




绕过请求头方法一、
绕过请求头检查:
import requests
import re
from fake_useragent import UserAgent
url='https://music.163.com/'
headers={
'user-agent':UserAgent().random
}
print(headers)
req=requests.get(url=url,headers=headers)
code=req.status_code
print(code)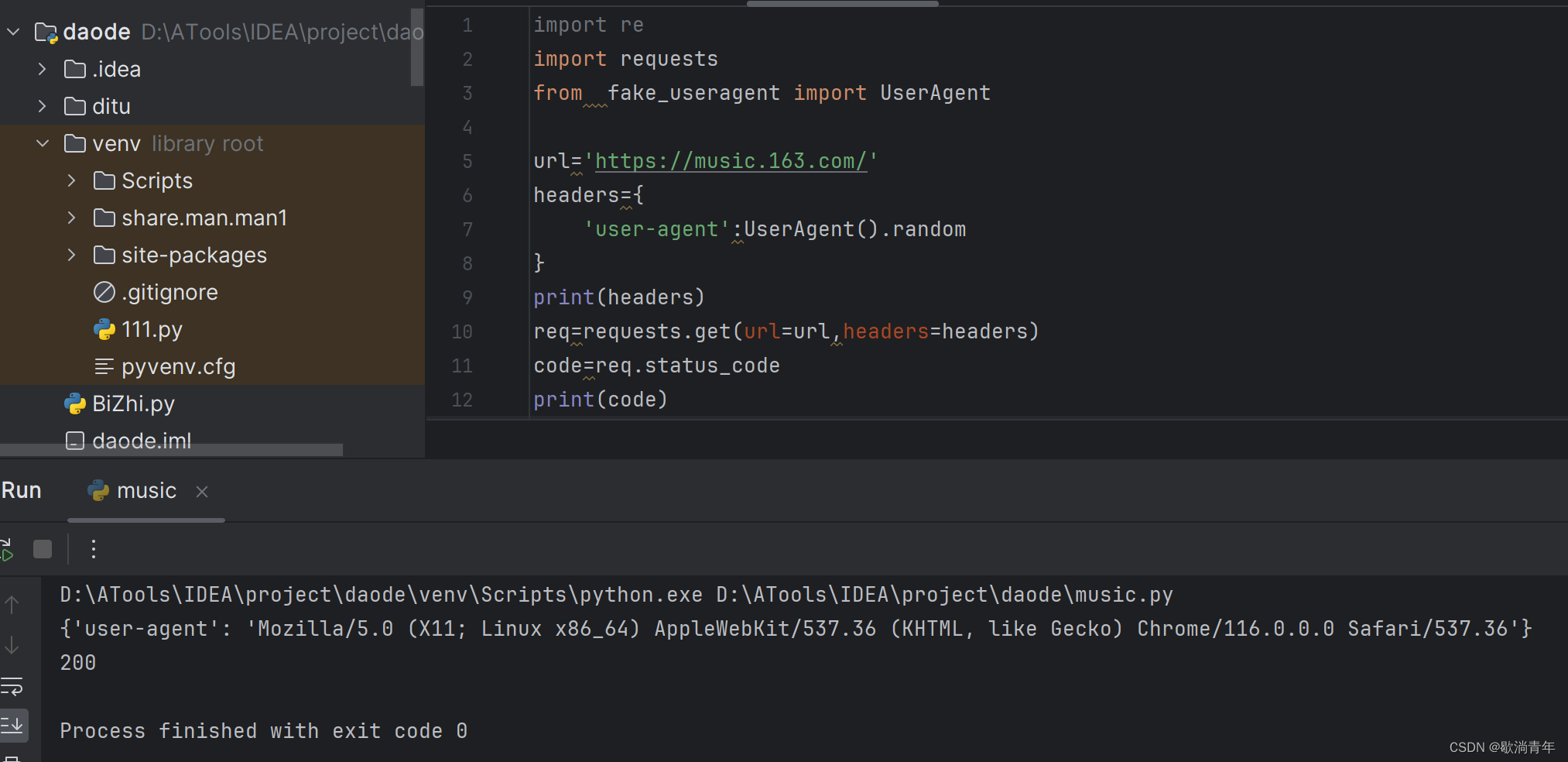
绕过请求头 方法二、
import requests
