




 本文介绍了爬虫的基本原理,包括爬取网页、提取信息、保存数据和自动化程序四个步骤。以东方财富网为例,讲解如何使用Python的requests和BeautifulSoup等库抓取和解析股票数据,最后将数据保存为Excel文件。
本文介绍了爬虫的基本原理,包括爬取网页、提取信息、保存数据和自动化程序四个步骤。以东方财富网为例,讲解如何使用Python的requests和BeautifulSoup等库抓取和解析股票数据,最后将数据保存为Excel文件。
爬虫学习笔记
爬虫的基本原理,分为4个步骤。
爬虫概述
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序。
1.1 爬取网页
爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。源代码包含了网页的部分有用信息,所以只要把源代码获取下载,就可以从中提取想要的信息。可以使用urllib、requests来爬取页面。
例:爬取东方财富网
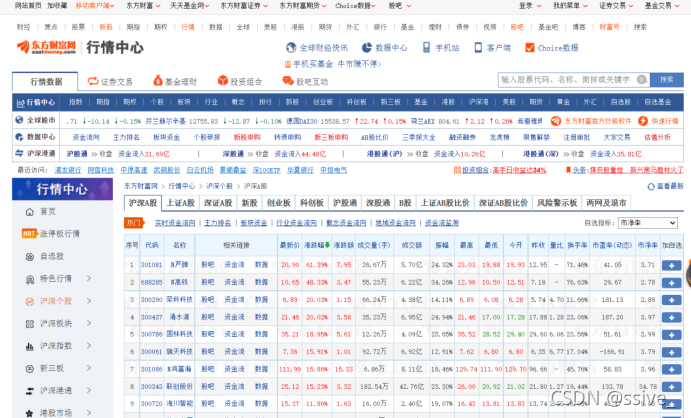
东方财富网的行情中心页面包含了所有股票信息。在左侧的菜单栏中包含了沪深个股、沪深指数等所有股票数据。每个板块的股票数据被隐藏在不同的菜单里。
点击“沪深个股”按钮,对应的股票数据就被查询出来了。上方的选项卡中包含了不同板块的板块:沪深A股、上证A股、深证A股、新股、中小板...
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









