 openGauss架构、组网、存储及部署方案
openGauss架构、组网、存储及部署方案





系统架构
openGauss是集中式数据库系统,在这样的系统架构中,业务数据存储在单个物理节点上,数据访问任务被推送到服务节点执行,通过服务器的高并发,实现对数据处理的快速响应。同时通过日志复制可以把数据复制到备机,提供数据的高可靠和读扩展。
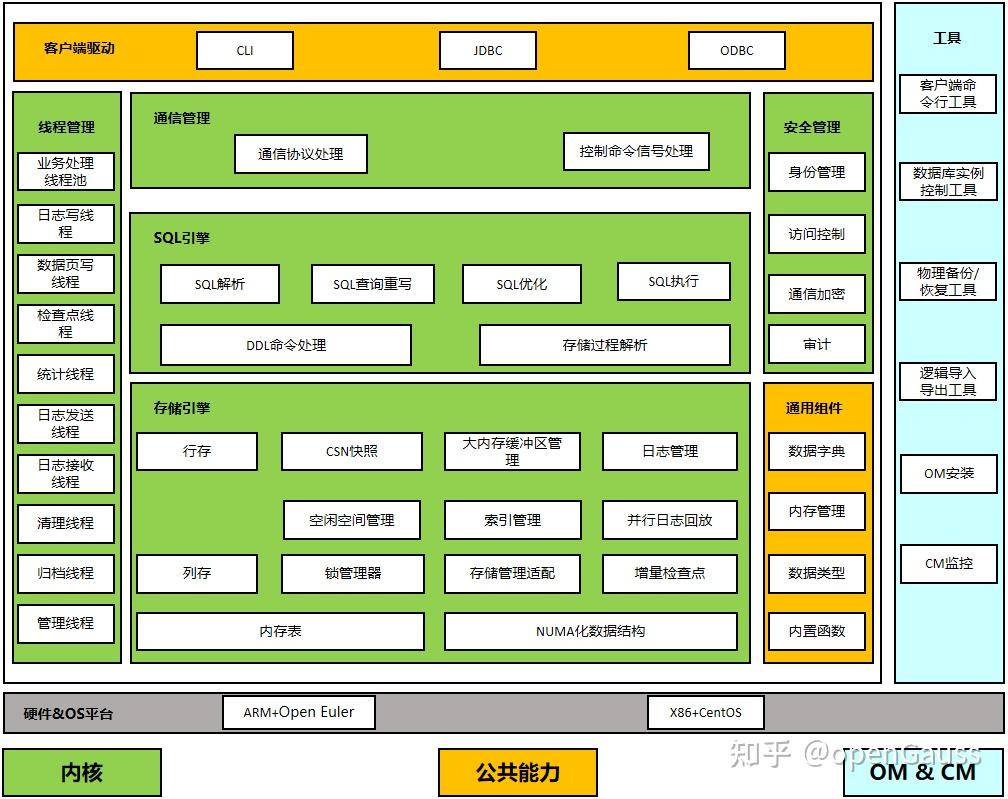
数据库系统架构解释
1. 客户端驱动
- 功能:提供多种接口供用户与数据库交互。
- CLI:命令行工具,适用于直接操作数据库。
- JDBC:Java 应用程序连接数据库的标准接口。
- ODBC:跨平台数据库访问接口,支持多种数据库类型。
2. 线程管理
- 功能:通过多线程处理并行任务,提升系统效率。
- 业务处理线程池:处理用户请求的业务逻辑。
- 日志写线程:负责将事务日志写入磁盘。
- 数据页写线程:管理数据页的持久化。
- 检查点线程:定期创建检查点,减少崩溃恢复时间。
- 清理线程:回收无效数据(如 MVCC 过期版本)。
- 归档线程:管理日志归档,保障数据可恢复性。
3. 通信管理
- 功能:处理客户端与数据库间的通信。
- 通信协议处理:支持标准协议(如 PostgreSQL 协议)。
- 控制命令信号处理:接收并执行管理指令(如启动/停止服务)。
4. SQL 引擎
- 功能:解析、优化并执行 SQL 语句。
- SQL 解析:将 SQL 转换为内部表示。
- SQL 查询重写:优化查询结构(如去重、子查询展开)。
- SQL 优化:生成最优执行计划(如索引选择、连接顺序)。
- DDL 命令处理:执行表结构变更操作(如建表、删列)。
- 存储过程解析:支持复杂业务逻辑的封装。
5. 存储引擎
- 功能:管理数据的存储与访问。
- 行存/列存:支持行式与列式存储,适应 OLTP/OLAP 场景。
- CSN 快照:管理多版本并发控制(MVCC)的快照隔离。
- 大内存缓冲区:缓存热数据,减少磁盘 I/O。
- 锁管理器:协调并发事务的访问冲突。
- 并行日志回放:加速备库数据同步。
