




 本文深入讲解Python的数据类型包括整型、浮点数、字符串、布尔值和空值,探讨变量与常量的区别,以及Python的运算符和格式化方法。同时,介绍了列表和元组的使用技巧,条件判断与循环的实现方式,以及字典和集合的基本操作。
本文深入讲解Python的数据类型包括整型、浮点数、字符串、布尔值和空值,探讨变量与常量的区别,以及Python的运算符和格式化方法。同时,介绍了列表和元组的使用技巧,条件判断与循环的实现方式,以及字典和集合的基本操作。
数据类型和变量
一、数据类型
1、整型
2、浮点
- 整数和浮点数在计算机内部存储的方式是不同的
- 整数运算永远是精确的(除法也是精确的)
- 浮点数运算则可能会有四舍五入的误差
- 浮点的舍入误差其他语言也是存在的
3、字符串
- 转义字符
\的作用是将普通的字符赋予特殊的含义或者将特殊的字符普通化 - 字符串的前面加上
r'content\n'会将字符串原样输出,不会有字符的转义 - python单双引号都是用来书写字符串的,基本没啥区别
- 多行字符串可以使用
'''content'''
4、布尔值
- 就两个值:True和False
- 需要注意的就只有一点首字母是大写的
5、空值
- 空值(None)和 0 不能等同
1.Python程序是大小写敏感的
2.Python使用缩进来组织代码块,请务必遵守约定俗成的习惯,坚持使用4个空格的缩进
3.在文本编辑器中,需要设置把Tab自动转换为4个空格,确保不混用Tab和空格
二、变量
1、变量
- python这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言
- 静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配就会报错
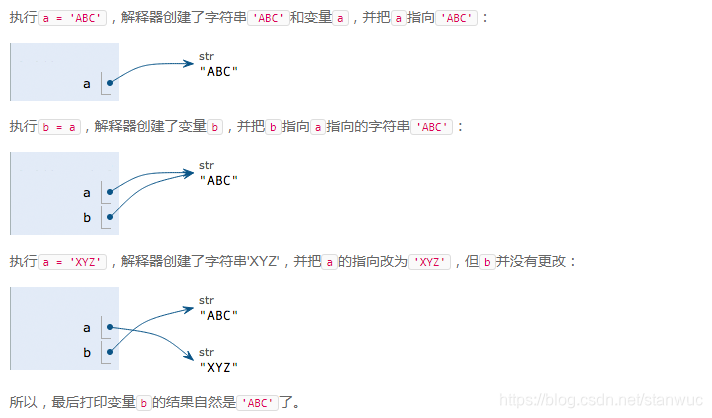
关于变量赋值
a = 'ABC'
b = a
a = 'XYZ'
print(b)
2、常量
- 全大写字母的变量名表示常量,当然这只是一个约定,你非要改变常量的值在python是无法约束的
python 中的除法
- 一般除法
/:最后的结果一定是一个浮点数 - 地板除
//:只保留整数部分,其中一个操作数为浮点结果就是浮点 - 取余
%:保留余数,其中一个操作数为浮点结果就是浮点
python 中运算符
- 成员运算符:
in 、 not in - 身份运算符:
is 、 is not is用于判断两个变量引用对象是否为同一个,==用于判断引用变量的值是否相等id()函数用于获取对象内存地址
python中整数和浮点数均没有大小限制
字符串和编码
一、字符编码
- 字符编码的概念就是把我们人类的语言符号转化为计算机可识别的二进制数,转化的方式有多种对应多种不同的编码系统
- 常用的编码系统有ASCII、gb2312、utf-8等,关于编码的详细说明可以参考文章:你真的了解 Unicode 和 UTF-8 吗?
1、总结
- ASCII 码只能表示 128 个字符,只是针对美国英语而设计的, 为了表示其他语言的字符,于是就有了 Unicode
- Unicode 只是一个字符集,里面收集了全世界绝大部分语言的字符。它有多种实现方式(编码方式),最常用的就是 UTF-8
- UTF-8 编码是变长字节的,用1 到 4 个字节来存储字符,并且它能够完全兼容 ASCII 码
二、python字符串
1、单字符和编码数转换
- chr 和 ord 方法

