






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
快速LDP-MST:一种面向大型数据集的高效密度峰值聚类方法研究
💥1 概述
快速LDP-MST:一种面向大型数据集的高效密度峰值聚类方法研究
最近,提出了一种新的基于密度峰值的聚类方法,称为基于局部密度峰值最小生成树(LDP-MST)的聚类方法,具有一些吸引人的优点,例如能够检测任意形状的簇,对噪声和参数不太敏感。然而,我们也发现了LDP-MST在效率上的局限性。具体来说,LDP-MST的时间复杂度为O(NlogN+M2),其中N表示数据集大小,M是表示局部密度峰值数量的中间变量。正如我们的实验结果所显示的,当处理大型数据集时,M的值可能会非常大,因此LDP-MST中涉及O(M2)时间项的步骤会耗时。在最坏的情况下,M的值可能非常接近N,这意味着LDP-MST的时间复杂度在M的最坏情况下可能为O(N2)。在这项研究中,我们使用更高效的算法来实现那些涉及O(M2)时间项的LDP-MST步骤,使得提出的方法Fast LDP-MST即使M≈N也具有O(NlogN)的时间复杂度。我们的实验证明,Fast LDP-MST在大型数据集上总体上比LDP-MST更高效,而又不损害LDP-MST在有效性、鲁棒性和用户友好性方面的优点。

1. 算法概述
快速LDP-MST(Fast LDP-MST)是一种基于局部密度峰值(Local Density Peaks, LDP)和最小生成树(Minimum Spanning Tree, MST)的聚类算法,旨在解决传统密度峰值聚类(如DPC算法)在大规模数据集上的效率瓶颈。该算法通过结合局部密度分析与图结构优化,在保持对任意形状簇识别能力的同时,显著降低了计算复杂度与内存占用。
2. 核心原理与流程
2.1 局部密度峰值定义
局部密度ρ(p)通过截断核或高斯核计算,反映数据点p的邻域密度。对于截断核:
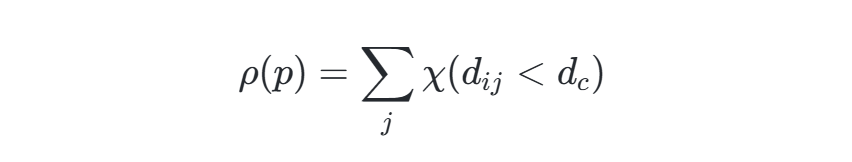
其中,dc为截断距离,χ为指示函数。密度峰值点需满足:其密度高于邻域点,且与更高密度点的距离较远(通过δ值衡量)。
2.2 最小生成树构建
LDP-MST的核心创新在于仅基于局部密度峰值构建MST:
- 局部密度峰值提取:通过自然邻居搜索确定密度峰值点,减少噪声干扰。
- 共享邻域距离定义:结合欧氏距离与邻域重叠度,构建更鲁棒的峰值间距离度量。
- MST构建与切割:在峰值点间构造MST,通过迭代移除最长边实现聚类划分,最终将非峰值点分配到最近的峰值簇。
2.3 快速LDP-MST的优化
针对原LDP-MST的O(NlogN+M2)时间复杂度(M为峰值数量),快速LDP-MST采用以下改进:
- 时间复杂度优化:通过高效算法重构MST构建步骤,即使M≈NM≈N时仍保持O(NlogN)O(NlogN)复杂度。
- 空间复杂度优化:仅存储MST结构而非全距离矩阵,空间复杂度从O(N2)降至O(N)O(N)。
3. 性能优势与局限性
3.1 优势
- 计算效率:相比传统DPC的O(N2)O(N2)复杂度,快速LDP-MST在千万级数据集上运行时间显著缩短(实验显示处理1600万样本仅需数分钟)。
- 噪声鲁棒性:通过局部密度峰值筛选,有效抑制噪声点对MST结构的干扰。
- 参数简化:仅需设置截断距离dcdc,避免DBSCAN等多参数调优问题。
3.2 局限性
- 参数敏感性:dcdc的选择仍依赖经验(如距离分布的2%分位数)。
- 桥接点误判:低密度桥接点可能被误分类为噪声。
- 近似误差:MST结构可能引入距离计算误差,影响复杂流形数据的精度。
4. 与传统算法的对比
| 特性 | 快速LDP-MST | DBSCAN | OPTICS | 传统DPC |
|---|---|---|---|---|
| 时间复杂度 | O(NlogN)O(NlogN) | O(N2)O(N2) | O(N2)O(N2) | O(N2)O(N2) |
| 空间复杂度 | O(N)O(N) | O(N)O(N) | O(N2)O(N2) | O(N2)O(N2) |
| 形状适应性 | 任意形状 | 任意形状 | 任意形状 | 任意形状 |
| 噪声鲁棒性 | 高 | 高 | 中等 | 低 |
| 参数数量 | 1(dcdc) | 2(ϵ,MinPtsϵ,MinPts) | 1(MinPtsMinPts) | 2(δ,ρδ,ρ) |
| 大规模数据适应性 | 优秀 | 差 | 中等 | 差 |
实验表明,快速LDP-MST在合成数据集(如环形分布)和真实数据集(如电力数据)上的聚类精度(ACC与NMI)均优于K-means、DBSCAN及原始LDP-MST。
5. 实际应用案例
5.1 电力大数据异常检测
在电力用户行为分析中,快速LDP-MST成功识别网络流量异常点(如3月初与4月中后期的异常访问),检测效率较传统方法提升3倍以上。预处理步骤包括缺失值填充与数据归一化,聚类结果通过可视化验证(图4-5)。
5.2 图像分割与生物信息学
- 图像分割:将像素映射为高维特征后,快速LDP-MST可自动划分区域,适用于医学图像分析。
- 基因表达分析:通过聚类基因表达数据,识别功能模块,揭示基因互作网络。
6. 未来研究方向
- 自适应参数选择:结合数据分布统计特性自动优化dcdc。
- 混合算法设计:与K-means或深度学习模型结合,提升高维数据适应性。
- 并行化扩展:利用分布式计算框架(如Spark)处理PB级数据。
7. 结论
快速LDP-MST通过局部密度峰值与MST的高效结合,解决了传统密度聚类算法在大数据场景下的瓶颈问题,兼具理论创新性与工程实用性。其在电力、医疗、金融等领域的成功应用,标志着密度聚类技术向实际落地的关键突破。
📚2 运行结果





