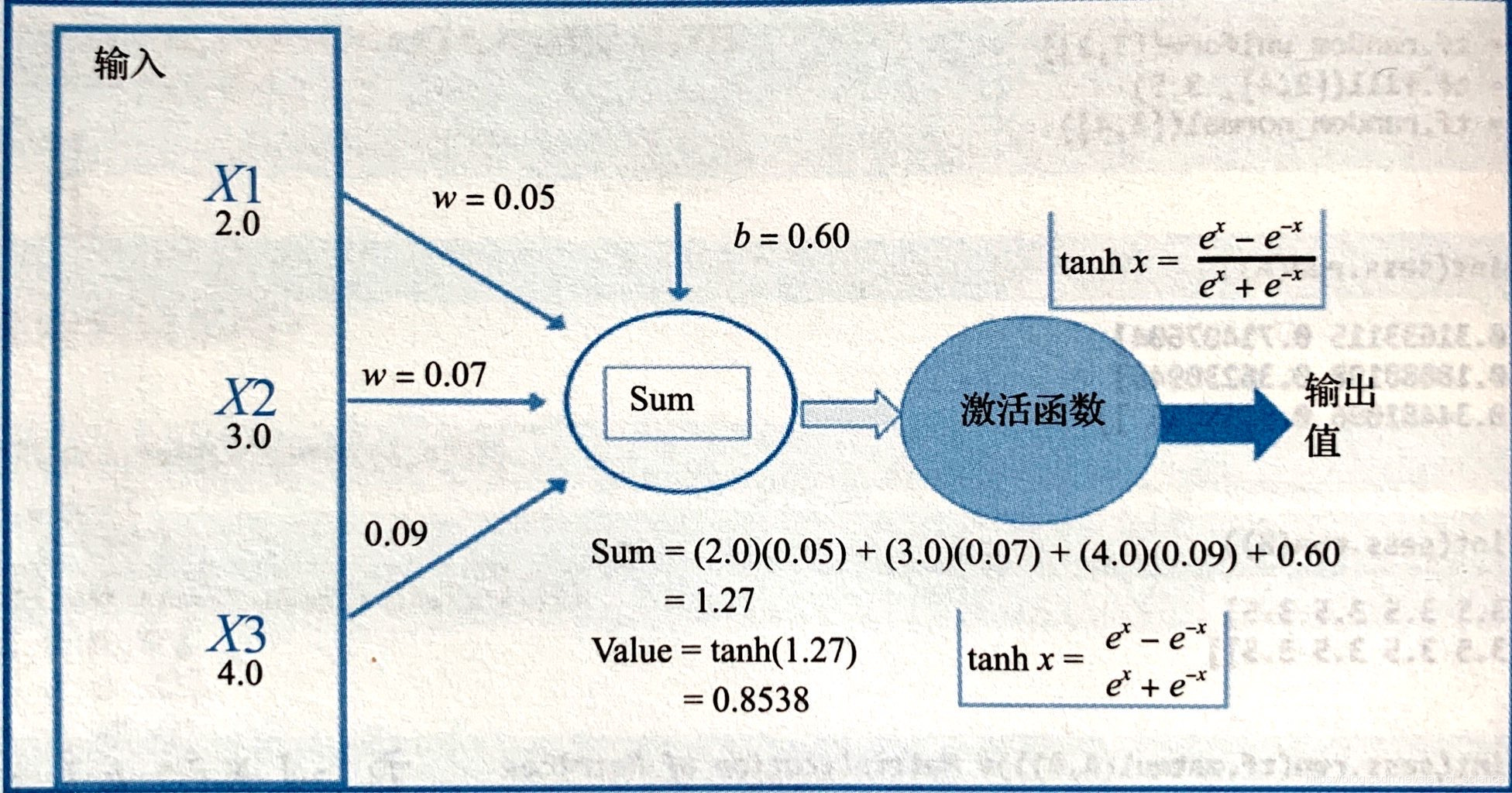
1.1双曲正切函数与Sigmoid函数
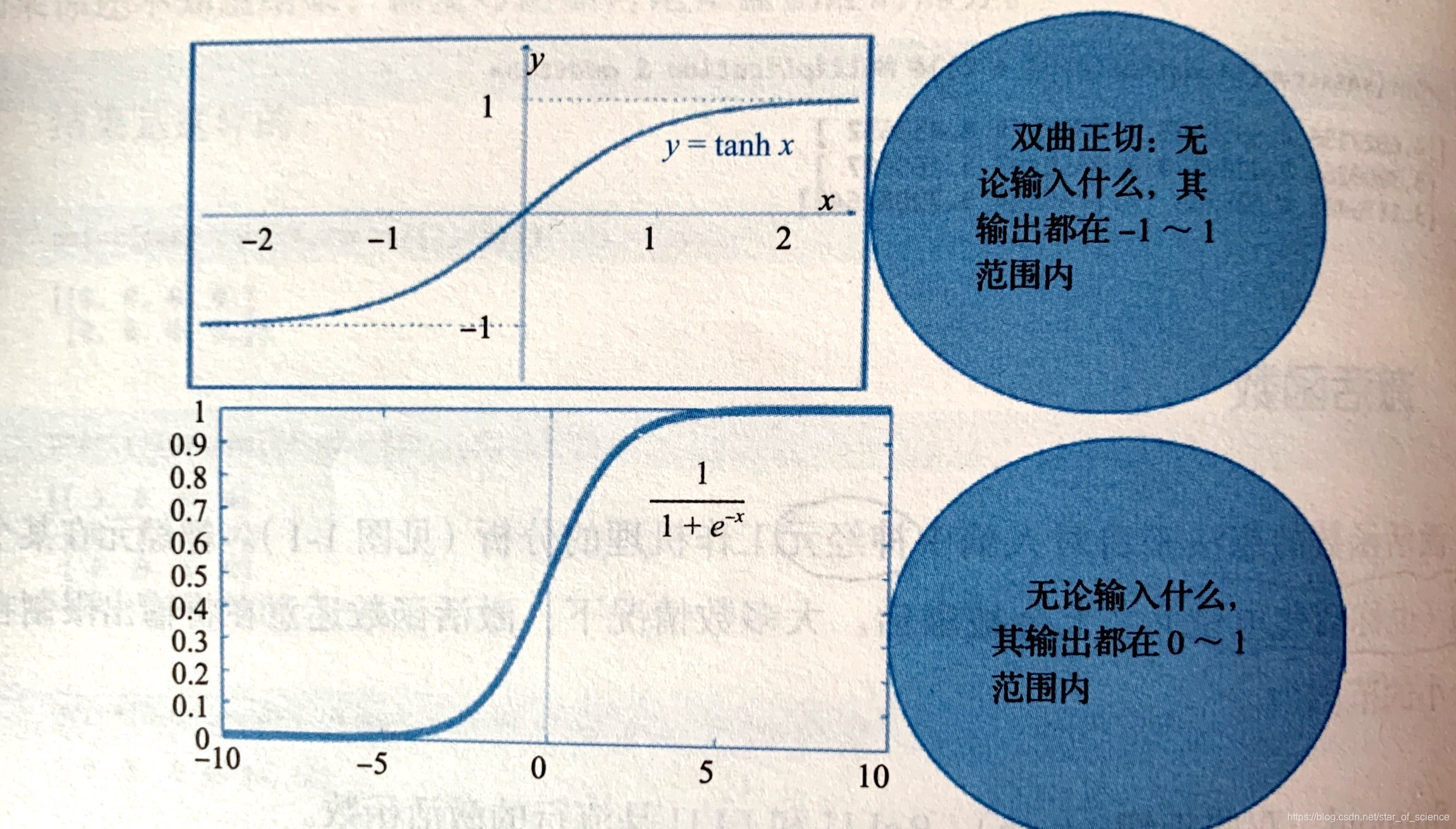
如下图展示了tanh与Sigmoid激活函数:
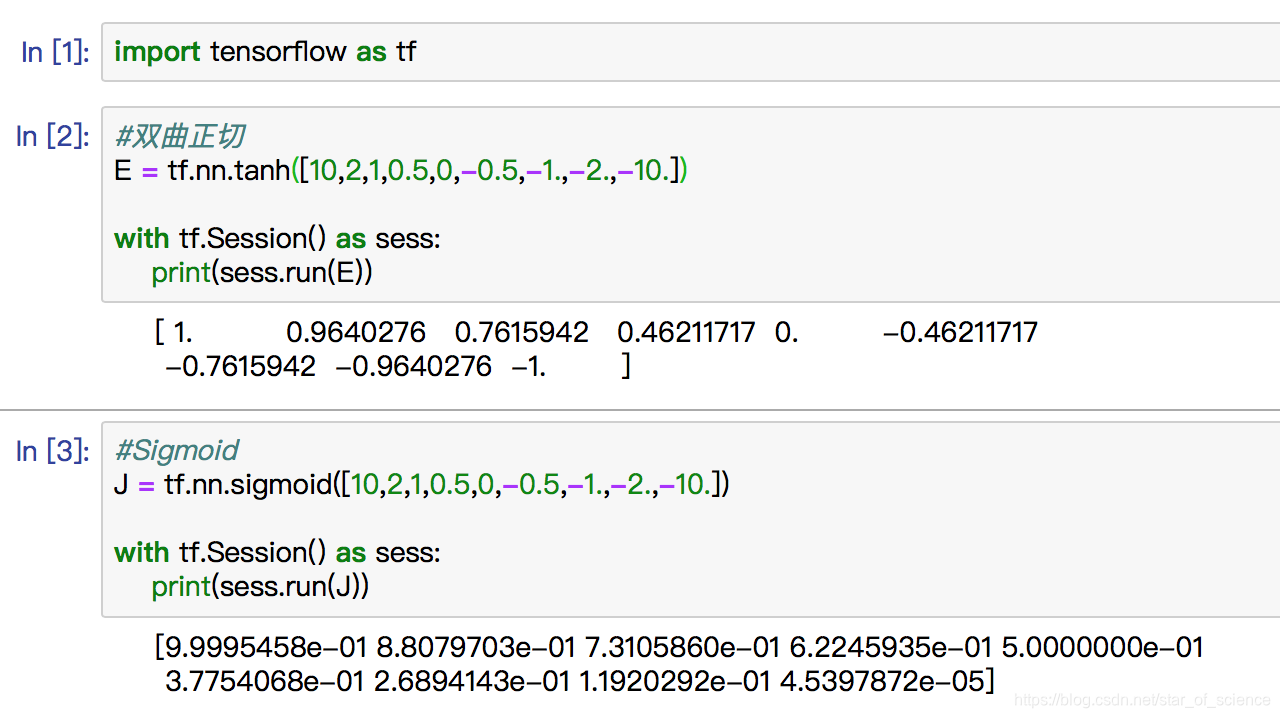
演示代码如下:
2.损失函数(代价函数)
损失函数(代价函数)是用来最小化以得到模型每个参数的最优值的。比如说,为了用预测器(X)来预测目标(y)的值,需要获得权重值(斜率)和偏置量(y截距)。得到斜率和y截距最优值的方法就是最小化代价函数/损失函数/平方和。对于任何一个模型来说,都有很多参数,而且预测或进行分类的模型结构也是通过参数的值来表示的。
