







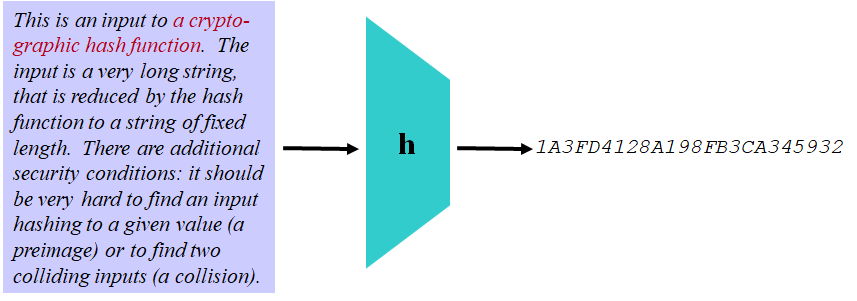
1. Hash函数介绍
Hash,一般翻译做"散列",也有直接音译为"哈希"的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
消息是任意有限长度,哈希值是固定长度。
Hash的概念起源于1956年,Dumey用它来解决symbol table question(符号表问题)。使得数据表的插入、删除、查询操作可以在平均常数时间完成。
2. Hash函数的特点
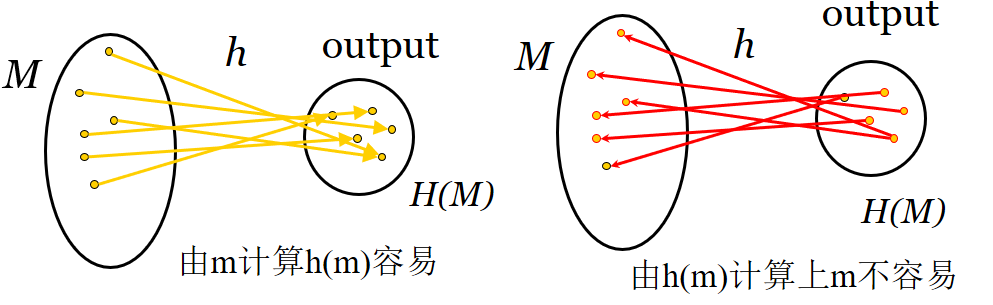
- 单向性(抗原像):对干任意给定的消息,计算其哈希值容易。但是,对于给定的哈希值h,要找到M使得H(M)=h在计算上是不可行的。
-
抗弱碰撞(抗二次原像):对于给定的消息M1,要发现另一个消息M2,满足H( M1 )=H(M2)在计算上是不可行的。
-
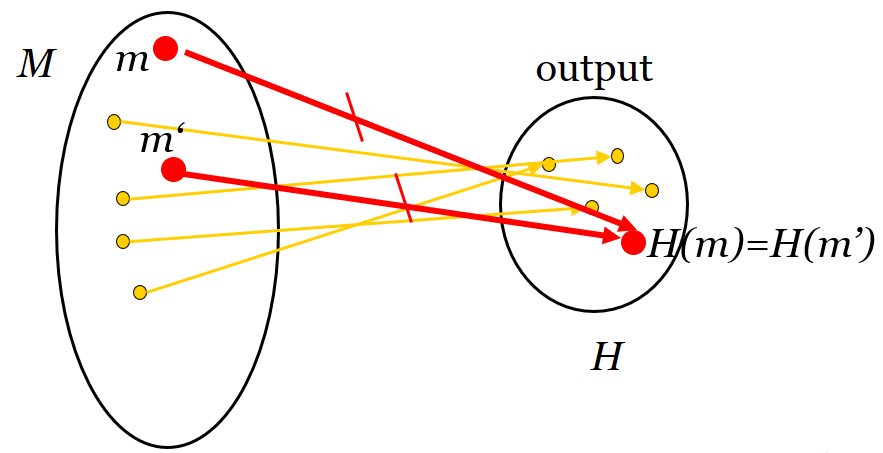
抗强碰撞:找任意一对不同的消息M1,M2 ,使H(M1)=H(M2 )在计算上是不可行的。
- 随机性.