- NUMA 优化:针对非统一内存架构的性能调优。
6. 安全管理
- 功能:保障系统安全性。
- 身份管理:用户认证与权限分配。
- 访问控制:限制用户对数据的访问范围。
- 通信加密:SSL/TLS 加密传输数据。
- 审计:记录敏感操作日志,满足合规要求。
7. 通用组件
- 功能:提供基础能力支持。
- 数据字典:存储元数据(如表结构、索引定义)。
- 内存管理:动态分配与回收内存资源。
- 内置函数:支持常用计算(如字符串处理、聚合函数)。
8. 工具
- 功能:辅助数据库运维与管理。
- 物理备份/恢复:全量/增量备份与快速恢复。
- 逻辑导入导出:CSV、JSON 等格式的数据迁移。
- OM 安装:操作维护工具,简化部署流程。
- CM 监控:集群状态监控与告警。
9. 硬件&OS 平台
- 支持:兼容主流软硬件环境。
- ARM + OpenEuler:适配国产化架构与操作系统。
- X86 + CentOS:传统服务器架构支持。
10. 内核
- 功能:核心功能实现层,包括事务管理、并发控制等。
11. 公共能力
- 功能:提供通用服务(如日志、配置管理),供各模块调用。
12. OM & CM
- 功能:管理数据库实例与集群。
- OM(操作维护):实例启停、参数调整。
- CM(集群管理):跨节点资源调度与故障切换。
总结
该架构通过 模块化设计 实现高效协同:
- 客户端驱动 提供多语言接入能力。
- 线程管理 与 通信管理 保障高并发与低延迟。
- SQL 引擎 与 存储引擎 分离计算与存储,适应混合负载。
- 安全管理 与 工具 支持全栈安全与运维自动化。
- 硬件兼容性 与 公共能力 确保灵活部署与扩展。
此设计兼顾 性能、安全性、可维护性,适用于企业级数据库场景。
软件架构

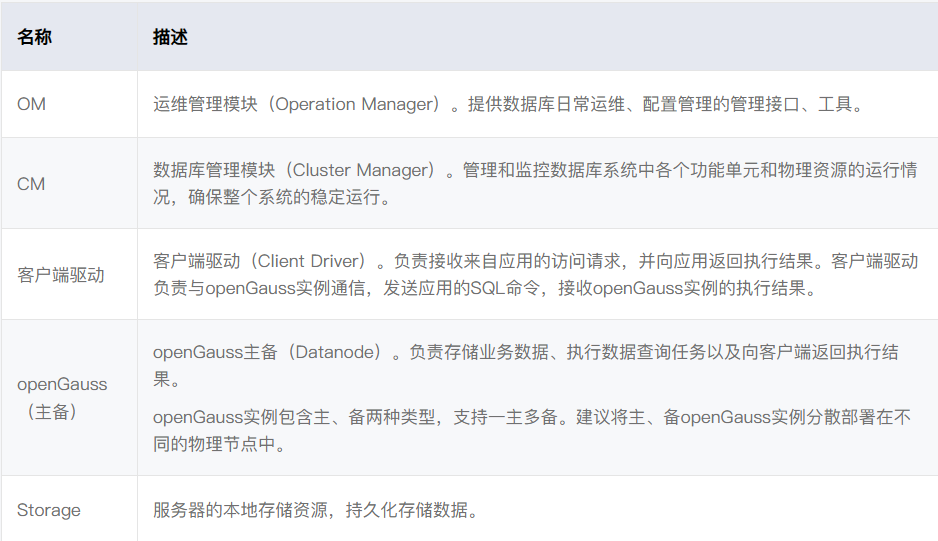
组网
为了保证整个应用数据的安全性,建议将openGauss的典型组网划分为两个独立网络,前端业务网络和数据库管理存储网络。
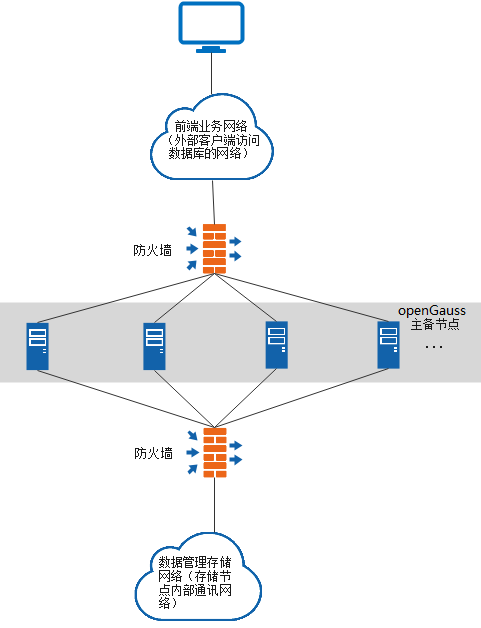
网络划分说明如表1所示。
表 1 网络划分
该典型组网有如下优点:
业务网络与数据库管理存储网络的隔离,有效保护了后端存储数据的安全。
业务网络和数据库管理存储网络的隔离,可以防止攻击者通过互联网试图对数据库服务器进行管理操作,增加了系统安全性。
网络独占性及1:1的带宽收敛比是openGauss数据库网络性能的基本要求。因此,在生产系统中,对图1中的后端存储网络,需满足独占性及至少1:1收敛比的要求。例如,图2中,其本质是Fattree组网方式。为实现收敛比1:1,交换网络层级每提高一层,带宽增加一倍。图中每根加粗连接线代表80GE带宽,即8台物理机带宽上限之和。接入层每单台交换机下行带宽160GE,上行带宽160GE,收敛比1:1;汇聚层每单台交换机接入带宽320GE。
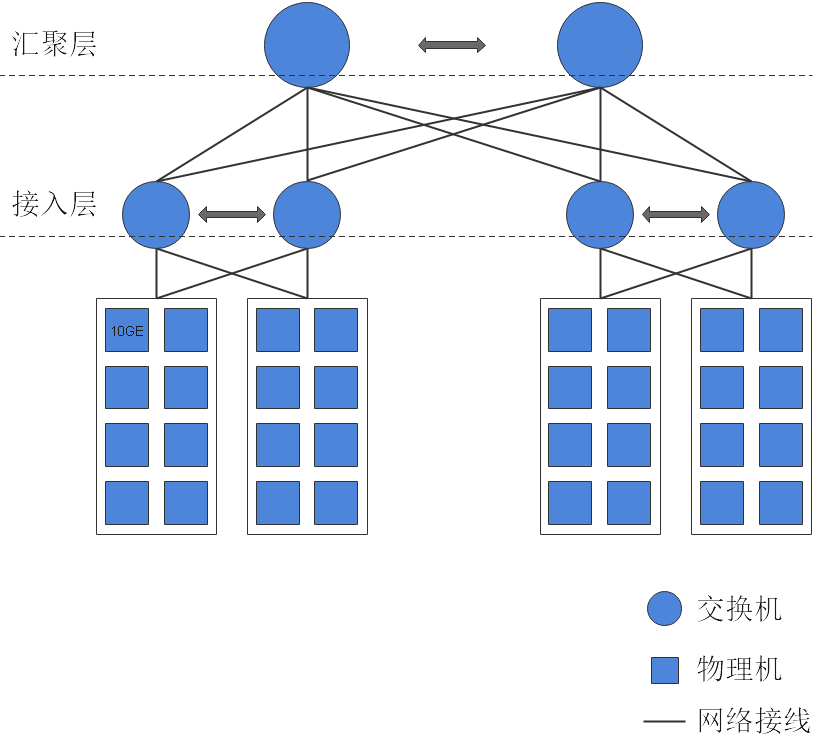
图 2 数据库管理存储网络组网示例
数据库逻辑存储
openGauss的数据库节点负责存储数据,其存储介质也是磁盘,本节主要从逻辑视角介绍数据库节点都有哪些对象,以及这些对象之间的关系。
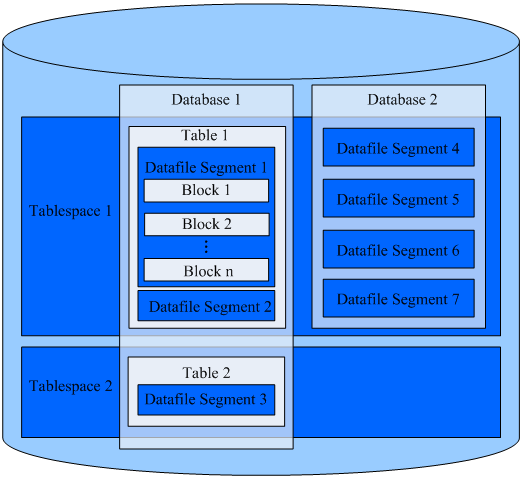
-
Tablespace,即表空间,是一个目录,可以存在多个,里面存储的是它所包含的数据库的各种物理文件。每个表空间可以对应多个Database。
2.Database,即数据库,用于管理各类数据对象,各数据库间相互隔离。数据库管理的对象可分布在多个Tablespace上。
3.Datafile Segment,即数据文件,通常每张表只对应一个数据文件。如果某张表的数据大于1GB,则会分为多个数据文件存储。
4.Table,即表,每张表只能属于一个数据库,也只能对应到一个Tablespace。每张表对应的数据文件必须在同一个Tablespace中。
5.Block,即数据块,是数据库管理的基本单位,默认大小为8KB。
在 openGauss 数据库中,Block(数据块) 是数据库管理的基本单位,默认大小为 8KB。以下是关于 Block 在 openGauss 中的具体解释和相关技术细节:
1. Block 的定义与作用
- 基本单位:
