




 本文分享了五个Hive SQL的企业级优化技巧,包括活用group by以简化计算,巧用cube函数进行多维度聚合,利用lateral view进行行转列处理,优化表连接操作,以及解决数据倾斜问题的方法。这些技巧旨在提高HQL的执行效率和性能。
本文分享了五个Hive SQL的企业级优化技巧,包括活用group by以简化计算,巧用cube函数进行多维度聚合,利用lateral view进行行转列处理,优化表连接操作,以及解决数据倾斜问题的方法。这些技巧旨在提高HQL的执行效率和性能。
Hive SQL 企业级优化技巧
Hive SQL 企业级优化技巧
本文是笔者在日常完成 Hive SQL 业务需求中,总结出一些 HQL 优化技巧,希望能给各位提供一些帮助与启发,文章如有运用不妥之处,敬请谅解。
关于数据倾斜的优化技巧,因为篇幅有限,只会先简要提供解决思路,后边也会更新辅以实际案例的关于数据倾斜原因与具体解决方案。
技巧 1:活用 group by
结合实际的代码块,各位先看以下两段代码
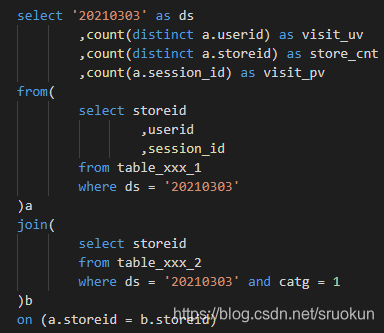
第一段:
第二段:
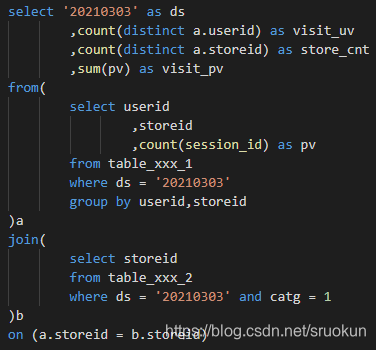
上边代码中,session_id 是作为用户访问一次的会话字段,对比第一段 SQL 代码,明显第二段的计算方式更为简洁,访问次数不用考虑 session_id ,直接对每个用户 group by 后 count(*) 得出每个用户的访问次数,最后在最外层 sum(pv) 得到总的访问次数即可。
同时在进行简单的查询操作时 group by 也能替代 distinct 进行去重,碰到数据量级较大时,可以用这个技巧减少代码运行的时间。
技巧 2:巧用 cube 函数
cube:根据group by 维度的所有组合进行聚合。
具体应用见以下代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