3. SHA-1哈希算法介绍
SHA (Secure Hash Algorithm,译作安全散列算法) 是美国国家安全局 (NSA) 设计,美国国家标准与技术研究院(NIST) 发布的一系列密码散列函数。正式名称为 SHA 的家族第一个成员发布于 1993年。然而人们给它取了一个非正式的名称 SHA-0 以避免与它的后继者混淆。两年之后, SHA-1,第一个 SHA 的后继者发布了。 另外还有四种变体,曾经发布以提升输出的范围和变更一些细微设计: SHA-224, SHA-256, SHA-384 和 SHA-512 (这些有时候也被称做 SHA-2)。
最初载明的算法于1993年发布,称做安全散列标准 (Secure Hash Standard),FIPS PUB 180。这个版本常被称为 “SHA-0”。它在发布之后很快就被NSA撤回,并且以 1995年发布的修订版本 FIPS PUB 180-1 (通常称为 “SHA-1”) 取代。根据 NSA的说法,它修正了一个在原始算法中会降低密码安全性的错误。然而 NSA 并没有提供任何进一步的解释或证明该错误已被修正。1998年,在一次对 SHA-0 的攻击中发现这次攻击并不能适用于 SHA-1 — 我们不知道这是否就是NSA 所发现的错误,但这或许暗示我们这次修正已经提升了安全性。SHA-1已经被公众密码社群做了非常严密的检验而还没发现到有不安全的地方,它在一段时间被认为是安全的,直到Google宣布攻破SHA-1。
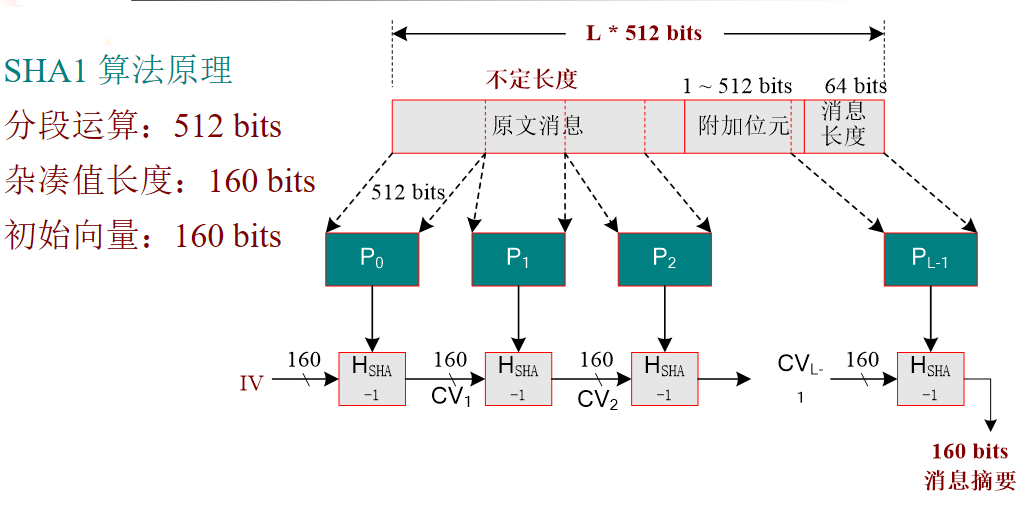
SHA-0 和 SHA-1 会从一个最大 264 位元的讯息中产生一串 160 位元的摘要,然后以设计 MD4 及 MD5 讯息摘要算法的 MIT 教授Ronald L. Rivest类似的原理为基础来加密。
4. SHA-1算法介绍


5. SHA-1算法步骤
- 填充消息:
假设输入消息M,首先应该填充消息,保证输入SHA-1计算的整个消息长度是512bits的倍数。
假设消息的长度为1bits,在原始消息M尾部增加1个比特位"1"和k个"0"比特位,l和k满足l + 1 + k ≡ 512 - 64(mod 512),并且为最小负整数。
然后再在填充消息的末尾添加64-bit的块,该64-bit块是原始消息比特位长度变换为二进制块,如果消息长度变换为二进制块的位个数小于64,则在左边补0,使得块的长度刚好等于64bits。