你需要计算模型,并且为了达到这个目的,你需要定义代价函数(损失函数)。最小化损失函数就是为了寻找每个参数的最优值。对于回归/数值预测问题来说,L1或L2是很有用的损失函数。对于分类问题来说,交叉熵是很有用的损失函数。Softmax或者Sigmoid交叉熵都是非常流行的损失函数
2.1 L1范数损失函数
L1范数损失函数,也被称为最小绝对值偏差(LAD),最小绝对值误差(LAE)。总的说来,它是把目标值(Yi)与估计值(f(xi))的绝对差值的总和(S)最小化:
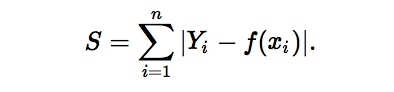
2.2 L2范数损失函数
L2范数损失函数,也被称为最小平方误差(LSE)。总的来说,它是把目标值(Yi)与估计值(f(xi))的差值的平方和(S)最小化:
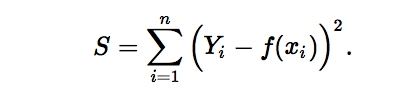
2.3 二次代价函数
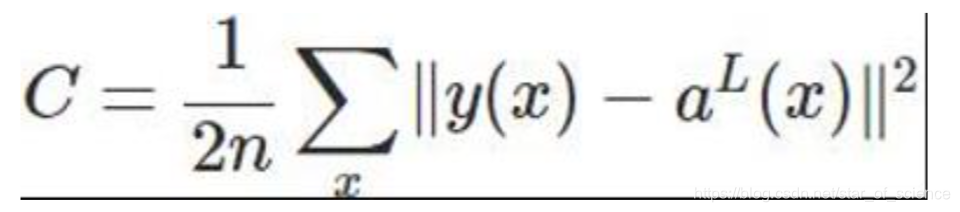
C表示代价函数,x表示样本,y表示实际值,a表示输出值,n表示样本的总数。
为简单起见 ,以假如只有一个样本为例进行说明,
a=σ(z), z=∑Wj*Xj+b
σ() 是激活函数
此时二次代价函数为:
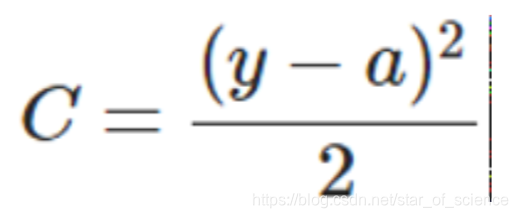

从上面可以看出二次代价函数W,b的梯度变化是与激活函数有关的。
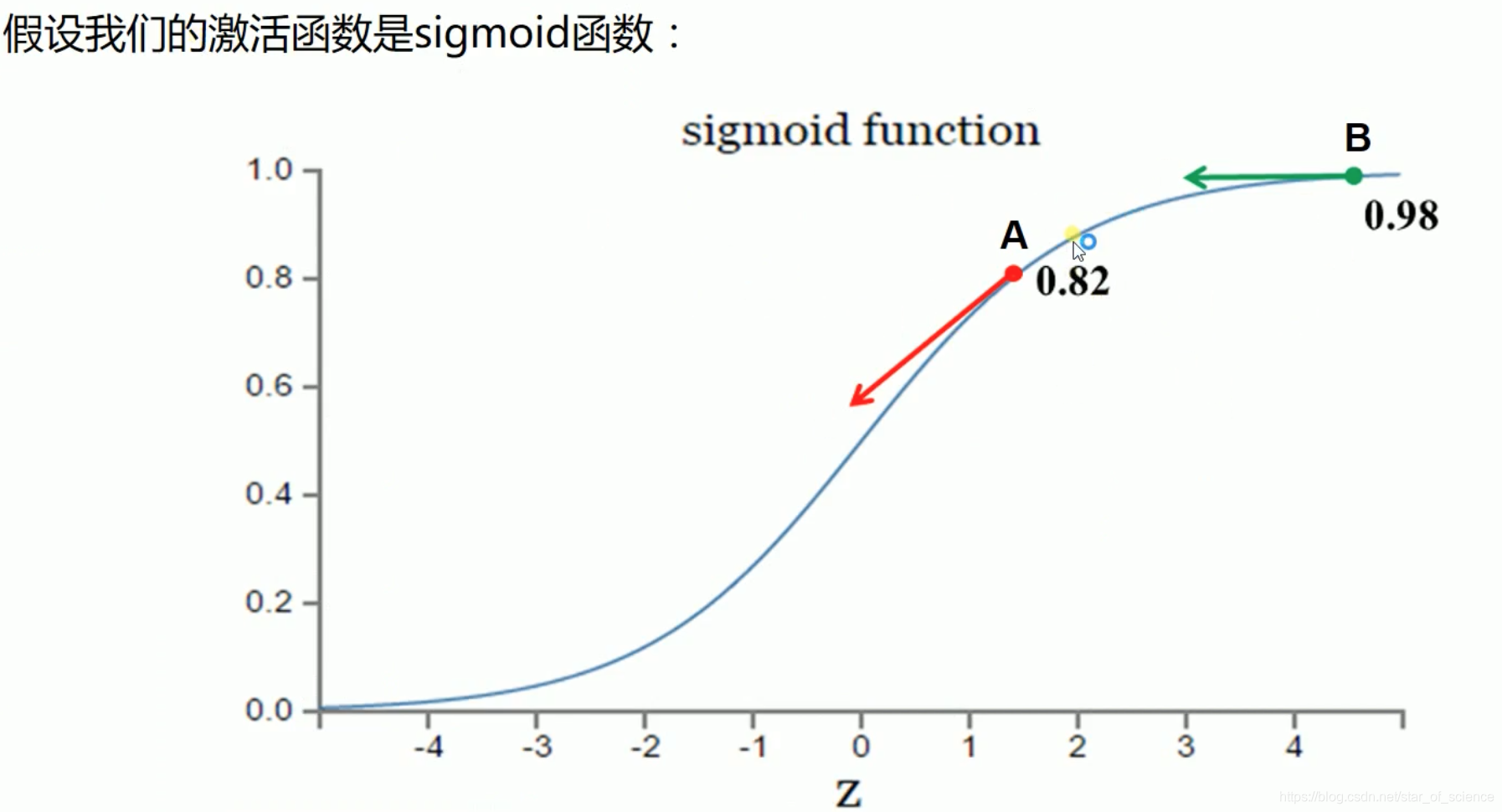
- 假设我们的收敛目标是1。A点为0.82,距离目标较远,而A点梯度较大,权值调整较大,B点为0.98,距离目标较近,而B点梯度较小,权值调整较小。因此,它能够很快的从A点调整到B点,再慢慢向1收敛,这个方案是合理的。
