




 本文介绍了如何设计虚拟人物,从使用MakeHuman创建角色,调整骨架约束,设定T-Pose,到导出mh2格式文件。接着在Blender 3.2.0中,通过mhx-blender插件导入人物并制作动作。最后,讨论了如何保存骨架动作为fbx格式,并预告了后续的头发和衣服制作等内容。
本文介绍了如何设计虚拟人物,从使用MakeHuman创建角色,调整骨架约束,设定T-Pose,到导出mh2格式文件。接着在Blender 3.2.0中,通过mhx-blender插件导入人物并制作动作。最后,讨论了如何保存骨架动作为fbx格式,并预告了后续的头发和衣服制作等内容。
- 虚拟人物设计
a.下载 make human.下载渠道为:MakeHuman 1.2.0 | www.makehumancommunity.org
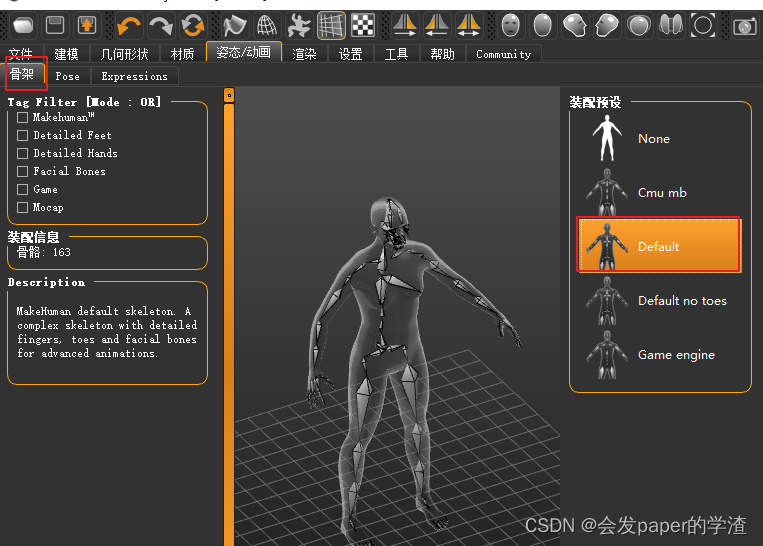
2、虚拟人物骨架约束(在makehuman 中进行,我使用default)
如下图:
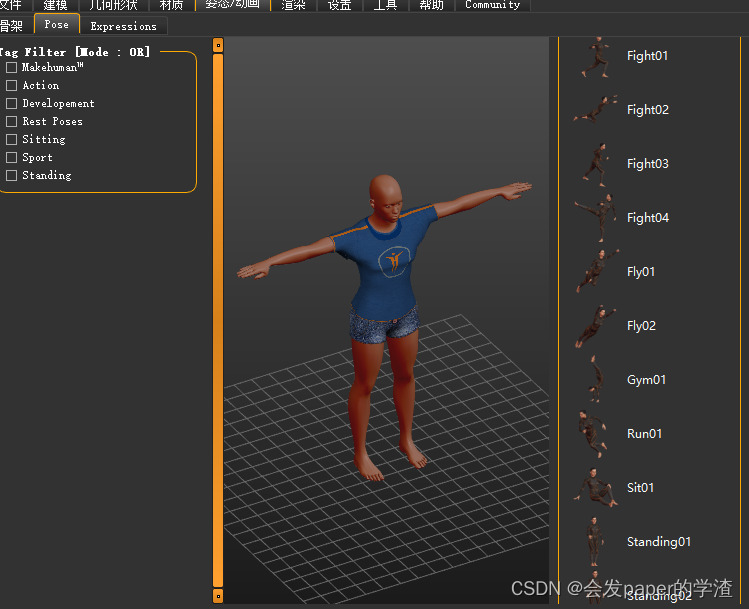
3、人物姿势为T-Pose
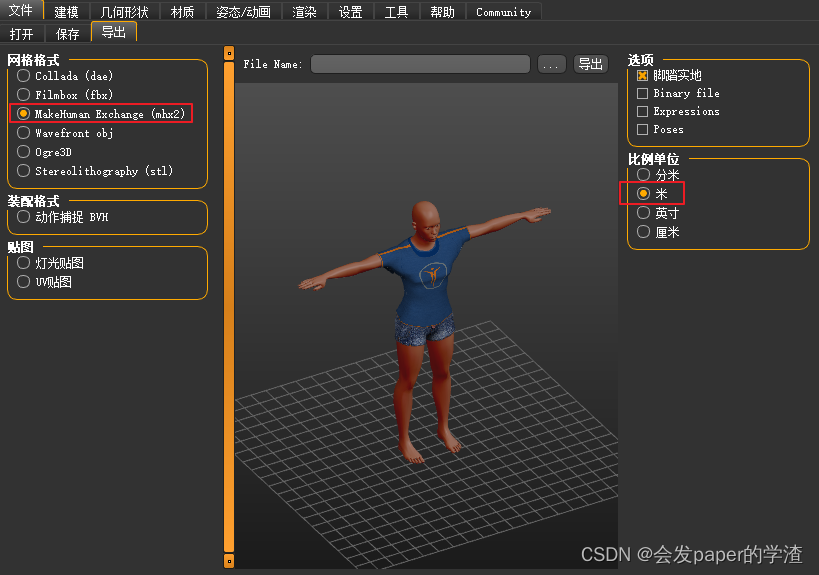
4、虚拟人物导出(mh2格式,是因为其他格式的骨架,在blender中会异常)
5、blender 下载,使用的是3.2.0版本:Download — blender.org
6、mhx-blender导入插件下载: https://download.tuxfamily.org/makehuman/plugins/mhx-blender-latest.zip
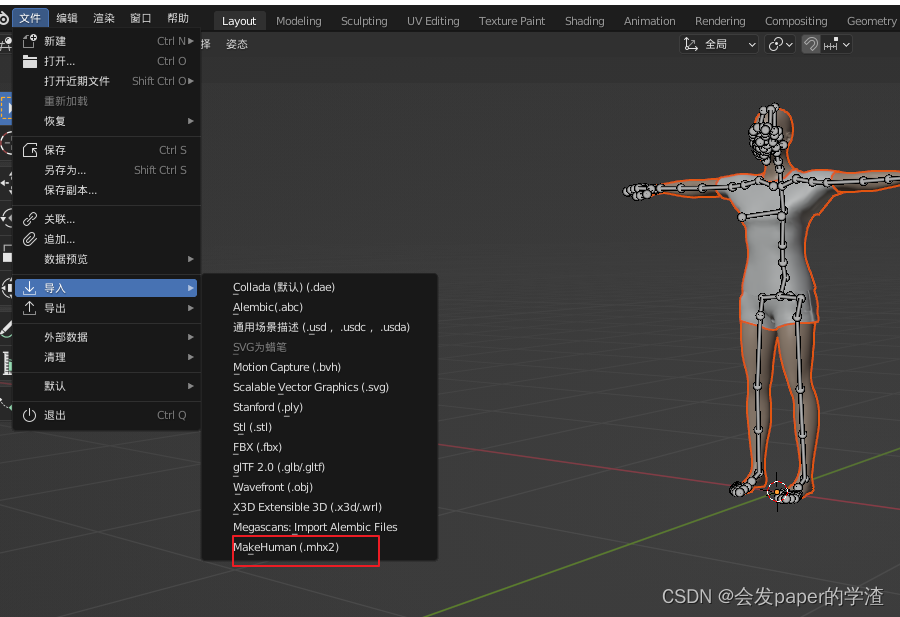
7、加载4导出的人物。导入过程以及导入后的结果如下:
8、动作制作(插帧即可):