Block 是 openGauss 存储和管理数据的最小逻辑单元,类似于其他数据库中的 “Page” 概念。所有表数据、索引等最终都以 Block 的形式存储在磁盘上。 - 默认大小:
默认情况下,每个 Block 的大小为 8KB。这一设计平衡了存储效率和 I/O 操作性能,适合大多数场景。
2. Block 在存储结构中的角色
(1) 与段页式存储的关联
openGauss 采用 段页式存储(Segmented Paging Storage),其核心概念包括:
- Extent(扩展块):
- 一组连续的物理存储空间,由多个 Block 组成。
- Extent 的大小可以是 64K、1M、8M、64M 等(根据需求动态分配)。
- 例如,一个 64K 的 Extent 包含 8 个 Block(64K / 8KB)。
- Segment(段):
- 一个表的数据存储在多个 Extent 中,每个 Extent 由若干 Block 组成。
- Block 是 Segment 和 Extent 的基础构建单元。
(2) 与行存储/列存储的兼容性
- 行存储引擎(AStore):
- 行存储将每行数据完整地存储在一个 Block 中(或跨多个 Block)。
- Block 内部按行组织数据,适合 OLTP 场景(高并发、低延迟的事务处理)。
- 列存储引擎(CStore):
- 列存储将同一列的数据压缩后存储在 Block 中,适合 OLAP 场景(复杂查询和大规模数据分析)。
- Block 内部按列组织数据,支持高效压缩和快速扫描。
3. Block 的管理机制
(1) Block 的分配与回收
- 动态扩展:
当表数据增长时,openGauss 会按需分配新的 Extent(由多个 Block 组成),并将其添加到表的 Segment 中。- 例如:当 Block 不足时,先分配 64K 的 Extent(8 个 Block),后续可能升级到 1M、8M 等更大尺寸的 Extent。
- 空闲 Block 回收:
删除数据或释放空间时,openGauss 会标记 Block 为可用,并在后续插入操作中重用。
(2) Block 地址映射
- 物理地址:
