







KMP算法
传统暴力进行字符串匹配需要O(n^2)的时间复杂度,其过程可以简化为 i 是指向长字符串的指针,j 是指向短字符串的指针。每次在i开头的长字符串的子串内匹配,直到匹配成功或者遍历所有字符串。
for(int i = 0; i < n; i ++){
bool f = true;
for(int j =0; j < m; j++){
//如果当前字符串不等则跳出这次循环
if(q[i + j] != p[j]) {
f = false;
break;
}
}
}
KMP的优化之处是,在每次到字符串不相等的位置时,不是将 i 向后移动一位从头匹配,而是将 i 向后移动大于等于1的位数,也就是说短字符串会向后整体移动若干位,来缩短匹配时间。
至于具体移动多少位,是与短字符串相关的。要找到最短的移动距离(由于要找到有效的移动距离,移动距离要从1开始枚举直到找到一个,所以要找最短的移动距离),也就是要找到短字符串中最长的前缀后缀匹配位数
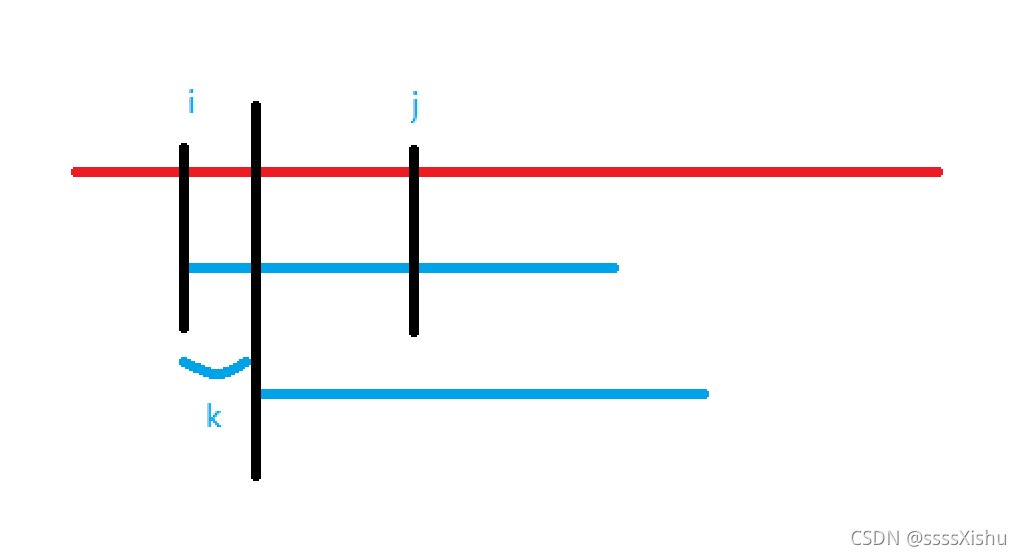
如下图所示,红色为长字符串,蓝色为短字符串,i 为长字符串匹配的起始地址,j 为长短字符串中不相等的位置。若想 i 连续移动 k 位,则短字符串中0到k的前缀与 j-k+1到j的后缀必须相等,才能从j-k+1的位置继续匹配
KMP算法模板
对于next数组,其中的每一个值next[i] 都会小于 i
j从跳到next[j]可以看做是,已知匹配字符串中从1到next[j]与被匹配的字符串中从i-next[j] + 1到i是相等的,所以减少了1到next[j]的重新匹配次数
求next数组的算法
//这里next数组存储的是,1到j中(含j)前缀后缀匹配时,最长的子串的长度
//next数组中,next[0]不会被使用到,由于字符串匹配是从1开始匹配,所以0是空缺的
ne[0] = -1;
//next数组中,next[1]指向的地址为0
ne[1] = 0;
//1.假设当前待验证的位置为i和j+1,意味着被匹配字符串与匹配字符串已经有j个字符相等
//2.当被匹配字符串与匹配字符串是同一个字符串时,此时的j也就是同一个字符串最长的前缀和后缀的长度
//3.接下来仅需要判断i这个字符与j+1这个字符是否相等,若相等则意味着从1到i中,被匹配字符串与匹配字符串已经有j+1个字符相等,并将此时的j存到next数组中
// 若不相等不需要将1到j的字符重新匹配,只需将j跳到next[j](从1到next[j]与被匹配的字符串中从i-next[j] + 1到i是相等的)直到找到相等或者j==0为止
//4.若j==0则代表前缀与后缀没有字符相等,并将此时的j存到next数组中
//5.每次将next数组更新后,i++
//起始从i = 2开始匹配,j = 0代表现在没有匹配到任何子串
for(int i = 2, j = 0; i < q.size(); i++){
//匹配到i的时候,首先判断当前是否存在已经匹配到的子串
//若存在匹配即j!=0,则比较两个子串的下一位即i与j+1是否相等
//若不相等,则将j跳到next[j]并继续判断是否相等,直到找到匹配或者j==0(均不匹配)为止
while(j && q[i] != q[j + 1]) j = ne[j];
//跳出循环时,一定是找到了某个相等的子串或者没找到相等的子串这两种情况
//若下一个值相等即找到了相等的子串则j++记录已经匹配到的子串
if(q[i] == q[j + 1]) j++;
//若不存在已经匹配到的子串则什么也不做
//最后将j记录到next数组
ne[i] = j;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