import re
import fake_useragent
ua=fake_useragent.UserAgent()
url='https://music.163.com/'
headers={
'user-agent':ua.random
}
print(headers)
req=requests.get(url=url,headers=headers)
code=req.status_code
print(code)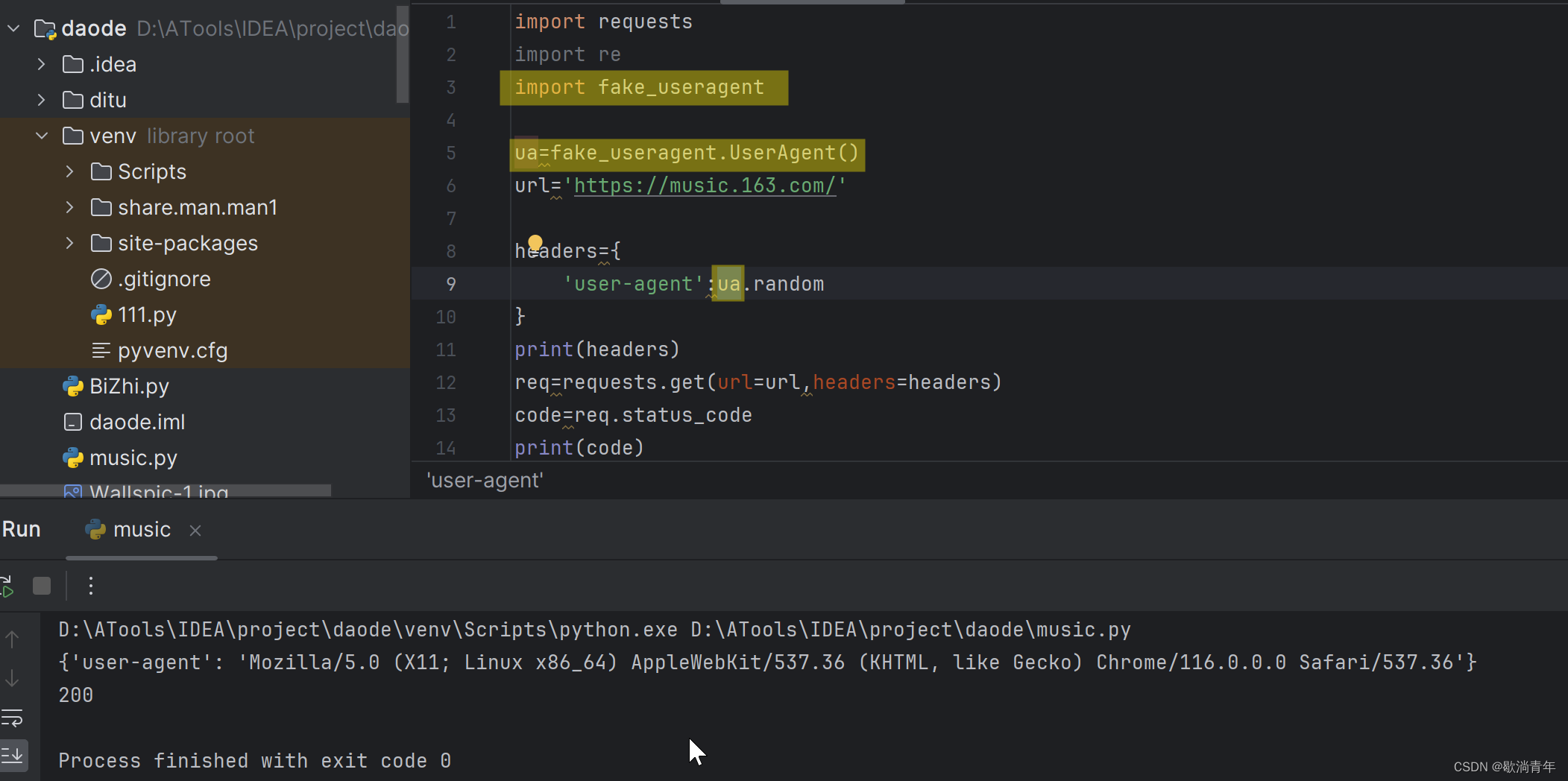
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











