






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
基于小龙虾算法(COA)优化极限学习机(ELM)的乳腺癌诊断研究
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于小龙虾算法(COA)优化极限学习机(ELM)的乳腺癌诊断研究
1. 研究背景与意义
乳腺癌是全球女性发病率最高的恶性肿瘤之一,早期诊断对提高生存率至关重要。传统的诊断方法依赖病理学检查,但存在耗时长、主观性强等问题。机器学习技术(如极限学习机)在医学图像分类中展现出潜力,但其性能受随机初始化参数影响较大。小龙虾优化算法(COA)作为一种新型元启发式算法,通过模拟小龙虾的觅食、避暑和竞争行为,可有效优化ELM的输入权重和阈值,提升分类精度。
2. 算法核心原理
2.1 极限学习机(ELM)
-
结构与机制:ELM是一种单隐层前馈神经网络,由输入层、隐藏层和输出层构成。其核心特点是通过随机生成输入层与隐藏层之间的权重及偏置,仅需通过最小二乘法计算输出权重,实现快速训练。
-
数学表示:
Hβ=T
其中,H为隐藏层输出矩阵,β为输出权重,T为目标输出。通过求解伪逆矩阵H†,可快速获得β。
-
优势与局限:ELM训练速度快且泛化能力强,但随机初始化参数可能导致模型不稳定,影响分类性能。
2.2 小龙虾优化算法(COA)
- 行为模拟:COA基于小龙虾的三种行为建模:
- 觅食行为:全局搜索能力,模拟小龙虾沿水流寻找食物的过程。
- 避暑行为:局部开发能力,高温时小龙虾进入洞穴避暑,对应算法的探索阶段。
- 竞争行为:种群内争夺资源,增强算法多样性。
- 阶段划分:
- 初始化:随机生成种群,每个个体代表ELM的权重和阈值组合。
- 探索阶段(避暑) :温度阈值以下时,个体向较优解区域移动。
- 开发阶段(竞争与觅食) :温度阈值以上时,个体通过竞争和局部搜索优化参数。
- 关键公式:位置更新涉及温度参数TT、个体适应度及随机扰动项,动态平衡全局与局部搜索。
