




 本文探讨了1×1卷积在卷积神经网络(CNN)中的核心作用,包括改变通道数量以实现降维/升维、数据融合、减少计算量以及作为非线性操作的组成部分。1×1卷积在googLeNet、ResNet等深度学习模型中发挥关键作用,有助于优化计算效率和提高网络表达能力。
本文探讨了1×1卷积在卷积神经网络(CNN)中的核心作用,包括改变通道数量以实现降维/升维、数据融合、减少计算量以及作为非线性操作的组成部分。1×1卷积在googLeNet、ResNet等深度学习模型中发挥关键作用,有助于优化计算效率和提高网络表达能力。
在论文 Network In Network 中,提出了一个重要的方法:
1×1
1
×
1
卷积。这个方法也在后面比较火的方法,如 googLeNet、ResNet、DenseNet ,中得到了非常广泛的应用。特别是在 googLeNet 的Inception中,发挥的淋漓尽致。
初次看到 1×1 1 × 1 卷积,可能会觉得没有什么作用,因为给人的感觉就是 1×1 1 × 1 的卷积核好像并没有改变什么。但如果对卷积操作有过深入的理解,就会发现并没有那么简单。
这里强调一下,下图只是用了一个卷积核(filter)。下面的 32 是为了匹配上一层的channels,输出的结果只有一个channel。这里如果不理解,可以看我的另一篇博客,【CNN】理解卷积神经网络中的通道 channel。
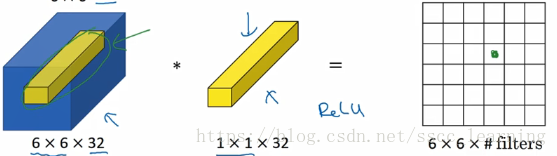
总结了一下其作用,主要分为一下两种:
- 改变通道(channels)
- 降维 / 升维
- 数据融合
- 减少计算量
- 非线性操作
下面详细介绍一下。
改变通道(channels)
之前有详细讲过对 通道 的理解。通过改变 1×1 1 × 1 卷积核的数量来改变输出通道的数量。
降维 / 升维
由于
1×1
1
×
1
并不会改变 height 和 width,改变通道的第一个最直观的结果,就是可以将原本的数据量进行增加或者减少。这里看其他文章或者博客中都称之为升维、降维。但我觉得维度并没有改变,改变的只是 height × width × channels 中的 channels 这一个维度的大小而已。
数据融合
在 ResNet 中,数据要进行相加 ,但有时并不能保证通道大小匹配。这个时候就需要使用 1×1 1 × 1 卷积操作,是数据在各个维度上进行匹配,从何对两个数据进行计算。
减少计算量
在 GoogLeNet 中,Inception中的卷积多数先进行了 1×1 1 × 1 卷积操作,再进行其他卷积操作,这样其实可以减少计算量。某些程度上避免了过拟合。
原因如下。
如果不加入
1×1
1
×
1
而直接使用
5×5
5
×
5
,
就像这样,得到结果。
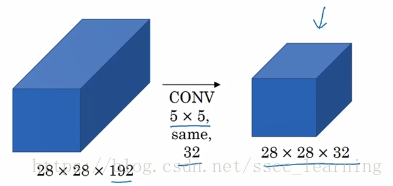
需要计算的量为
大概需要1.3亿次。
而加入了之后,
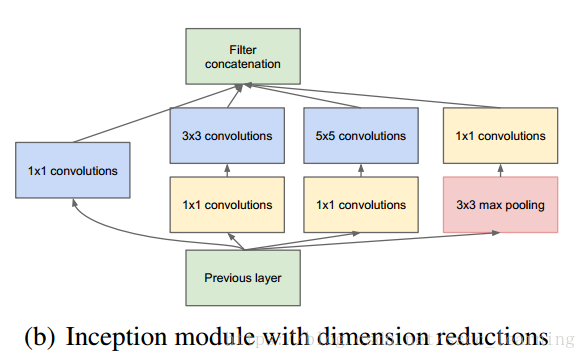

计算量变为
大概在1240万左右。
相比之下,计算量减少了10倍多。
非线性操作
在ResNet中,卷积核进行相关计算后,输出的结果需要经过 ReLU 进行非线性转换 。相当于多进行了一次 ReLU 操作,所以这里也会使整个模型相对更加的复杂,提升网络的表达能力。
一直在学习中,如有错误,请批评指正。
文中图片引自吴恩达老师的 深度学习课程视频 和 GoogLeNet论文 Going Deeper with Convolutions 。


















 4169
4169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