每个 Block 在磁盘上有唯一的物理地址(文件号 + 偏移量),通过 BMT(Block Map Tree) 记录表中所有 Block 的分布。- BMT 是一个逻辑结构,用于快速定位某个表的数据 Block 在磁盘上的位置。
4. Block 的实际应用
(1) 数据读写
- 读操作:
查询时,openGauss 通过 BMT 定位所需 Block,从磁盘加载到内存进行处理。 - 写操作:
插入/更新数据时,系统分配新的 Block 或复用空闲 Block,并更新 BMT。
(2) 性能优化
- 预取(Prefetching):
根据访问模式,提前将相邻 Block 加载到内存,减少 I/O 延迟。 - 缓存管理:
Block 缓存(Buffer Pool)存储热点 Block,避免频繁磁盘访问。
5. Block 的配置与调整
-
修改 Block 大小:
openGauss 允许通过参数调整 Block 大小(需在初始化实例时指定),例如:gs_initdb -D /data/openGauss --block-size=16384 # 设置 Block 大小为 16KB注意:Block 大小一旦设定,无法动态修改,需谨慎选择。
-
适用场景建议:
- 8KB Block:通用场景,平衡性能和存储效率。
- 16KB Block:适合大字段(如文本、JSON)存储,减少 Block 数量。
- 32KB Block:适用于全闪存存储,优化大 I/O 吞吐。
6. Block 与 WAL 日志的关系
- WAL(Write-Ahead Logging):
- 所有 Block 的修改操作(如更新、删除)会先记录到 WAL 日志中,确保数据持久性和崩溃恢复。
- Block 的物理修改仅在 WAL 日志落盘后执行。
总结
在 openGauss 中,Block 是数据库存储的基石,其默认大小为 8KB,通过段页式存储和 BMT 实现高效管理。无论是行存储还是列存储引擎,Block 都是底层数据组织的核心单元。合理配置 Block 大小和利用 Block 管理机制,能够显著提升数据库性能和存储效率。
常见主备部署方案
单中心
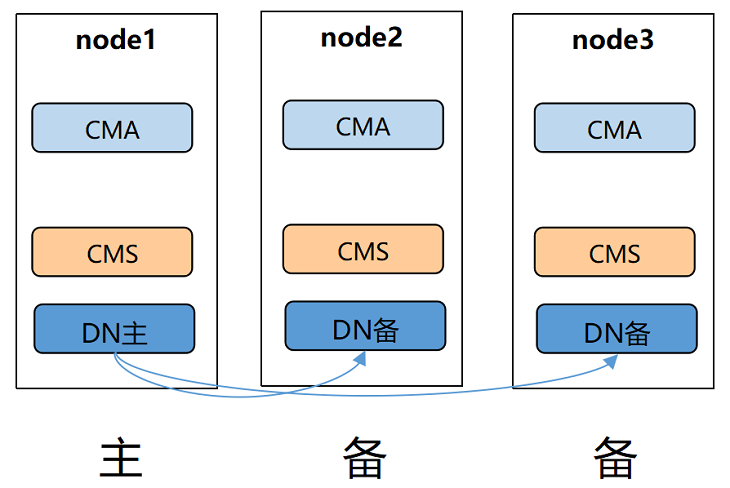