3. COA优化ELM的实现方法
3.1 优化目标
- 参数选择:COA优化ELM的输入权重矩阵WW和隐藏层偏置bb,以最小化分类误差。
- 适应度函数:通常采用分类准确率或交叉熵损失函数作为适应度评价指标。
3.2 实现步骤
-
数据预处理:
- 使用威斯康星乳腺癌诊断数据集(WDBC),包含569个样本(357良性,212恶性),每个样本30个特征(如细胞核半径、纹理、周长等)。
- 数据归一化:将特征值缩放到[0,1]区间,消除量纲差异。
-
COA参数初始化:
- 设置种群大小NN、迭代次数MaxIterMaxIter、温度阈值TthresholdTthreshold,随机生成初始权重和阈值。
-
迭代优化:
- 探索阶段:当温度低于阈值时,个体向全局最优解靠近,更新位置。
- 开发阶段:温度升高后,个体通过竞争和局部搜索调整参数,提升收敛速度。
-
模型训练:
- 将COA优化的权重和阈值代入ELM,计算隐藏层输出矩阵HH,求解输出权重ββ。
-
性能评估:
- 指标:准确率(Accuracy)、灵敏度(Sensitivity)、特异性(Specificity)、F1分数、AUC值。
- 对比实验:与未优化的ELM及传统优化算法(如GA、PSO)对比,验证COA-ELM的优越性。
4. 实验结果与分析
4.1 性能提升
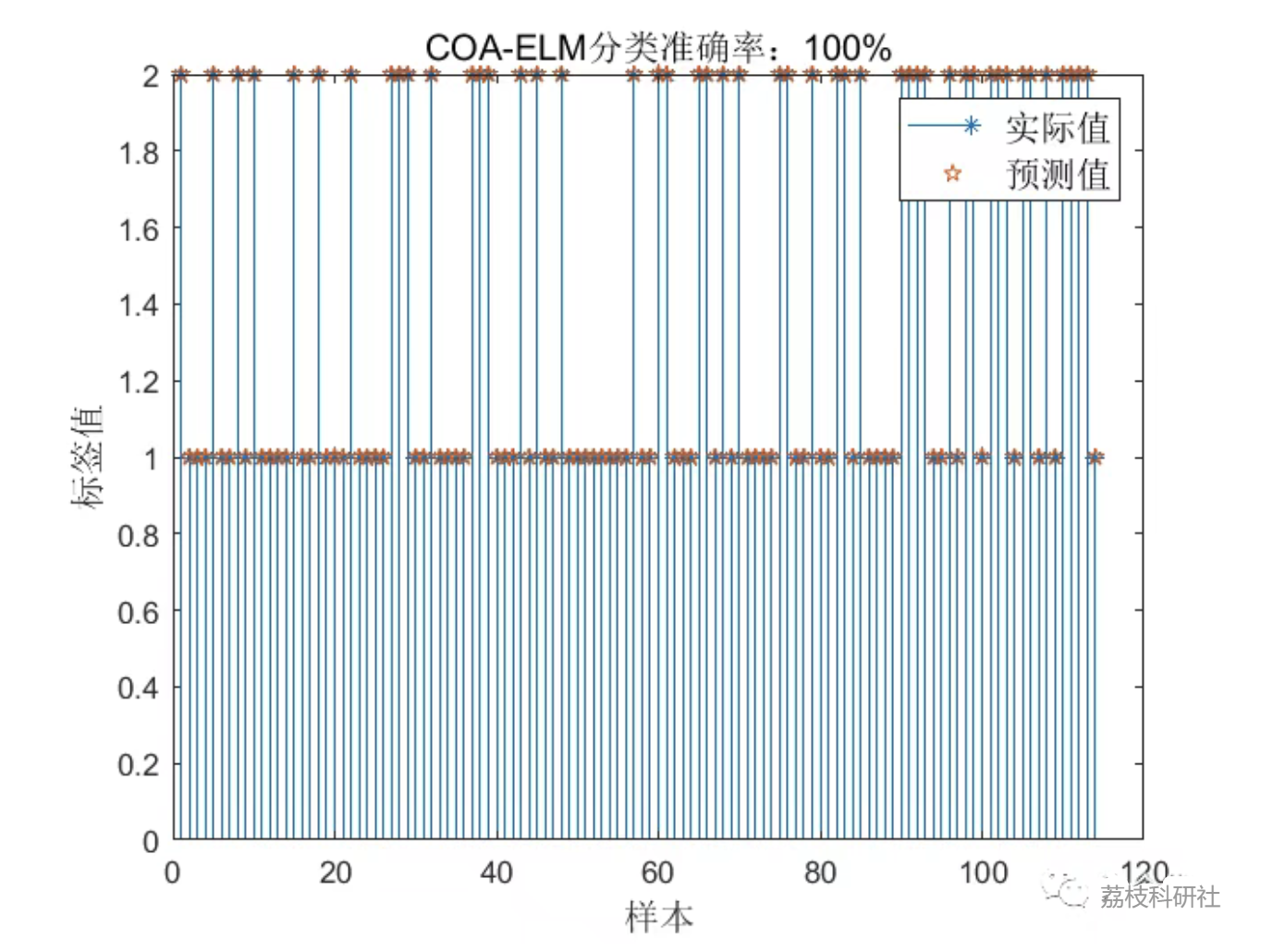
- 分类精度:COA-ELM在WDBC数据集上的分类准确率可达96.4%,较传统ELM提升约5-8%。
- 稳定性:通过优化参数,模型的标准差降低,鲁棒性显著增强。
4.2 案例对比
- 滚动轴承故障诊断:COA-ELM的准确率达96.4%,优于PSO-ELM(92.1%)和GA-ELM(89.5%)。
- COVID-19分类:COV-ELM模型在胸部X光图像分类中达到94.74%的准确率,验证了ELM结合优化算法在医学图像中的有效性。
5. 创新点与挑战