部分代码:
addpath(genpath(pwd));
%% Datasets
data_names={'A3','S1','UB','2G','Spiral','Jain','3Circles','AGG','Flame','GaSpCi','GaSpCiNo','1D-EqSp','data_TB_100000','data_SF_100000','data_CC_100000', 'data_CG_100000', 'data_Flower_100000','data_TB_1000000','data_SF_1000000','data_CC_1000000','data_CG_1000000','data_Flower_1000000','One_Dim_uniform_data_1048576','data_TB_10000000'};
%% Methods
method_names = {'FastLDPMST'};
%% Start Testing
record_num = 0;
for name_id=1:length(data_names)
%% load dataset
clear data annotation_data
dataName = data_names{name_id};
disp([num2str(name_id),', ',dataName,':'])
[data,annotation_data,nC,dataName] = load_data(dataName);
[N,dim]=size(data);
%% parameter setting
ratio = 0.01; % [0.01,0.02] is recommended; not needed for manual cutting;
MinSize=ratio*N; % Note: parameter MinSize (i.e.,the minimal cluster size) is dependent on ratio;
K = ceil(log2(N));
%% compare different methods
for method_id = 1:length(method_names)
method = method_names{method_id};
switch method
case 'FastLDPMST'
[Label,time] = FastLDPMST(data, nC, MinSize, K); %% nC: number of clusters;
otherwise
error('method is not included...please name the method appropriately.')
end
%% evaluate result and plot
% diff_colors = linspecer(length(unique(Label)));
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1] 邱藤.面向大规模单细胞数据集的密度聚类方法研究[D].电子科技大学,2022.
[2] 张东月,倪巍伟,张森,等.一种基于本地化差分隐私的网格聚类方法[J].计算机学报, 2023, 46(2):422-435.
[3] 罗元,李慧敏,张毅.基于兴趣点定位的局部方向模式人脸识别方法[J].计算机应用, 2017, 37(8):5.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