组网特点: 单AZ部署,可以配置一个同步备一个异步备 优势: 1. 三个node完全等价,故障任意一个node都可以提供服务 2. 成本低 劣势: 高可用能力较低,发生AZ级故障只能依赖节点恢复 适用性: 适用于对高可用性要求较低的业务系统
同城双中心
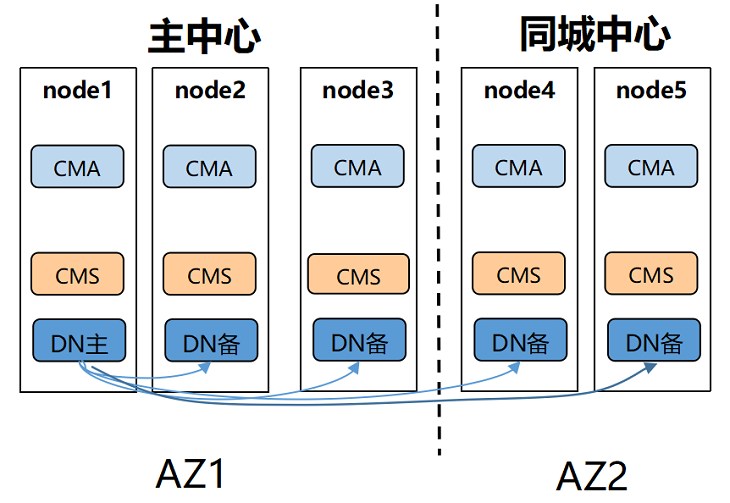
组网特点: 同城两个AZ,相比单AZ可靠性更强,主中心和同城中心可以分别配置一个同步备 优势: 1. 同城同步复制,任意一个中心故障,另一个中心还可以提供服务,数据不丢失,RPO=0 2. 成本适中 劣势: 1. 同城距离不宜太远,一般建议70km以内,业务设计要考虑读写次数过多导致的总延时 2. 不具备异地容灾能力 适用性: 适用于一般业务系
两地三中心
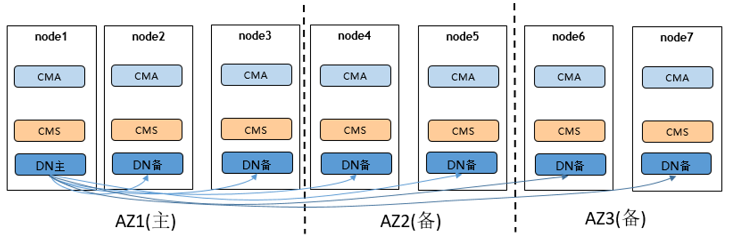
组网特点: 两地三中心,每个AZ都保证至少有一个同步备,同时地点和中心数的增加,集群的可靠性能够达到最高
优势: 具备异地容灾能力,并且能够保证异地容灾数据不丢失,RPO=0,可靠性最强
劣势:
异地距离较远,若在异地中心配置了同步备,可能会影响性能
成本较高
适用性: 适用于核心重要业务系统
两地三中心流式容灾方案
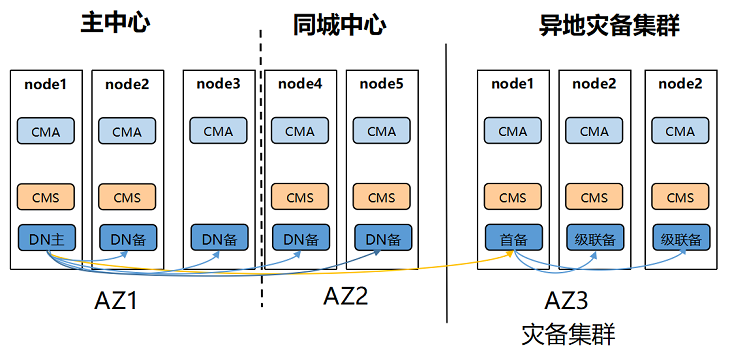
组网特点: 双集群容灾方案,两个独立集群,主备集群组网方式可任意选择,备集群会选出首备连接主集群的主DN,灾备集群内都以级联备方式连接首备
优势:
主集群具备单集群组网的优点,只有主集群彻底不可用后才需要手动切换为备集群
跨集群(异地)复制链路无论是否发生容灾切换都只有一条,占用网络带宽相对较少
组网更加灵活,主集群和灾备集群都可以选择不同的组网
劣势:
需要增加灾备集群,相应增加成本
异地灾备RPO>0
适用性: 适用于核心重要业务系统
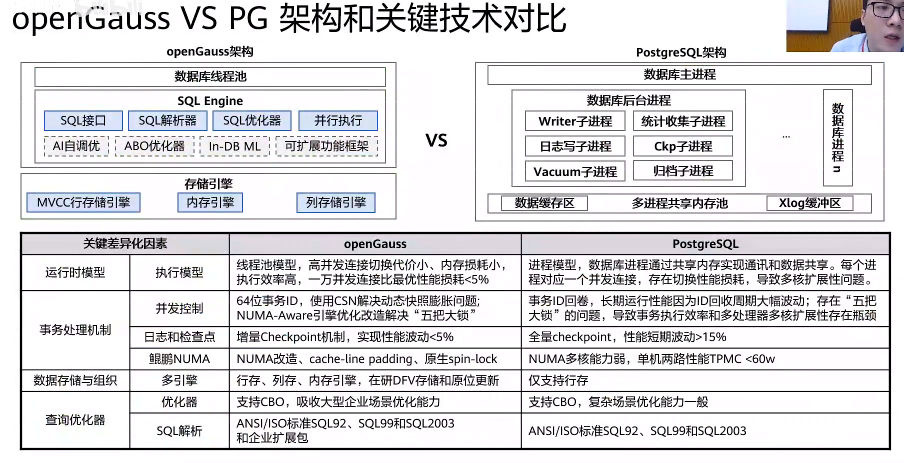
open gauss与pg对比

















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