2、字符串和字节转换
- bytes类型数据:
ha=b'abx' - bytes转换为str:
b'haha'.decode('utf-8',errors='ignore') - str转化为bytes:
'haha'.encode('utf-8') len方法对str计算字符数,对bytes计算字节数
3、python文件编码问题
- python文件开头一般加入如下的两行
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#!/usr/bin/python3
#coding: utf-8
说明
- 第一行告诉linux系统使用python解析器处理这个文件
- 第二行告诉解析器使用utf-8编码处理文件
- 申明了UTF-8编码并不意味着文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码
三、格式化
1、使用%进行格式化
- 基本使用方式:
print( 'Hello, %s' % 'world') - 常见的占位符有:
d f s x(十六进制整数) %的转义使用%%
2、format方法格式化
- 基本使用:
'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
b'\xd6\xd0\xce\xc4'和b'\u4e2d\u6587':前者代表十六进制单字节编码,后者代表unicode编码
使用list和tuple
一、列表(list)
- python list 的写法:
['python', 'java', ['asp', 'php'], 'scheme',123] - list 是一个有序可变集合,支持嵌套,数据类型可以不同
1、list的索引和长度
- 正向索引从0开始,方向索引从-1开始
- 获取元素个数使用
len(list)
2、list的增删改查
- 追加元素到末尾:append
- 指定元素的添加位置:insert(1,‘test’)
- 删除末尾元素:pop
- 删除指定元素:pop(index)
- 替换某个元素:list[index]=‘new’
- 元素获取:list[index]
二、元组(tuple)
- tuple的写法:
(1,2,3) - 空tuple和一个元素tuple定义:
()和(1,)
1、元组的特点
- tuple是一个有序集合,但是不可变,可以理解为一个readonly的list,不可变的特性使得tuple更安全
- 没有insert、append、pop等方法,可以正常取用,但是不能修改
2、理解元组的不可变
- 准确说应该是指向不变,如果元素本身是可变的(比如list)可做如下理解
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
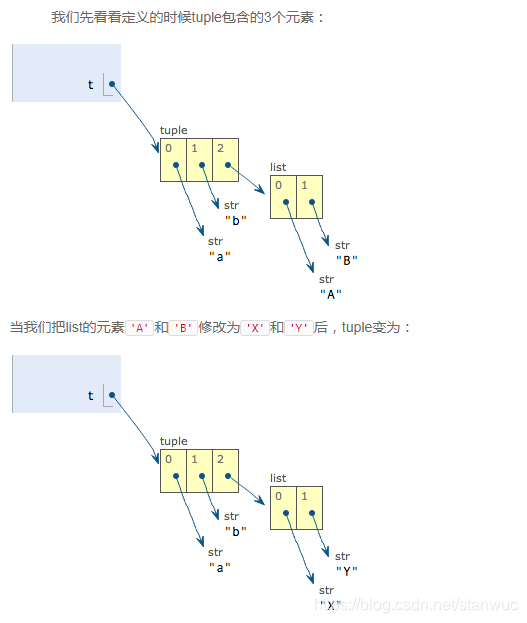
要做到真正不可变的元组必须保证元素的类型也是不可变的
条件判断
- 就是一个 if-elif-else语句,没有switch-case语句
# -*- coding: utf-8 -*-
height = 1.75
weight = 80.5
bmi = weight/(height**2)
print(bmi)
if bmi>=32:
print('严重肥胖')
elif bmi>=28:
print('肥胖')
elif bmi>=25:
print('过重')
elif bmi>=18.5:
print('正常')
else:
print('过轻')
循环
一、for–in循环
sum = 0
for x in range(101):
sum = sum + x
print(sum)
二、while循环
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)
- 循环中 break 和 continue 的用法和其他语言一致,不要滥用这两个,毕竟这两个实现的功能很多情况下直接加一个循环的条件就能实现
使用dict和set
- 二者放在一起因为他们的实现都使用了hash算法
- dict使用hash算法作用是通过key值计算出value的位置
- set使用hash算法是为了确保set中元素的唯一性
一、字典dict
- dict基本的写法:
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85} - 在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度
- 这种key-value存储方式,在放进去的时候,必须根据key算出value的存放位置,这样,取的时候才能根据key直接拿到value
- dict内部存放的顺序和key放入的顺序是没有关系的
- 和list比较,dict的优势是查找和插入的速度极快,劣势是需要占用大量的内存
- dict的key必须是不可变对象,也就是可hash的,根据key计算位置必须保证key不变才能保证每次的计算结果相同
1、字典的增删改查
- 增加直接指定新的键值即可:
d['Adam'] = 67 - 删除使用
pop(key)键值会一起删除 - 多次对一个key放入value,后面的值会把前面的值冲掉
- 获取键对应的值用
d['Adam']键不存在的时候会报错,使用get('haha',-1)不存在会返回-1 - 判断字典中是否存在某个键:
'allen' in d'
二、集合set
- 基本写法:
s = set([1, 2, 3]) 或 s={1,2,3} - set是无序和无重复元素的集合,也是使用了 hash算法来保证元素的不重复
- 不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”
1、set增删元素和集合运算
- 增加直接使用add方法,删除使用remove方法
- 可以进行集合交并运算(
& |)
2、关于不可变元素
- str是不可变对象,运行下面的代码之后,我们发现a的值是没有发生变化的,replace方法本质是返回了一个
'Abc'的副本,而没有改变原字符串的值 - 要始终牢记的是,a是变量,而
'abc'才是字符串对象
a = 'abc'
b=a.replace('a', 'A')
print(b)
print(a)
文章大部分参考廖雪峰老师的python教程

















 9746
9746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