- 被填充消息分组:
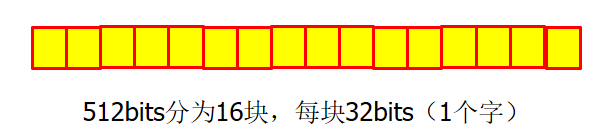
把填充后的整个消息按照512-bit块进行划分,假若刚好划分为N个512-bit块,依次为:M(0),M(1),···,M(N)。而每个512-bit块又可由16个32-bit字组成,第i个512-bit块的第一个32-bit字,记为M0(i),M1(i),···,M15(i)
- 初始化变量:
SHA-1的初值变量IV为160bits的数据块,即5个32-bit的字,依次为H0(0),H1(0),H2(0),H3(0),H4(0),初值变量设置为:
H0(0) = 67452301,
H1(0) = EFCDAB89,
H2(0) = 98BADCFE,
H3(0) = 10325476,
H4(0) = C3D2E1F0
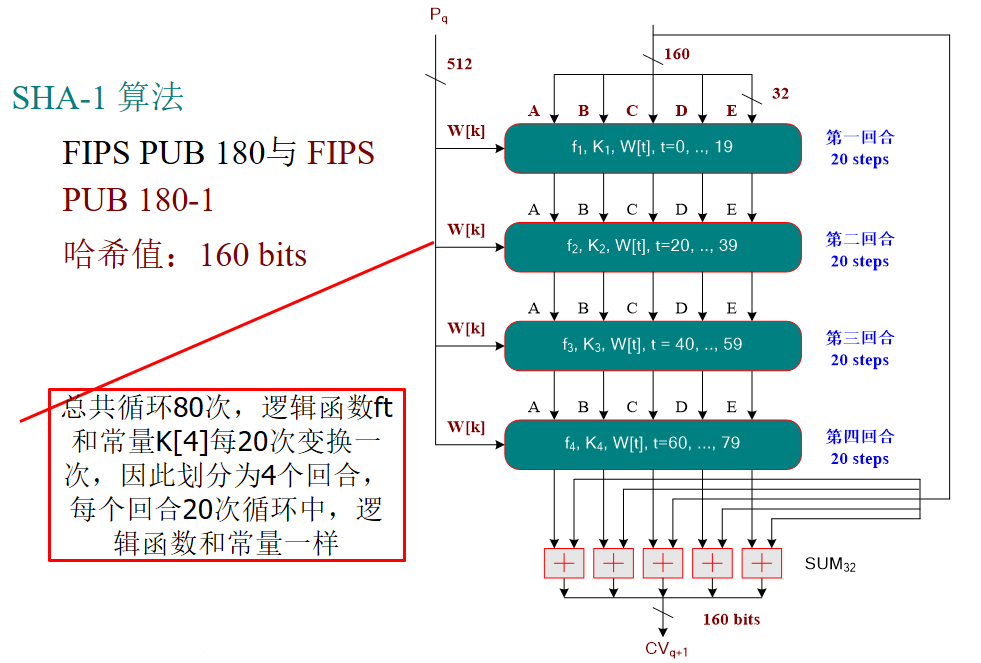
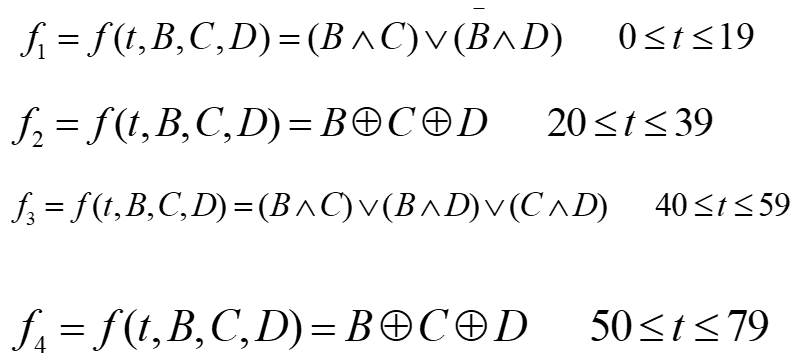
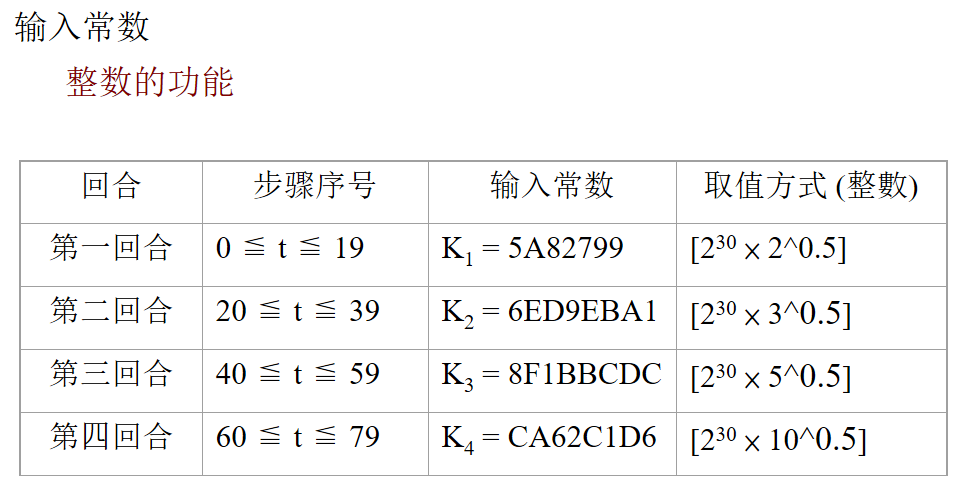
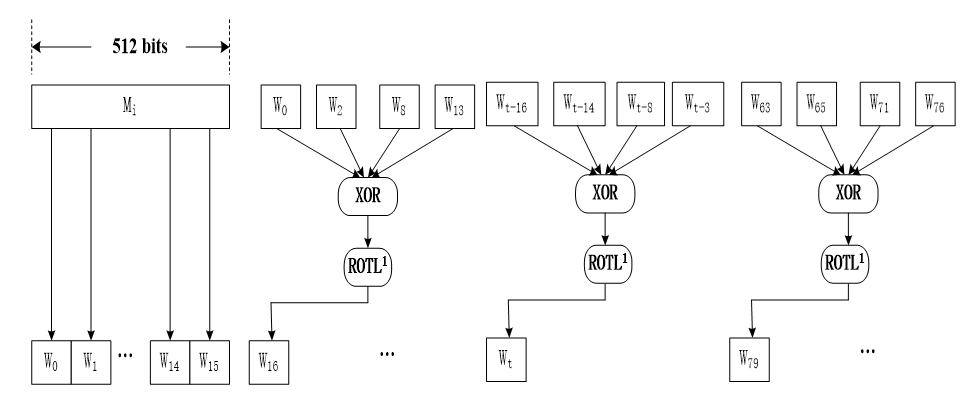
- 数据扩展:
分块处理中还需要使用W[t],t=0,1,···,79。W[t]是由输入512-bit分块通过混合和移动扩充而来。由输入的M(i)分组,分为16个32-bit字M0(i),M1(i),···,M15(i),然后将16个字扩充为80个32-bit字,扩充方法如下:

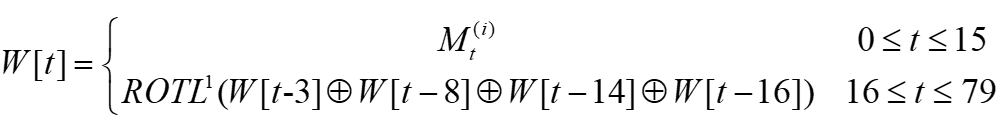
6. 实验内容
按照消息摘要函数SHA-1算法的标准FIPS-180-2的要求,从文件中读取消息,然后对消息分组,并对最后一个分组进行填充,并通过数据扩充算法扩充到80个字。
-
输入为ASCII码,程序的默认输入为FIPS-180-2中示例的“abc”。
-
输出填充后的最后一个分组中的W0, W1,W14 ,W15.然后数据扩充到80个字,然后输出W16, W79 (十六进制)。其中填充过程写成一个函数,数据扩充过程写成一个函数,数据扩充中循环移位也可以写成一个函数。
7. 实现代码
SHA-1的代码官方是有给出的,为了适配实验要求,这是经常修改后的代码,本人菜狗子一个,如果有错误或者不足之处,还望大佬指出。
#include <stdio.h>
#include <string.h>
typedef struct SHA1Context
{
unsigned Message_Digest[5];
unsigned Length_Low;
unsigned Length_High;
unsigned char Message_Block[64];
int Message_Block_Index;
int Computed;
int Corrupted;
} SHA1Context;
#define SHA1CircularShift(bits,word) ((((word) << (bits)) & 0xFFFFFFFF) | ((word) >> (32-(bits))))
void SHA1Reset(SHA1Context *context)
{
context->Length_Low = 0;
context->Length_High = 0;
context->Message_Block_Index = 0;
context->Message_Digest[0] = 0x67452301;
context->Message_Digest[1] = 0xEFCDAB89;
context->Message_Digest[2] = 0x98BADCFE;
context->Message_Digest[3] = 0x10325476;
context->Message_Digest[4] = 0xC3D2E1F0;
context->Computed = 0;
context->Corrupted = 0;
}
void SHA1ProcessMessageBlock(SHA1Context *context)
{
const unsigned K[] =
{
0x5A827999,
0x6ED9EBA1,
0x8F1BBCDC,
0xCA62C1D6
};
int t;
unsigned temp;
unsigned W[80];
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2245
2245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