- 假设我们的收敛目标是0。B点为0.98,距离目标较远,而B点梯度较小,权值调整较小,A点为0.82,距离目标较近,而A点梯度较大,权值调整较大。因此,它如果从B点开始,它会在B点经历很长一段时间才能到A,那么这个方案是不合理的。
如果误差比较大,说明离我们的目标比较远,此时权值调整的应该比较大,这是我们觉得比较合理的情况。
2.4 交叉熵代价函数


2.5 对数释然代价函数(log-likelihood cost)
对数释然函数常用来作为softmax回归的代价函数,如果输出层神经元是sigmoid函数,可以采用交叉熵代价函数。而深度学习中更普遍的做法是将softmax作为最后一层,此时常用的代价函数是 对数释然代价函数。
对数似然代价函数与softmax的组合和交叉熵与sigmoid函数的组合非常相似。对数释然代价函数 在二分类时可以化简为交叉熵代价函数的形式。
在Tensorflow中用:
tf.nn.sigmoid_cross_entropy_with_logits()来表示跟sigmoid搭配使用的交叉熵。 tf.nn.softmax_cross_entropy_with_logits()来表示跟softmax搭配使用的交叉熵。
3.演示代码
修改3-2简单实现手写数字识别代码,使用softmax交叉熵代价函数:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#载入数据集
mnist = input_data.read_data_sets("MNIST_data", 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