9、删除人物相关的实体对象,保存骨架动作为fbx格式。
10、人物和动作混合执行:
# -*- coding: utf-8 -*-
import os
import re
import random
from datetime import datetime
import bpy
class ModelProcessingTool:
def __init__(self):
# self.start()
print("finished!")
##blender 执行是用绝对路径
self.base_data_path ="basicpath"
self.scn = bpy.context.scene
self.head_bone_reg=re.compile(r'.*[sS]pine.*')
def process_movie(self, action_list, sound_list):
start_time = datetime.now()
action_list = ["arms","leg"]
sound_list = ["visit","visit"]
# 删除场景中的全部对象
self.delete_all()
dedumplicate_action = list(set(action_list))
moudle_name = "person"
self.load_module(moudle_name, type='fbx')
# TODO 后续加载模型和动作需要分开
# *********************数据加载*********************************
print("load all actions and sound")
action_object_map = self.load_all_action(dedumplicate_action)
sound_object_list = self.load_all_sound(sound_list)
# *********************场景预置*********************************
print("hide render message")
self.batch_hide_renders(dedumplicate_action)
print("close self default animation")
self.delete_all_default_animation(dedumplicate_action)
print("prepare camera")
target = bpy.data.objects[moudle_name]
print("照相机设置")
self.camera_set(target)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 352
352




 到【灌水乐园】发言
到【灌水乐园】发言