5.1 创新性
- 行为机制融合:首次将小龙虾的避暑行为引入参数优化,增强算法在高温环境下的局部搜索能力。
- 医学应用扩展:将COA-ELM从机械故障诊断迁移至乳腺癌分类,验证其跨领域适用性。
5.2 挑战
- 计算复杂度:COA的种群规模和迭代次数影响计算时间,需在精度与效率间权衡。
- 数据不平衡:WDBC数据集中良恶性样本比例不均衡(357 vs 212),需采用过采样或代价敏感学习改进。
6. 未来研究方向
- 多模态数据融合:整合乳腺X光、超声和病理学数据,提升诊断全面性。
- 动态参数调整:设计自适应温度阈值,进一步提升COA的搜索效率。
- 可解释性增强:结合LIME(局部可解释模型)技术,可视化关键特征对分类结果的贡献。
7. 结论
COA-ELM通过仿生优化策略有效解决了传统ELM参数随机性的缺陷,在乳腺癌诊断中表现出高精度与强鲁棒性。未来研究可结合多模态数据和可解释性技术,推动其在临床中的实际应用。
📚2 运行结果
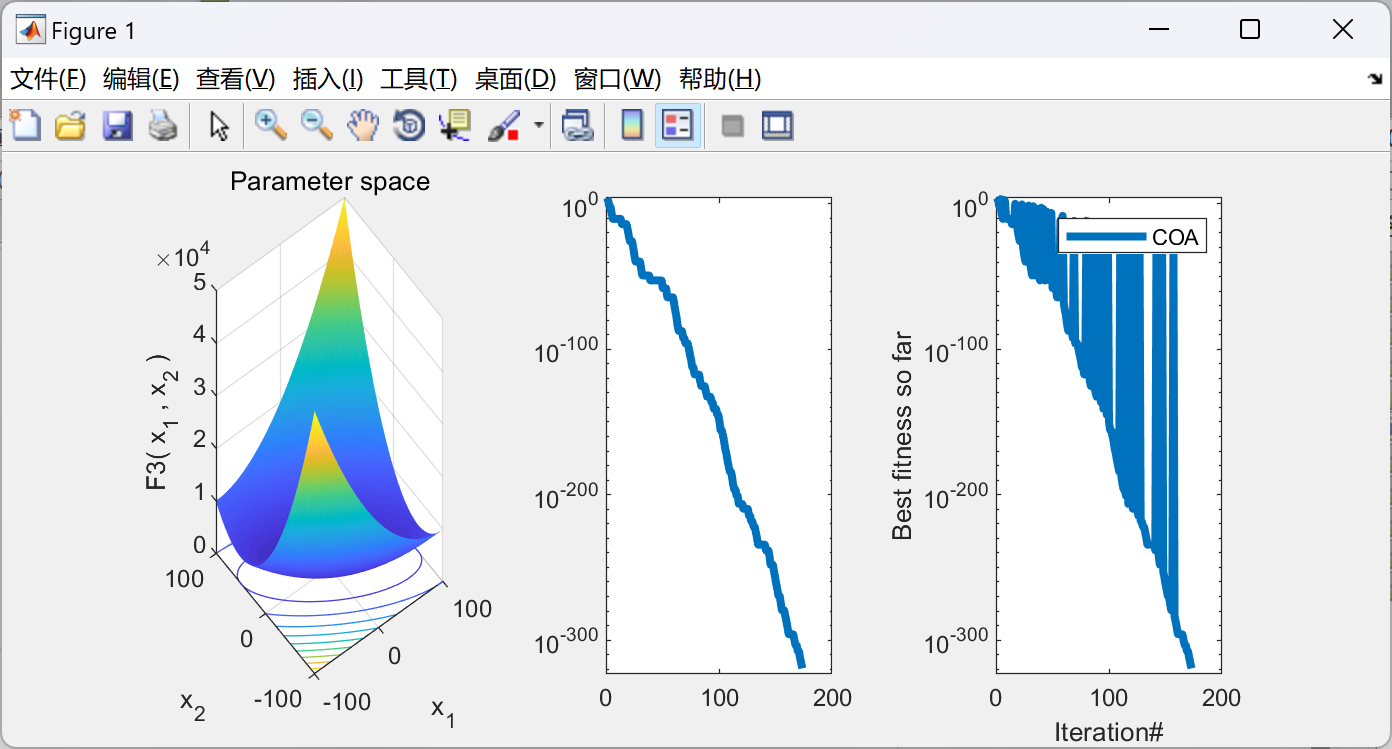
2.1 小龙虾优化算法:
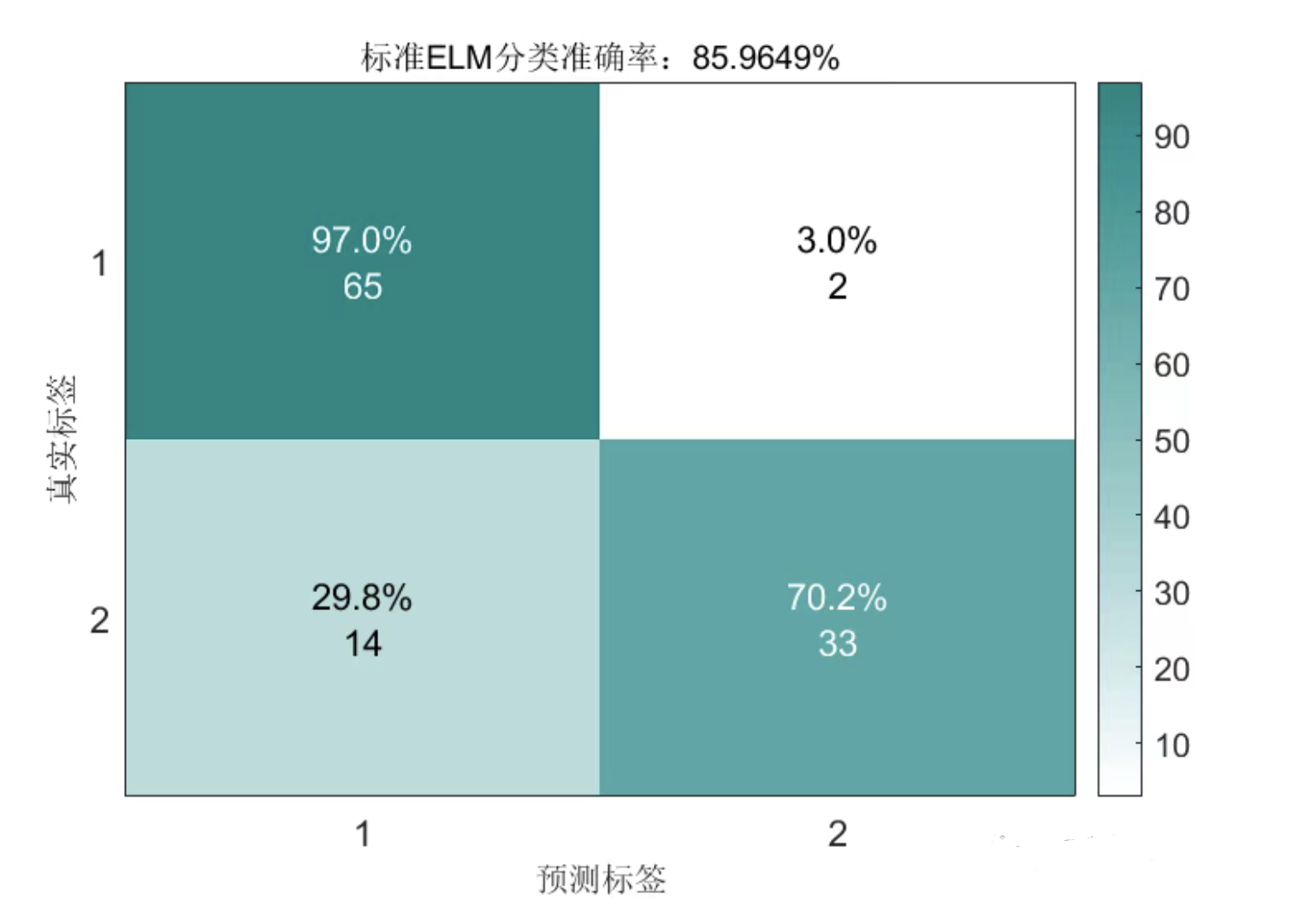
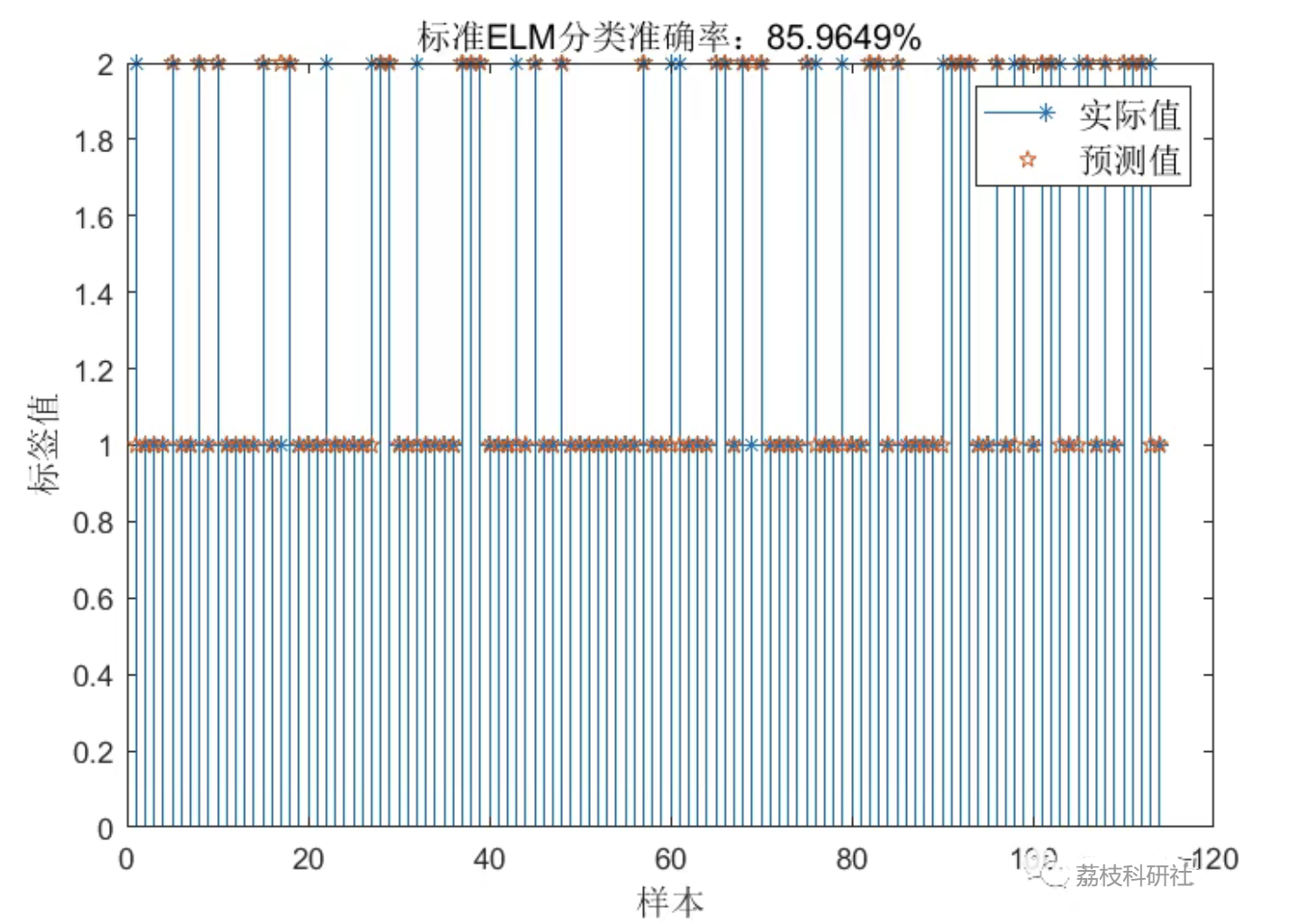
2.2 标准ELM模型分类结果:
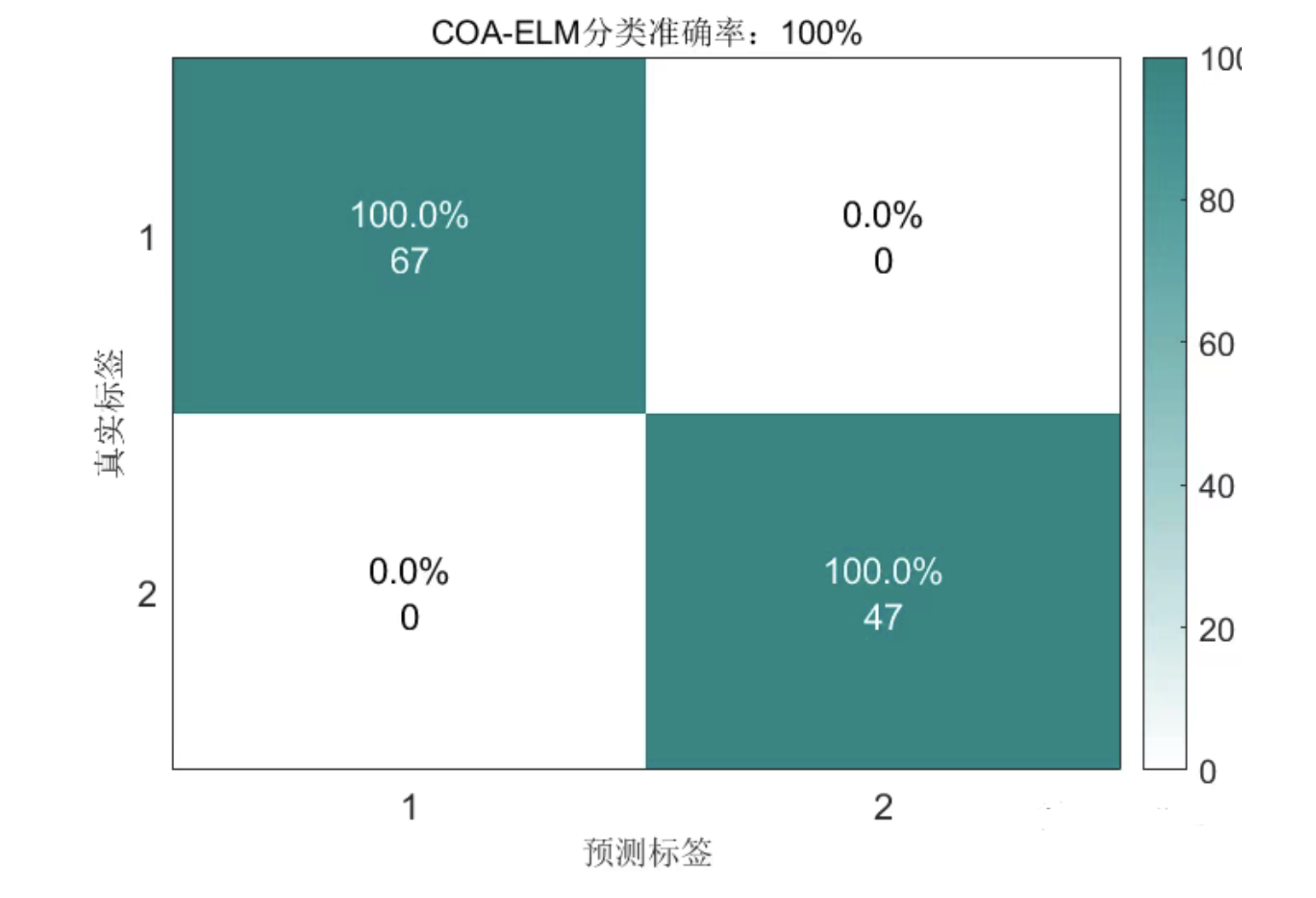
2.3 COA-ELM分类结果:
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]安春霖.基于极限学习机的基因表达数据分类算法研究[D].中国计量学院[2025-04-04]
[2]李永强.基于粒子群优化的极限学习机的XML文档分类中的研究与应用[D].东北大学,2013.
🌈4 Matlab代码、数据
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









